Downloaded 42 times








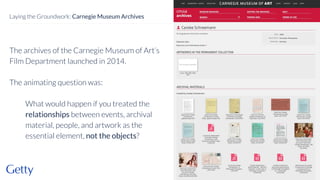
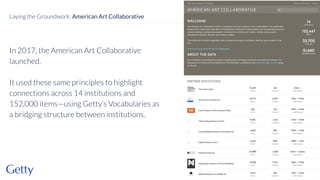
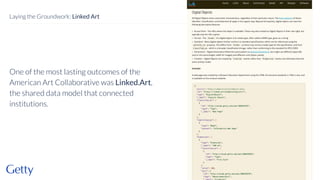




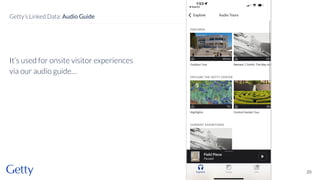

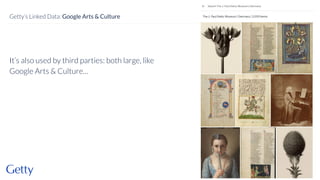



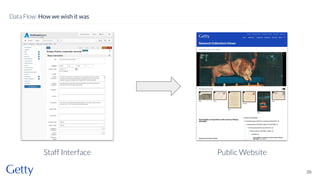
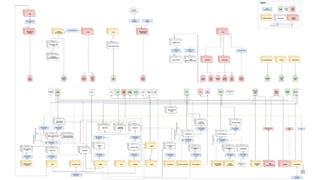




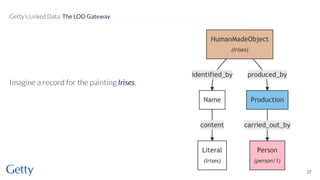

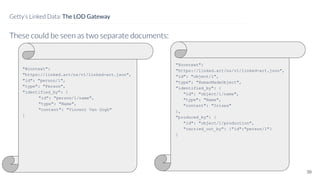
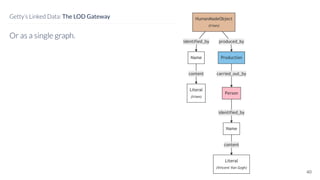


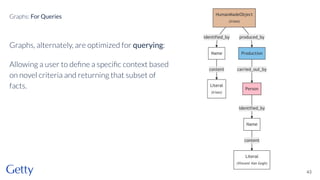



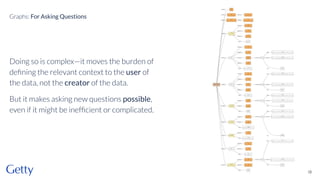









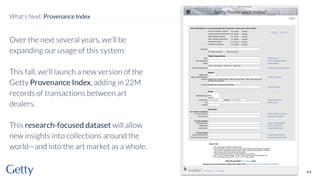





David Newbury discusses the challenges and advancements of linked open data in the cultural heritage sector, emphasizing its technological solutions to the social problem of data overload. He highlights Getty's long-term commitment to linked data since 2014, showcasing its applications in various museum contexts and the importance of developing a user-centered infrastructure. The presentation concludes with a focus on expanding collaborations and adapting to diverse user needs in future projects.























































































