다이나믹 프로그래밍과 강화학습의차이점
다이나믹 프로그래밍
환경의 모델이 필요
(환경의 모델이란? 상태변환확률과 보상)
정책평가
정책 이터레이션(정책평가 + 정책발전)
환경에 대한 정확한 지식을 가지고
모든 상태에 대해 동시에 계산
강화학습
환경의 모델이 불필요
예측
제어(예측과 함께 정책을 발전)
일단 해보고, 자신을 평가하며,
평가한 대로 자신을 업데이트
이것을 반복
10.
다이나믹 프로그래밍과 강화학습의차이점
다이나믹 프로그래밍
환경의 모델이 필요
(환경의 모델이란? 상태변환확률과 보상)
정책평가
정책 이터레이션(정책평가 + 정책발전)
환경에 대한 정확한 지식을 가지고
모든 상태에 대해 동시에 계산
강화학습
환경의 모델이 불필요
예측
제어(예측과 함께 정책을 발전)
일단 해보고, 자신을 평가하며,
평가한 대로 자신을 업데이트
이것을 반복
몬테카를로 예측(Monte-Carlo Prediction)
스텝사이즈를크게 잡으면 수렴하지 못하며 너무 작으면 수렴의 속도가 느립니다.
Learning rate와 같은 원리라고 생각하시면 편합니다.
𝑉 𝑠 ← 𝑉(𝑠) + 𝑎(𝐺 𝑠 − 𝑉 𝑠 ) - 몬테카를로 예측에서 가치함수 업데이트의 일반식
𝑉 𝑠 ← 𝑉(𝑠) +
1
𝑛
(𝐺 𝑠 − 𝑉 𝑠 ) - 몬테카를로 예측에서 가치함수의 업데이트 식
스텝사이즈(StepSize)로서 업데이트할 때
오차의 얼마를 가지고 업데이트할지 정하는 것
오차
19.
몬테카를로 예측(Monte-Carlo Prediction)
𝑉𝑠 ← 𝑉(𝑠) + 𝑎(𝐺 𝑠 − 𝑉 𝑠 )
정리!
몬테카를로 예측은 샘플링을 평균하여 가치함수를 추정합니다.
1. 𝐺 𝑠 = 업데이트 목표
2. 𝑎(𝐺 𝑠 − 𝑉 𝑠 ) = 업데이트의 크기
몬테카를로 예측에서 에이전트는 이 업데이트 식을 통해
에피소드 동안 경험했던 모든 상태에 대해 가치함수를 업데이트합니다.
가치함수의 업데이트를 통해 다음 두 가지를 알 수 있습니다.
20.
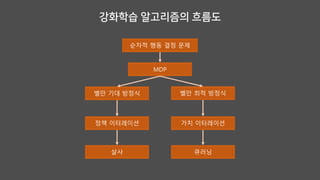
2. 강화학습의 탄생
방법은두 가지
몬테카를로 예측(Monte-Carlo Prediction)
시간차 예측(Temporal-Difference Prediction)
시간차 예측(Temporal-Difference Prediction)
따라서에피소드가 아니라 타임스텝마다 가치함수를 업데이트 해야합니다.
이것이 바로 ‘시간차 예측(Temporal-Difference Prediction)’ 입니다.
시간차 예측에서의 가치함수의 업데이트는 실시간으로 이뤄지며,
몬테카를로 예측과는 달리 한 번에 하나의 가치함수만 업데이트합니다.
시간차 예측(Temporal-Difference Prediction)
𝑣𝜋 𝑠 = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠] - 가치함수의 정의
𝑉(𝑆𝑡) ← 𝑉(𝑆𝑡) + 𝑎(𝑅𝑡+1 + 𝛾𝑉(𝑆𝑡+1) − 𝑉(𝑆𝑡))
- 시간차 예측에서 가치함수의 업데이트
시간차 에러(Temporal-Difference Error, TD Error)
가치함수의 정의를 이용하여 𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)을 기댓값을 계산하지 않고
샘플링을 평균하여 가치함수를 추정합니다.
25.
시간차 예측(Temporal-Difference Prediction)
몬테카를로예측에서는 반환값(𝐺 𝑠 )을 통해 업데이트를 합니다.
하지만 시간차 예측에서는 반환값과는 달리 실제의 값이 아닙니다.
𝑉(𝑆𝑡) ← 𝑉(𝑆𝑡) + 𝑎(𝑅𝑡+1 + 𝛾𝑉(𝑆𝑡+1) − 𝑉(𝑆𝑡))
𝑉 𝑠 ← 𝑉(𝑠) + 𝑎(𝐺 𝑠 − 𝑉 𝑠 ) - 몬테카를로 예측에서 가치함수 업데이트
에이전트는 𝑅𝑡+1 + 𝛾𝑉(𝑆𝑡+1)에 있는 현재 에이전트가 가지고 있는 값(𝑉(𝑆𝑡+1))을
𝑆𝑡+1의 ‘가치함수일 것이라고 예측을 하는 것’ 입니다.
즉, 업데이트 목표도 정확하지 않은 상황에서 가치함수를 업데이트하는 것인데,
이것을 부트스트랩(Bootstrap)이라고 합니다.
- 시간차 예측에서 가치함수의 업데이트
26.
시간차 예측(Temporal-Difference Prediction)
정리!
시간차예측도 마찬가지로 샘플링을 평균하여 가치함수를 추정합니다.
하지만 몬테카를로 예측과 다른 점은 실시간으로 이루어진다는 점입니다.
1. 𝑅𝑡+1 + 𝛾𝑉(𝑆𝑡+1) = 업데이트 목표
2. 𝑎(𝑅𝑡+1 + 𝛾𝑉(𝑆𝑡+1) − 𝑉(𝑆𝑡)) = 업데이트의 크기
시간차 예측은 에피소드가 끝날 때까지 기다릴 필요 없이
바로 가치함수를 업데이트할 수 있습니다.
가치함수의 업데이트를 통해 다음 두 가지를 알 수 있습니다.
𝑉(𝑆𝑡) ← 𝑉(𝑆𝑡) + 𝑎(𝑅𝑡+1 + 𝛾𝑉(𝑆𝑡+1) − 𝑉(𝑆𝑡))
시간차 제어의 근원
정책이터레이션(GPI)
벨만 기대 방정식
정책 평가(기댓값) + 탐욕 정책 발전(argmax)
별도의 정책 사용
가치 이터레이션
벨만 최적 방정식
행동 가치함수(max)
별도의 정책 X
(GPI란 Generalized Policy Iteration으로써, 정책 평가와 정책 발전을
한 번씩 번갈아 가며 진행하는 정책 이터레이션입니다.)
30.
시간차 제어의 근원
정책이터레이션(GPI)
벨만 기대 방정식
정책 평가(기댓값) + 탐욕 정책 발전(argmax)
별도의 정책 사용
가치 이터레이션
벨만 최적 방정식
행동 가치함수(max)
별도의 정책 X
노란색 글씨는 시간차 제어에 쓰이는 요소들
31.
시간차 제어의 근원
정책이터레이션(GPI)
벨만 기대 방정식
정책 평가(기댓값)
탐욕 정책 발전(argmax)
별도의 정책 사용
시간차 제어
벨만 기대 방정식
시간차 예측
탐욕 정책(argmax)
별도의 정책 X
32.
시간차 제어의 근원
정책이터레이션(GPI)
벨만 기대 방정식
정책 평가(기댓값)
탐욕 정책 발전(argmax)
별도의 정책 사용
시간차 제어
벨만 기대 방정식
시간차 예측
탐욕 정책(argmax)?
별도의 정책 X
시간차 제어의 탐욕정책
정책 이터레이션(GPI)의 탐욕 정책 발전
𝜋` 𝑠 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴[𝑅 𝑠
𝑎 + 𝛾𝑃𝑠𝑠`
𝑎
𝑉 𝑠` ]
35.
시간차 제어의 탐욕정책
정책 이터레이션(GPI)의 탐욕 정책 발전
시간차 제어(살사)의 큐함수를 사용한 탐욕 정책
𝜋` 𝑠 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴[𝑅 𝑠
𝑎
+ 𝛾𝑃𝑠𝑠`
𝑎
𝑉 𝑠` ]
𝜋 𝑠 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴 𝑄(𝑠, 𝑎)
탐욕 정책에서 다음 상태의 가치함수를 보고 판단하는 것이 아니고
현재 상태의 큐함수를 보고 판단한다면 환경의 모델을 몰라도 됩니다.
따라서 앞으로 큐함수에 따라 행동을 선택할 것입니다.
살사의 𝜀 –탐욕정책
계속 탐욕 정책만 할 경우, 초기의 에이전트가 학습을 잘 할까요?
살사의 큐함수를 사용한 탐욕 정책
𝜋 𝑠 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴 𝑄(𝑠, 𝑎)
40.
살사의 𝜀 –탐욕정책
에이전트에게는 충분한 경험이 필요합니다.
더 좋은 길이 있을 수도 있기 때문에
가보지 않은 길도 가야할 필요가 있습니다.
즉, 탐험(Exploration)의 문제가 발생합니다.
41.
살사의 𝜀 –탐욕정책
Exploitation
내가 현재 있는 값을 이용한다.
Exploration
한 번 모험한다. 도전한다.
+
42.
살사의 𝜀 –탐욕정책
Exploitation + Exploration = 𝜀 –탐욕 정책
𝜋 𝑠 = ቊ
𝑎∗ = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴 𝑄 𝑠, 𝑎 , 1 − 𝜀
𝑎 ≠ 𝑎∗ , 𝜀
𝜀 의 확률로 무작위 행동을 선택
43.
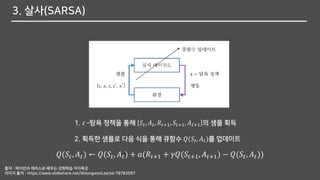
3. 살사(SARSA)
정리!
살사는 GPI의정책 평가를 큐함수를 이용한 시간차 예측으로,
탐욕 정책 발전을 𝜀 –탐욕 정책으로 변화시킨 강화학습 알고리즘입니다.
살사(시간차 제어)의 특징
1. 벨만 기대 방정식을 이용
2. 𝜀 –탐욕 정책 + 시간차 예측(벨만 기대 방정식)
3. 별도의 정책 X
4. 𝑆𝑡, 𝐴 𝑡, 𝑅𝑡+1, 𝑆𝑡+1, 𝐴 𝑡+1 의 샘플을 사용
5. 가치함수가 아닌 큐함수에 따라 행동을 선택
44.
3. 살사(SARSA)
1. 𝜀–탐욕 정책을 통해 𝑆𝑡, 𝐴 𝑡, 𝑅𝑡+1, 𝑆𝑡+1, 𝐴 𝑡+1 의 샘플 획득
2. 획득한 샘플로 다음 식을 통해 큐함수 𝑄(𝑆𝑡, 𝐴 𝑡)를 업데이트
𝑄(𝑆𝑡, 𝐴 𝑡) ← 𝑄(𝑆𝑡, 𝐴 𝑡) + 𝑎(𝑅𝑡+1 + 𝛾𝑄(𝑆𝑡+1, 𝐴 𝑡+1) − 𝑄(𝑆𝑡, 𝐴 𝑡))
출처 : 파이썬과 케라스로 배우는 강화학습 저자특강
이미지 출저 : https://www.slideshare.net/WoongwonLee/ss-78783597
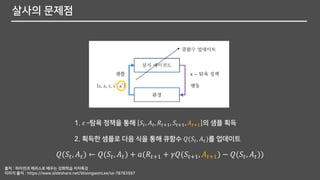
살사의 문제점
1. 𝜀–탐욕 정책을 통해 𝑆𝑡, 𝐴 𝑡, 𝑅𝑡+1, 𝑆𝑡+1, 𝐴 𝑡+1 의 샘플 획득
2. 획득한 샘플로 다음 식을 통해 큐함수 𝑄(𝑆𝑡, 𝐴 𝑡)를 업데이트
𝑄(𝑆𝑡, 𝐴 𝑡) ← 𝑄(𝑆𝑡, 𝐴 𝑡) + 𝑎(𝑅𝑡+1 + 𝛾𝑄(𝑆𝑡+1, 𝐴 𝑡+1) − 𝑄(𝑆𝑡, 𝐴 𝑡))
출처 : 파이썬과 케라스로 배우는 강화학습 저자특강
이미지 출저 : https://www.slideshare.net/WoongwonLee/ss-78783597
48.
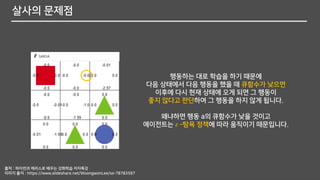
살사의 문제점
살사는 온폴리시시간자 제어(On-Policy Temporal-Difference Control)
즉, 자신이 행동하는 대로 학습하는 시간차 제어
49.
살사의 문제점
행동하는 대로학습을 하기 때문에
다음 상태에서 다음 행동을 했을 때 큐함수가 낮으면
이후에 다시 현재 상태에 오게 되면 그 행동이
좋지 않다고 판단하여 그 행동을 하지 않게 됩니다.
왜냐하면 행동 a의 큐함수가 낮을 것이고
에이전트는 𝜀 –탐욕 정책에 따라 움직이기 때문입니다.
출처 : 파이썬과 케라스로 배우는 강화학습 저자특강
이미지 출저 : https://www.slideshare.net/WoongwonLee/ss-78783597
50.
살사의 문제점
하지만 탐험(Exploration)은강화학습에서 중요한 역할입니다.
따라서 탐험을 위해서 사용하는 것이 바로
오프폴리시 시간차 제어(Off-Policy Temporal-Difference Control)
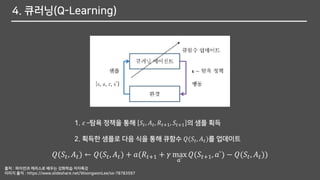
그 중에서 가장 유명한 것이 바로 큐러닝(Q-Learning)입니다.
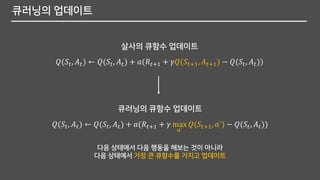
큐러닝의 업데이트
다음 상태에서다음 행동을 해보는 것이 아니라
다음 상태에서 가장 큰 큐함수를 가지고 업데이트
𝑄(𝑆𝑡, 𝐴 𝑡) ← 𝑄(𝑆𝑡, 𝐴 𝑡) + 𝑎(𝑅𝑡+1 + 𝛾𝑄(𝑆𝑡+1, 𝐴 𝑡+1) − 𝑄(𝑆𝑡, 𝐴 𝑡))
𝑄(𝑆𝑡, 𝐴 𝑡) ← 𝑄(𝑆𝑡, 𝐴 𝑡) + 𝑎(𝑅𝑡+1 + 𝛾 max
𝑎`
𝑄(𝑆𝑡+1, 𝑎`) − 𝑄(𝑆𝑡, 𝐴 𝑡))
살사의 큐함수 업데이트
큐러닝의 큐함수 업데이트
56.
큐러닝의 업데이트
다음 상태에서가장 큰 큐함수만 필요하기 때문에
샘플도 𝑆𝑡, 𝐴 𝑡, 𝑅𝑡+1, 𝑆𝑡+1 까지만 필요합니다.
𝑆𝑡, 𝐴 𝑡, 𝑅𝑡+1, 𝑆𝑡+1, 𝐴 𝑡+1
𝑆𝑡, 𝐴 𝑡, 𝑅𝑡+1, 𝑆𝑡+1
살사의 필요한 샘플
큐러닝의 필요한 샘플
57.
큐러닝의 업데이트
노란색으로 표시한수식 어디서 많이 보시지 않으셨나요?
𝑄(𝑆𝑡, 𝐴 𝑡) ← 𝑄(𝑆𝑡, 𝐴 𝑡) + 𝑎(𝑅𝑡+1 + 𝛾 max
𝑎`
𝑄(𝑆𝑡+1, 𝑎`) − 𝑄(𝑆𝑡, 𝐴 𝑡))
큐러닝의 큐함수 업데이트
58.
큐러닝의 업데이트
𝑞∗(𝑠, 𝑎)= 𝐸[𝑅𝑡+1 + 𝛾 max
𝑎`
𝑞∗(𝑆𝑡+1, 𝑎`) |𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎]
바로 벨만 최적 방정식에서 비롯된 것입니다.
- 큐함수로 표현한 벨만 최적 방정식
59.
4. 큐러닝(Q-Learning)
정리!
큐러닝은 살사의문제점을 극복하는 알고리즘으로써,
행동하는 정책인 𝜀 –탐욕 정책과
학습하는 정책인 벨만 최적 방정식을 이용한
오프폴리시(Off-Policy) 강화학습 알고리즘입니다.
살사(시간차 제어)의 특징
1. 벨만 최적 방정식을 이용
2. 𝜀 –탐욕 정책 + 벨만 최적 방정식
4. 𝑆𝑡, 𝐴 𝑡, 𝑅𝑡+1, 𝑆𝑡+1 의 샘플을 사용
60.
4. 큐러닝(Q-Learning)
1. 𝜀–탐욕 정책을 통해 𝑆𝑡, 𝐴 𝑡, 𝑅𝑡+1, 𝑆𝑡+1 의 샘플 획득
2. 획득한 샘플로 다음 식을 통해 큐함수 𝑄(𝑆𝑡, 𝐴 𝑡)를 업데이트
𝑄(𝑆𝑡, 𝐴 𝑡) ← 𝑄(𝑆𝑡, 𝐴 𝑡) + 𝑎(𝑅𝑡+1 + 𝛾 max
𝑎`
𝑄(𝑆𝑡+1, 𝑎`) − 𝑄(𝑆𝑡, 𝐴 𝑡))
출처 : 파이썬과 케라스로 배우는 강화학습 저자특강
이미지 출저 : https://www.slideshare.net/WoongwonLee/ss-78783597














![몬테카를로 예측(Monte-Carlo Prediction)
다이나믹 프로그래밍에서의 기존의 가치함수는 기댓값을 통해 계산
𝑣 𝜋 𝑠 = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠]](https://image.slidesharecdn.com/flowchartpart2ofreinforcementlearning-180322085118/85/Part-2-14-320.jpg)








![시간차 예측(Temporal-Difference Prediction)
가치함수의 정의를 이용하여 𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)을 기댓값을 계산하지 않고
샘플링을 평균하여 가치함수를 추정합니다.
𝑣 𝜋 𝑠 = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠] - 가치함수의 정의
𝑉(𝑆𝑡) ← 𝑉(𝑆𝑡) + 𝑎(𝑅𝑡+1 + 𝛾𝑉(𝑆𝑡+1) − 𝑉(𝑆𝑡))
- 시간차 예측에서 가치함수의 업데이트](https://image.slidesharecdn.com/flowchartpart2ofreinforcementlearning-180322085118/85/Part-2-23-320.jpg)
![시간차 예측(Temporal-Difference Prediction)
𝑣 𝜋 𝑠 = 𝐸 𝜋[𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)|𝑆𝑡 = 𝑠] - 가치함수의 정의
𝑉(𝑆𝑡) ← 𝑉(𝑆𝑡) + 𝑎(𝑅𝑡+1 + 𝛾𝑉(𝑆𝑡+1) − 𝑉(𝑆𝑡))
- 시간차 예측에서 가치함수의 업데이트
시간차 에러(Temporal-Difference Error, TD Error)
가치함수의 정의를 이용하여 𝑅𝑡+1 + 𝛾𝑣 𝜋(𝑆𝑡+1)을 기댓값을 계산하지 않고
샘플링을 평균하여 가치함수를 추정합니다.](https://image.slidesharecdn.com/flowchartpart2ofreinforcementlearning-180322085118/85/Part-2-24-320.jpg)









![시간차 제어의 탐욕 정책
정책 이터레이션(GPI)의 탐욕 정책 발전
𝜋` 𝑠 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴[𝑅 𝑠
𝑎 + 𝛾𝑃𝑠𝑠`
𝑎
𝑉 𝑠` ]](https://image.slidesharecdn.com/flowchartpart2ofreinforcementlearning-180322085118/85/Part-2-34-320.jpg)
![시간차 제어의 탐욕 정책
정책 이터레이션(GPI)의 탐욕 정책 발전
시간차 제어(살사)의 큐함수를 사용한 탐욕 정책
𝜋` 𝑠 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴[𝑅 𝑠
𝑎
+ 𝛾𝑃𝑠𝑠`
𝑎
𝑉 𝑠` ]
𝜋 𝑠 = 𝑎𝑟𝑔𝑚𝑎𝑥 𝑎∈𝐴 𝑄(𝑠, 𝑎)
탐욕 정책에서 다음 상태의 가치함수를 보고 판단하는 것이 아니고
현재 상태의 큐함수를 보고 판단한다면 환경의 모델을 몰라도 됩니다.
따라서 앞으로 큐함수에 따라 행동을 선택할 것입니다.](https://image.slidesharecdn.com/flowchartpart2ofreinforcementlearning-180322085118/85/Part-2-35-320.jpg)


















![큐러닝의 업데이트
𝑞∗(𝑠, 𝑎) = 𝐸[𝑅𝑡+1 + 𝛾 max
𝑎`
𝑞∗(𝑆𝑡+1, 𝑎`) |𝑆𝑡 = 𝑠, 𝐴 𝑡 = 𝑎]
바로 벨만 최적 방정식에서 비롯된 것입니다.
- 큐함수로 표현한 벨만 최적 방정식](https://image.slidesharecdn.com/flowchartpart2ofreinforcementlearning-180322085118/85/Part-2-58-320.jpg)

























![[RLkorea] 각잡고 로봇팔 발표](https://cdn.slidesharecdn.com/ss_thumbnails/rlkorea-robotarm-190303021332-thumbnail.jpg?width=640&height=640&fit=bounds)















![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 1장. 한눈에 보는 머신러닝](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180626070350-thumbnail.jpg?width=640&height=640&fit=bounds)




















