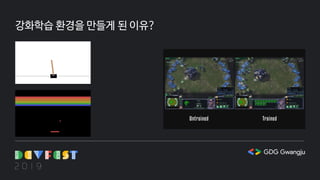
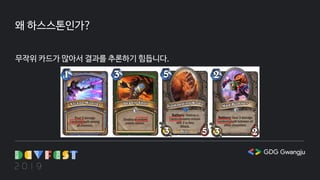
강화학습에 관심을 갖게 되어 어떤 게임에 적용해볼까 고민하다가 평소 즐기던 '하스스톤'이라는 게임에 관심을 갖게 되어 2017년 말부터 하스스톤 강화 학습을 위한 API를 만들기 시작했습니다. 이 발표를 통해 평소 하스스톤과 같은 카드 게임 개발이나 게임에 강화학습을 적용하기 위한 환경을 구축하는데 관심을 갖고 있던 프로그래머들에게 조금이나마 도움이 되었으면 합니다.
발표자 소개
Nexon Korea게임 클라이언트 프로그래머
Microsoft Developer Technologies MVP
페이스북 그룹 C++ Korea 대표
이메일 : utilForever@gmail.com
페이스북, 트위터 : @utilForever
깃허브 : https://github.com/utilForever
개발 목표
강화학습을 통해
영리한플레이를 할 수 있게 만들자. (프로게이머와 대적할 수준)
승률이 높은 덱을 만들어 보자. (1티어 덱보다 높은 승률 : >= 60%)
플레이어가 덱을 만들 때 어떤 카드가 없을 경우,
대체 카드를 추천하는 기능을 만들어 보자.
14.
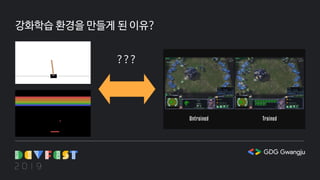
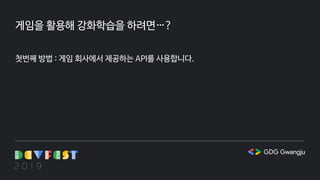
게임을 활용해 강화학습을하려면…?
첫번째 방법 : 게임 회사에서 제공하는 API를 사용합니다.
15.
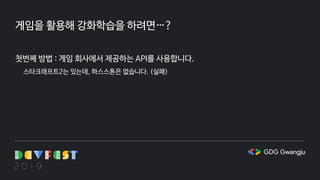
게임을 활용해 강화학습을하려면…?
첫번째 방법 : 게임 회사에서 제공하는 API를 사용합니다.
스타크래프트2는 있는데, 하스스톤은 없습니다. (실패)
16.
게임을 활용해 강화학습을하려면…?
첫번째 방법 : 게임 회사에서 제공하는 API를 사용합니다.
스타크래프트2는 있는데, 하스스톤은 없습니다. (실패)
두번째 방법 : 게임을 후킹(Hooking)해 알아낸 정보를 사용합니다.
18.
게임을 활용해 강화학습을하려면…?
첫번째 방법 : 게임 회사에서 제공하는 API를 사용합니다.
스타크래프트2는 있는데, 하스스톤은 없습니다. (실패)
두번째 방법 : 게임을 후킹(Hooking)해 알아낸 정보를 사용합니다.
서비스 중인 게임에 영향을 주는 행위는 불법입니다. (실패)
19.
게임을 활용해 강화학습을하려면…?
첫번째 방법 : 게임 회사에서 제공하는 API를 사용합니다.
스타크래프트2는 있는데, 하스스톤은 없습니다. (실패)
두번째 방법 : 게임을 후킹(Hooking)해 알아낸 정보를 사용합니다.
서비스 중인 게임에 영향을 주는 행위는 불법입니다. (실패)
세번째 방법 : 하스스톤을 직접 만들어서 사용합니다.
최후의 방법, 대안이 없습니다.
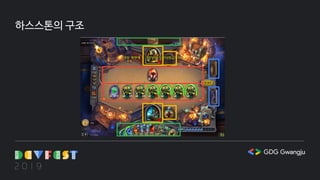
카드 구현
카드 게임에서카드를 구현하지 않는다면 아무런 의미가 없습니다.
카드를 구현할 때 고려해야 할 부분
카드 데이터를 어떻게 구할 것인가
카드 데이터를 어떻게 가져올 것인가
카드 효과를 어떻게 인식할 것인가
23.
카드 데이터 처리
하스스톤에는다양한 카드가 존재하며 서로 다른 데이터를 갖습니다.
모든 카드는 마나 코스트를 갖습니다.
하수인 카드는 공격력과 체력을 갖습니다.
무기 카드는 공격력과 내구도를 갖습니다.
어떤 카드는 어빌리티나 특별한 능력을 갖습니다.
다양한 카드 데이터를 어떻게 가져올 수 있을까요?
카드 효과 처리
하스스톤에는고유한 효과를 갖는 카드가 많습니다.
일부 하수인들은 능력을 발동하려면 조건이 필요합니다.
일부 하수인들은 필드에 낼 때 효과를 발동합니다.
일부 하수인들은 죽을 때 효과를 발동합니다.
비밀은 특정 조건에 부합하는 상황이 일어나면 저절로 발동합니다.
다양한 카드 효과를 어떻게 처리할 수 있을까요?
27.
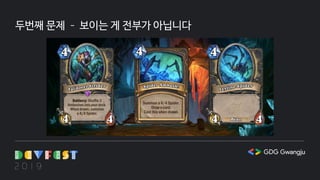
첫번째 문제 –카드 데이터에 효과가 없습니다
{
"id": "EX1_116",
"name": "Leeroy Jenkins",
"text": "Charge. Battlecry: Summon two 1/1 Whelps for your opponent.",
"attack": 6,
"cardClass": "NEUTRAL",
"collectible": true,
"cost": 5,
"health": 2,
"mechanics": ["BATTLECRY", "CHARGE"],
"rarity": "LEGENDARY",
"set": "EXPERT1",
"type": "MINION"
}
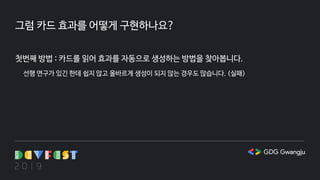
그럼 카드 효과를어떻게 구현하나요?
첫번째 방법 : 카드를 읽어 효과를 자동으로 생성하는 방법을 찾아봅니다.
선행 연구가 있긴 한데 쉽지 않고 올바르게 생성이 되지 않는 경우도 많습니다. (실패)
33.
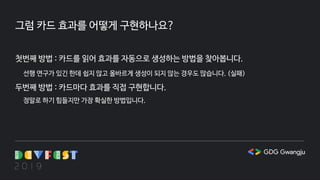
그럼 카드 효과를어떻게 구현하나요?
첫번째 방법 : 카드를 읽어 효과를 자동으로 생성하는 방법을 찾아봅니다.
선행 연구가 있긴 한데 쉽지 않고 올바르게 생성이 되지 않는 경우도 많습니다. (실패)
두번째 방법 : 카드마다 효과를 직접 구현합니다.
정말로 하기 힘들지만 가장 확실한 방법입니다.
하스스톤 강화학습 환경개발
지금까지 우리는 하스스톤 게임을 만들었습니다.
하지만 우리의 목표는 AI가 하스스톤 게임을 하도록 만드는 것입니다.
따라서 AI가 게임을 플레이 할 수 있게 만들어야 합니다.
현재 게임의 상황을 AI에게 전달합니다.
AI가 정책에 따라 어떤 행동을 할 것인지를 결정합니다.
AI가 결정한 행동에 따라 게임을 진행합니다.
38.
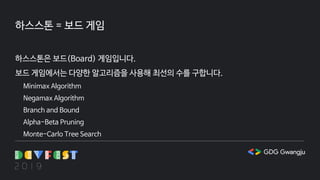
하스스톤 = 보드게임
하스스톤은 보드(Board) 게임입니다.
보드 게임에서는 다양한 알고리즘을 사용해 최선의 수를 구합니다.
Minimax Algorithm
Negamax Algorithm
Branch and Bound
Alpha-Beta Pruning
Monte-Carlo Tree Search
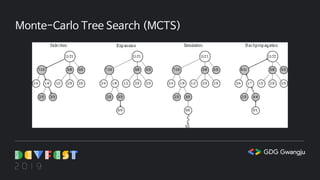
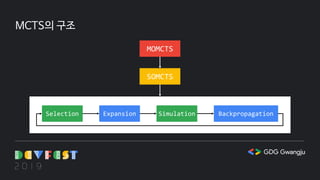
Monte-Carlo Tree Search(MCTS)
몬테카를로 트리 탐색의 4단계
선택(Selection) : 현재 게임 상태가 트리 내에 존재하는 동안 다음에 수행할 행동을 선택합니다.
이 때 활용(Exploitation)과 탐험(Exploration)의 균형을 맞춰 저장된 통계 값에 따라 선택합니다.
확장(Expansion) : 현재 게임 상태가 트리 내에 존재하지 않으면 새로운 노드로 확장합니다.
시뮬레이션(Simulation) : 게임이 끝날 때까지 다음에 수행할 행동을 임의로 선택합니다.
역전파(Backpropagation) : 게임을 실행한 노드부터 루트 노드까지 통계 값을 갱신합니다.
여기서 통계 값이란 총 게임 실행 횟수, 승리 횟수 등을 말합니다.
41.
Monte-Carlo Tree Search(MCTS)
몬테카를로 트리 탐색의 4단계
선택(Selection) : 현재 게임 상태가 트리 내에 존재하는 동안 다음에 수행할 행동을 선택합니다.
이 때 활용(Exploitation)과 탐험(Exploration)의 균형을 맞춰 저장된 통계 값에 따라 선택합니다.
확장(Expansion) : 현재 게임 상태가 트리 내에 존재하지 않으면 새로운 노드로 확장합니다.
시뮬레이션(Simulation) : 게임이 끝날 때까지 다음에 수행할 행동을 임의로 선택합니다.
역전파(Backpropagation) : 게임을 실행한 노드부터 루트 노드까지 통계 값을 갱신합니다.
여기서 통계 값이란 총 게임 실행 횟수, 승리 횟수 등을 말합니다.
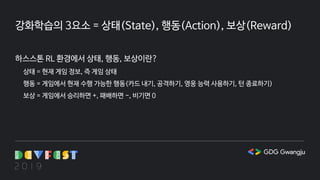
강화학습의 3요소 =상태(State), 행동(Action), 보상(Reward)
하스스톤 RL 환경에서 상태, 행동, 보상이란?
상태 = 현재 게임 정보, 즉 게임 상태
행동 = 게임에서 현재 수행 가능한 행동(카드 내기, 공격하기, 영웅 능력 사용하기, 턴 종료하기)
보상 = 게임에서 승리하면 +, 패배하면 -, 비기면 0
44.
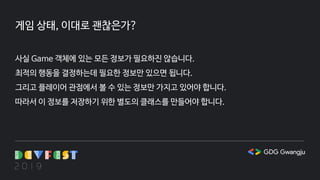
게임 상태, 이대로괜찮은가?
RosettaStone 프로젝트에서는 Game 클래스를 통해 하나의 게임을 관리합니다.
두 플레이어의 정보, 게임과 관련된 정보, 기타 필요한 변수들을 저장하고 있습니다.
따라서 Game 객체 하나의 크기는 약 1,000바이트로 상당히 큽니다.
MCTS는 트리의 각 노드에 게임의 상태를 저장합니다.
하지만 Game 객체의 크기가 크다 보니 메모리 공간의 낭비가 심합니다.
뭔가 좋은 방법이 없을까요?
46.
게임 상태, 이대로괜찮은가?
사실 Game 객체에 있는 모든 정보가 필요하진 않습니다.
최적의 행동을 결정하는데 필요한 정보만 있으면 됩니다.
그리고 플레이어 관점에서 볼 수 있는 정보만 가지고 있어야 합니다.
따라서 이 정보를 저장하기 위한 별도의 클래스를 만들어야 합니다.
47.
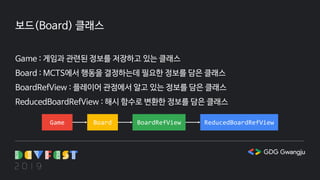
보드(Board) 클래스
Game :게임과 관련된 정보를 저장하고 있는 클래스
Board : MCTS에서 행동을 결정하는데 필요한 정보를 담은 클래스
BoardRefView : 플레이어 관점에서 알고 있는 정보를 담은 클래스
ReducedBoardRefView : 해시 함수로 변환한 정보를 담은 클래스
Game Board BoardRefView ReducedBoardRefView
48.
신경망 모델 구현
PyTorch(https://pytorch.org/)
Python 기반의 오픈 소스 머신 러닝 라이브러리입니다.
C++ API(libtorch)와 Python API를 동시 지원합니다.
C++ 기반의 머신러닝 모델 설계에 용이합니다.
하스스톤의 강화학습 환경을 구성하기 위해 libtorch를 사용했습니다.
현재 CNN 기반의 모델을 사용하고 있습니다.
torch::Tensor CNNModel::forward(torch::Tensor hero,torch::Tensor minion,
torch::Tensor standalone) {
// Input shape : (2), (7, 14), (17,)
// Output shape : (1)
// Encodes the information of heros
auto outHero = EncodeHero(hero);
// Encodes the information of minions
auto outMinion = EncodeMinion(minion);
// Encodes the information of 'standalone'
auto outStandalone = EncodeStandalone(standalone);
auto concatFeatures = torch::cat({ outHero, outMinion, outStandalone }, -1);
concatFeatures = m_fc1->forward(concatFeatures);
concatFeatures = torch::leaky_relu(concatFeatures, .2);
concatFeatures = m_fc2->forward(concatFeatures);
concatFeatures = torch::tanh(concatFeatures);
return concatFeatures;
}
52.
AlphaZero 구현 (진행중)
오랜시간에 걸쳐 강화학습을 하기 위해 수많은 코드를 구현했습니다.
이제 정말로 강화학습을 구현할 차례입니다. 여기서는 AlphaZero를 구현합니다.
알파제로를 사용하면 하스스톤 리플레이 데이터가 없어도
자체 학습만으로 게임 플레이를 더 잘하게 만들 수 있습니다.
53.
Python API 지원(진행중)
많은 사람들은 Tensorflow나 PyTorch를 사용해 강화학습 모델을 만듭니다.
비록 libtorch의 성능이 훨신 뛰어나지만 편의성 측면에서는 한계가 있습니다.
저희는 많은 사람들이 새로운 환경에서 연구하기를 원합니다.
따라서 Python API를 지원하기로 결정했습니다.
프로젝트 구조
RosettaStone :하스스톤 시뮬레이터 라이브러리
RosettaTorch : 강화학습과 관련된 코드를 구현하는 라이브러리
RosettaConsole : 하스스톤 게임을 해볼 수 있는 콘솔 프로그램
UnitTests : 카드 효과 및 동작을 테스트하는 프로그램
MCTSTests, AlphaZeroTests : MCTS 및 AlphaZero 동작을 테스트하는 프로그램
56.
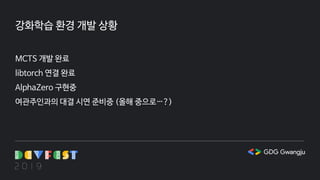
강화학습 환경 개발상황
MCTS 개발 완료
libtorch 연결 완료
AlphaZero 구현중
여관주인과의 대결 시연 준비중 (올해 중으로…?)
57.
앞으로의 계획
모든 카드를구현할 예정입니다.
우선적으로 오리지널 카드와 정규전에서 사용하는 카드를 구현합니다.
이후 야생전에서 사용하는 카드를 차례대로 구현할 예정입니다.
콘솔 및 GUI 프로그램을 개선해 AI와 대전할 수 있게 만들 예정입니다.
다른 언어에서 사용할 수 있도록 API를 제공할 예정입니다.
우선적으로 Python을 생각하고 있습니다.
감사의 말
RosettaStone 및다른 RL 환경 개발 프로젝트에 함께 참여하고 있는
한양대학교 소프트웨어학부 학생들
경기과학고등학교 학생들
언급하지 못한 다른 모든 팀원 분들
에게 감사의 말씀을 드립니다.
함께 사이드 프로젝트를 진행할 분들을 언제나 기다리고 있습니다.







![HearthstoneJSON (https://hearthstonejson.com/)
{
"id": "EX1_116",
"name": "Leeroy Jenkins",
"text": "Charge. Battlecry: Summon two 1/1 Whelps for your opponent.",
"attack": 6,
"cardClass": "NEUTRAL",
"collectible": true,
"cost": 5,
"health": 2,
"mechanics": ["BATTLECRY", "CHARGE"],
"rarity": "LEGENDARY",
"set": "EXPERT1",
"type": "MINION"
}](https://image.slidesharecdn.com/gdggwangjudevfest2019-hearthstonerlenvironment-191119135400/85/GDG-Gwangju-DevFest-2019-25-320.jpg)

![첫번째 문제 – 카드 데이터에 효과가 없습니다
{
"id": "EX1_116",
"name": "Leeroy Jenkins",
"text": "Charge. Battlecry: Summon two 1/1 Whelps for your opponent.",
"attack": 6,
"cardClass": "NEUTRAL",
"collectible": true,
"cost": 5,
"health": 2,
"mechanics": ["BATTLECRY", "CHARGE"],
"rarity": "LEGENDARY",
"set": "EXPERT1",
"type": "MINION"
}](https://image.slidesharecdn.com/gdggwangjudevfest2019-hearthstonerlenvironment-191119135400/85/GDG-Gwangju-DevFest-2019-27-320.jpg)




![GameConfig gameConfig;
gameConfig.player1Class = CardClass::WARLOCK;
gameConfig.player2Class = CardClass::WARLOCK;
gameConfig.startPlayer = PlayerType::PLAYER1;
gameConfig.doShuffle = false;
gameConfig.doFillDecks = false;
gameConfig.skipMulligan = true;
gameConfig.autoRun = true;
const std::string INNKEEPER_EXPERT_WARLOCK =
"AAEBAfqUAwAPMJMB3ALVA9AE9wTOBtwGkgeeB/sHsQjCCMQI9ggA";
auto deck = DeckCode::Decode(INNKEEPER_EXPERT_WARLOCK).GetCardIDs();
for (size_t j = 0; j < deck.size(); ++j)
{
gameConfig.player1Deck[j] = *Cards::FindCardByID(deck[j]);
gameConfig.player2Deck[j] = *Cards::FindCardByID(deck[j]);
}
Game game(gameConfig);
game.Start();
EXPECT_EQ(game.state, State::COMPLETE);
EXPECT_TRUE(game.GetPlayer1()->playState == PlayState::WON ||
game.GetPlayer1()->playState == PlayState::LOST);
EXPECT_TRUE(game.GetPlayer2()->playState == PlayState::WON ||
game.GetPlayer2()->playState == PlayState::LOST);](https://image.slidesharecdn.com/gdggwangjudevfest2019-hearthstonerlenvironment-191119135400/85/GDG-Gwangju-DevFest-2019-36-320.jpg)
























![[NDC 2019] 하스스톤 강화학습 환경 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc19hearthstonedevelopmentforreinforcementlearningverfinal-190426141251-thumbnail.jpg?width=640&height=640&fit=bounds)
![[RLKorea] <하스스톤> 강화학습 환경 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/rlkorea-hearthstonesimulationforreinforcementlearningver1-190826145318-thumbnail.jpg?width=640&height=640&fit=bounds)
![[NDC2016] 신경망은컨텐츠자동생성의꿈을꾸는가](https://cdn.slidesharecdn.com/ss_thumbnails/random-160427135746-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IGC] 엔씨소프트 이경종 - 강화 학습을 이용한 NPC AI 구현](https://cdn.slidesharecdn.com/ss_thumbnails/igcnpcai20161007-161010052405-thumbnail.jpg?width=640&height=640&fit=bounds)
![[Paper Review] Improving Heartstone AI by Learning High-Level Rollout Policie...](https://cdn.slidesharecdn.com/ss_thumbnails/random-171116075736-thumbnail.jpg?width=640&height=640&fit=bounds)







![Game AI 기초 [ 유니티 및 C# 스터디 / 2024-03-22 ]](https://cdn.slidesharecdn.com/ss_thumbnails/gameai-240419094501-6a3e583d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IGC2018] 엔씨소프트 이경종 - 심층강화학습을 활용한 프로게이머 수준의 AI 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/11-181023083452-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[델리만주] 대학원 캐슬 - 석사에서 게임 프로그래머까지](https://cdn.slidesharecdn.com/ss_thumbnails/asdf-190219141801-thumbnail.jpg?width=640&height=640&fit=bounds)


![[NDC 2018] 유체역학 엔진 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/ndc18fluidenginedevelopmentverfinal-180427164620-thumbnail.jpg?width=640&height=640&fit=bounds)


![[9XD] Introduction to Computer Graphics](https://cdn.slidesharecdn.com/ss_thumbnails/introductiontocomputergraphics-170415035926-thumbnail.jpg?width=640&height=640&fit=bounds)