Downloaded 21 times





























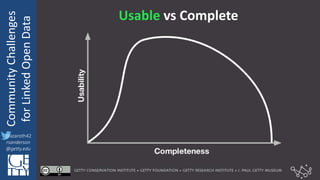
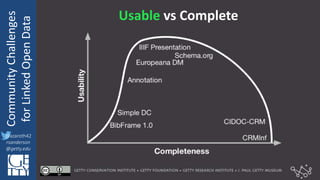
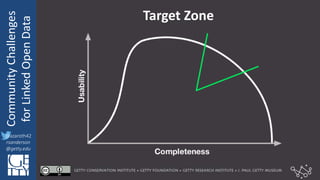










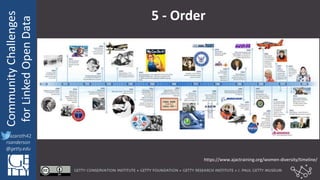







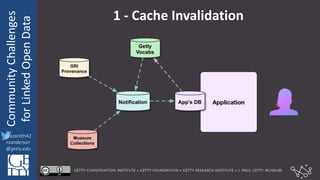










The document discusses community challenges in practical linked open data (LOD) and emphasizes the importance of collaboration among stakeholders to create and publish historical LOD effectively. Key topics include understanding audience needs, ensuring data usability, and identifying common challenges such as naming conventions and cache invalidation. It encourages a focused, open, active, and flexible community approach to enhance the development and implementation of LOD.






























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




