Download as ZIP, PPTX





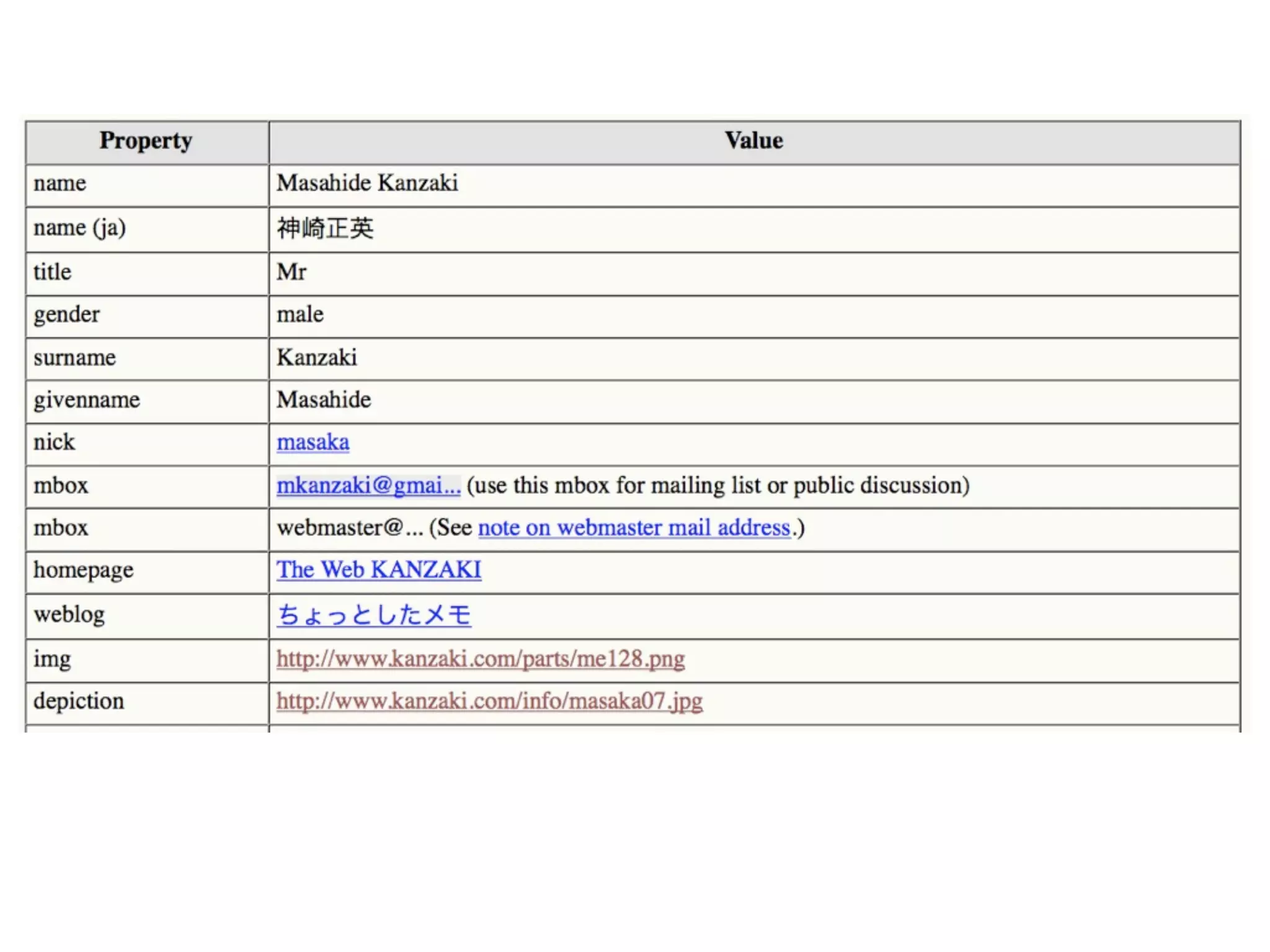
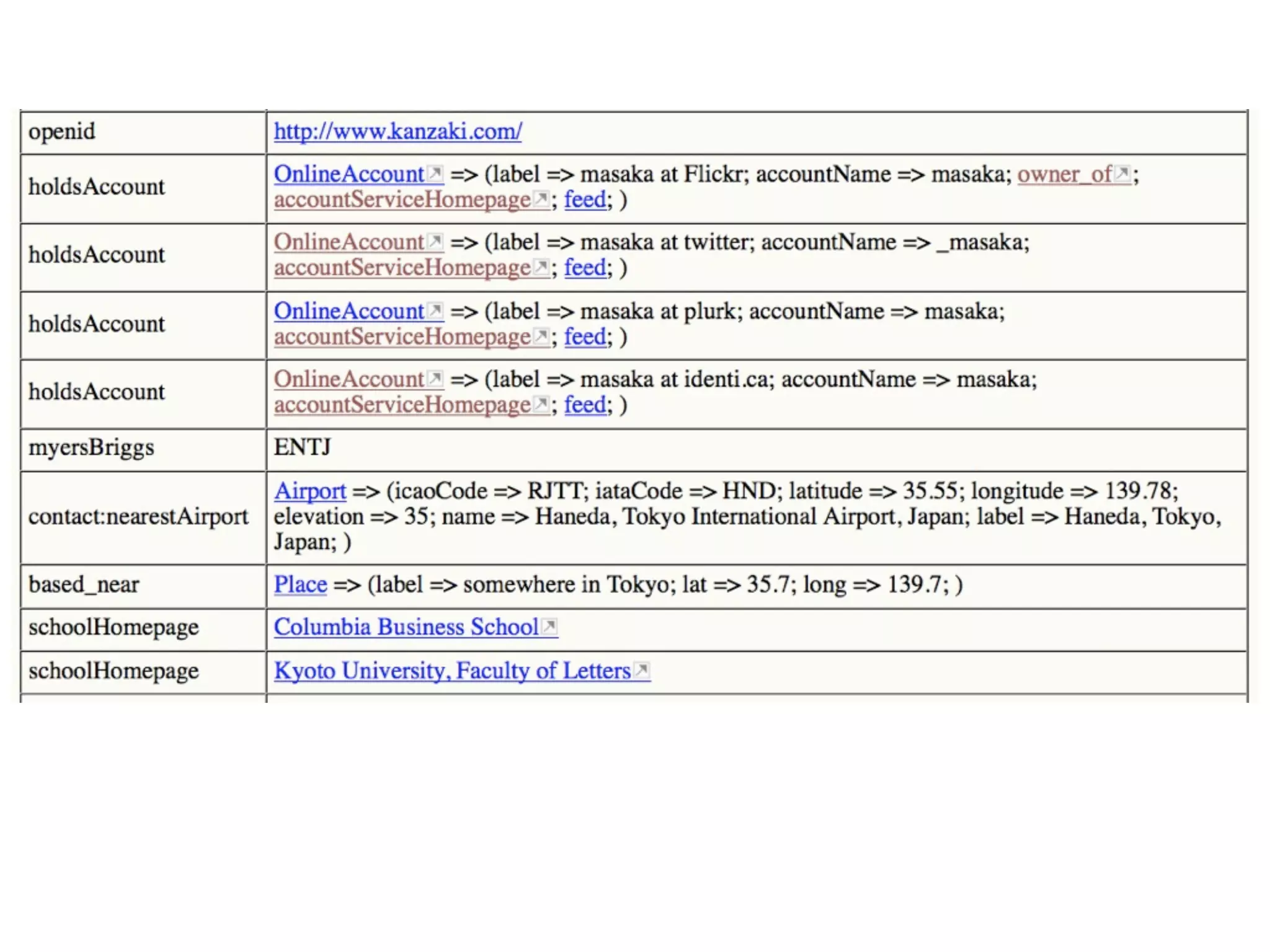
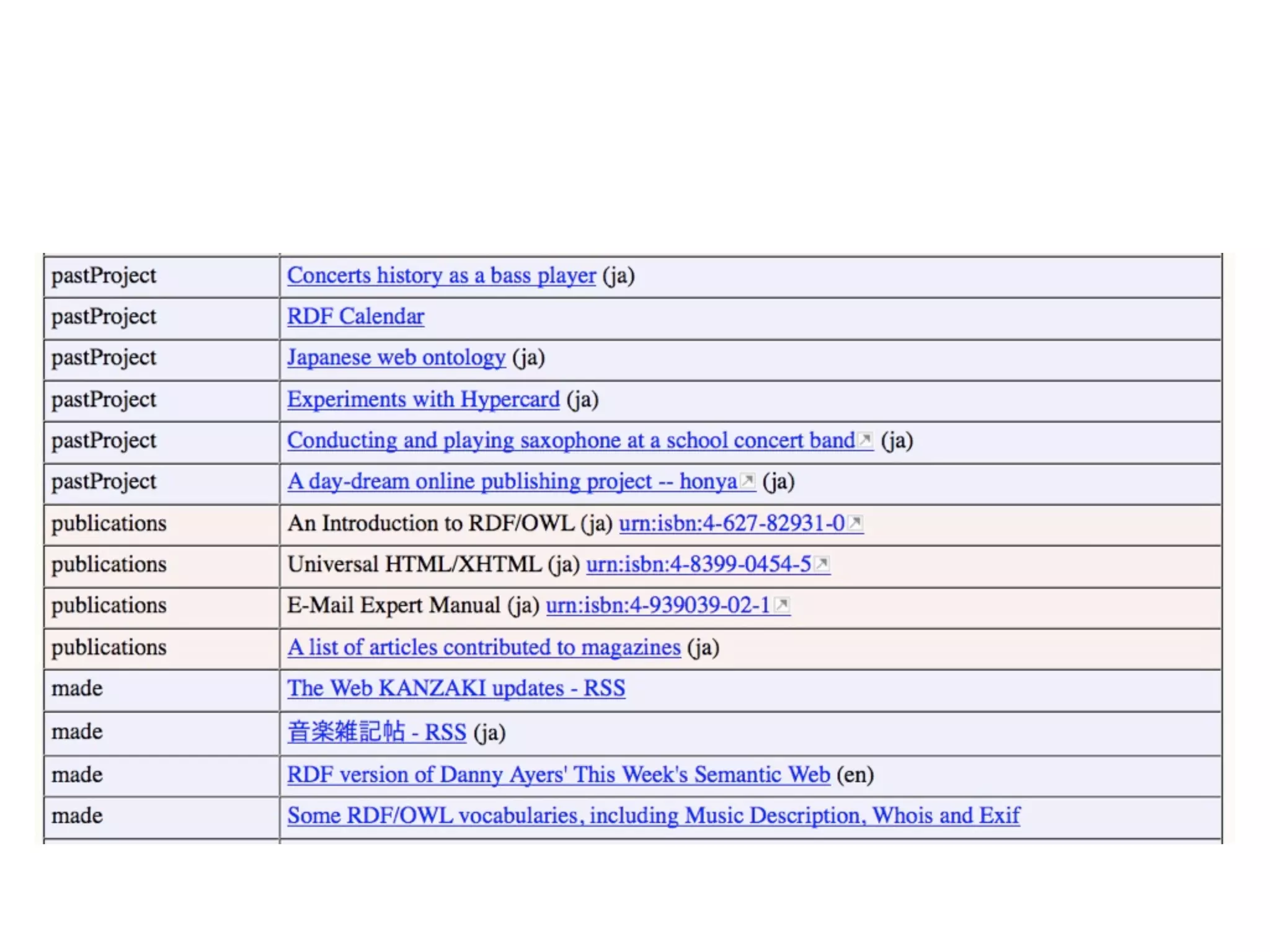
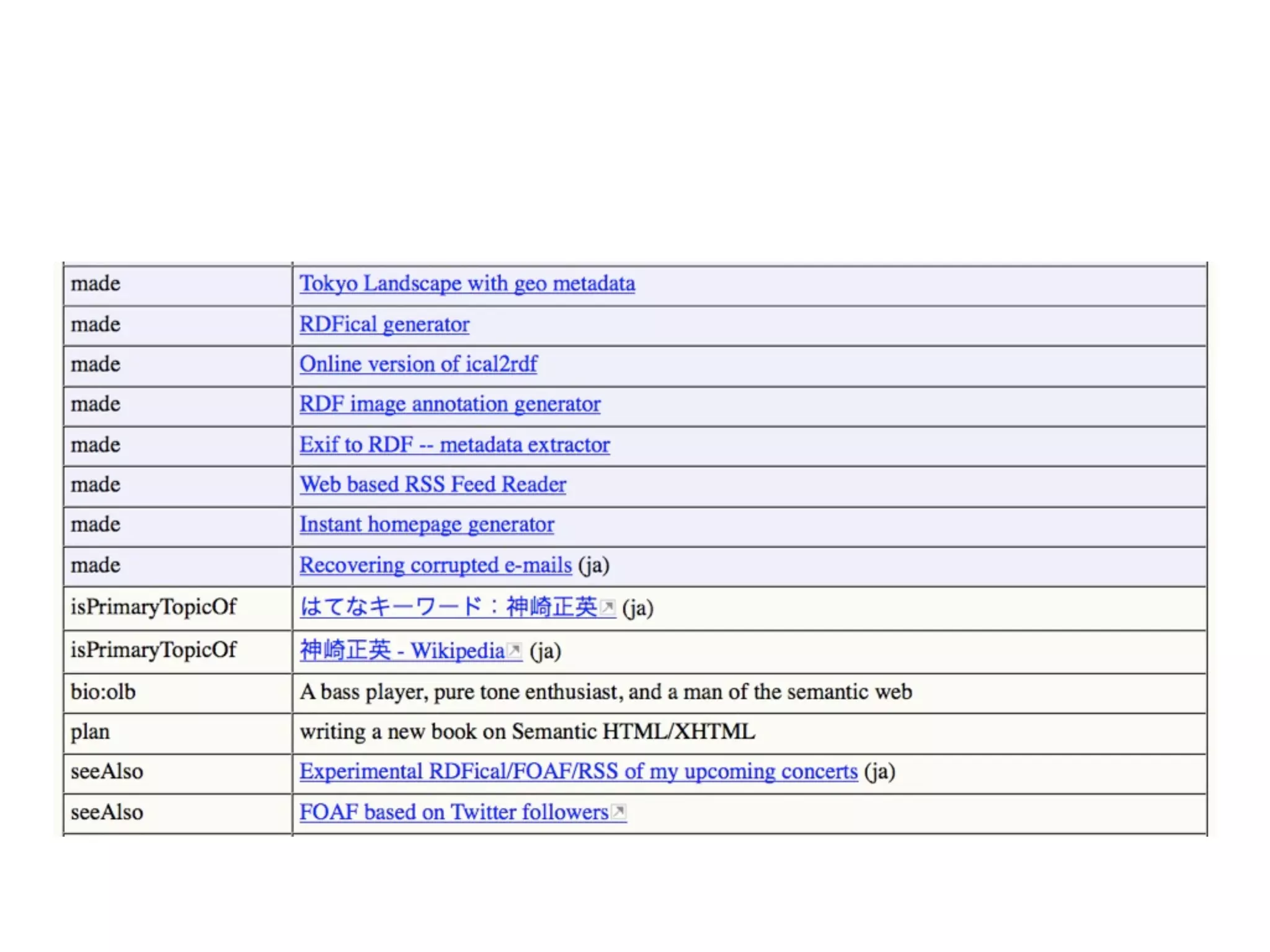
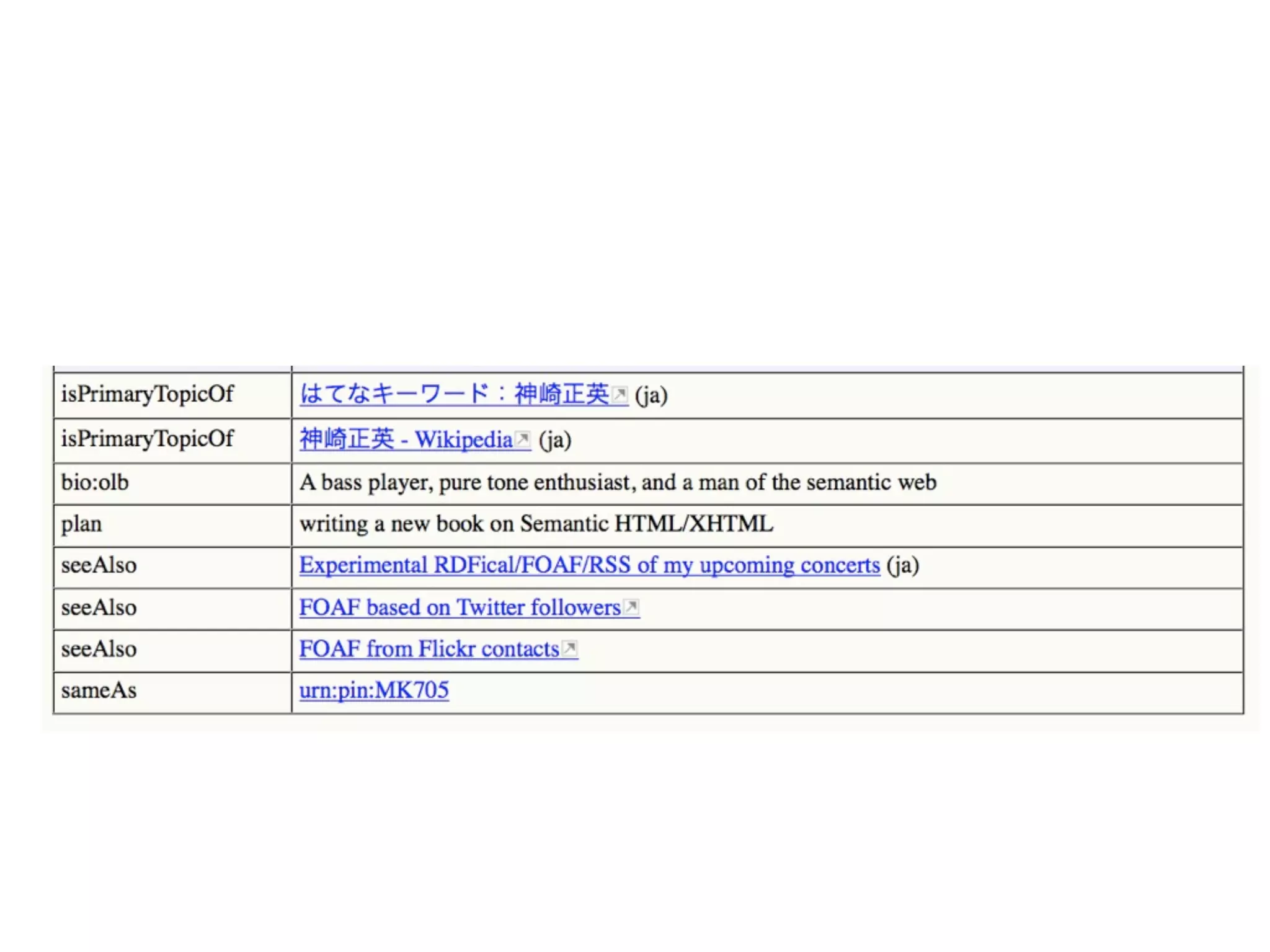
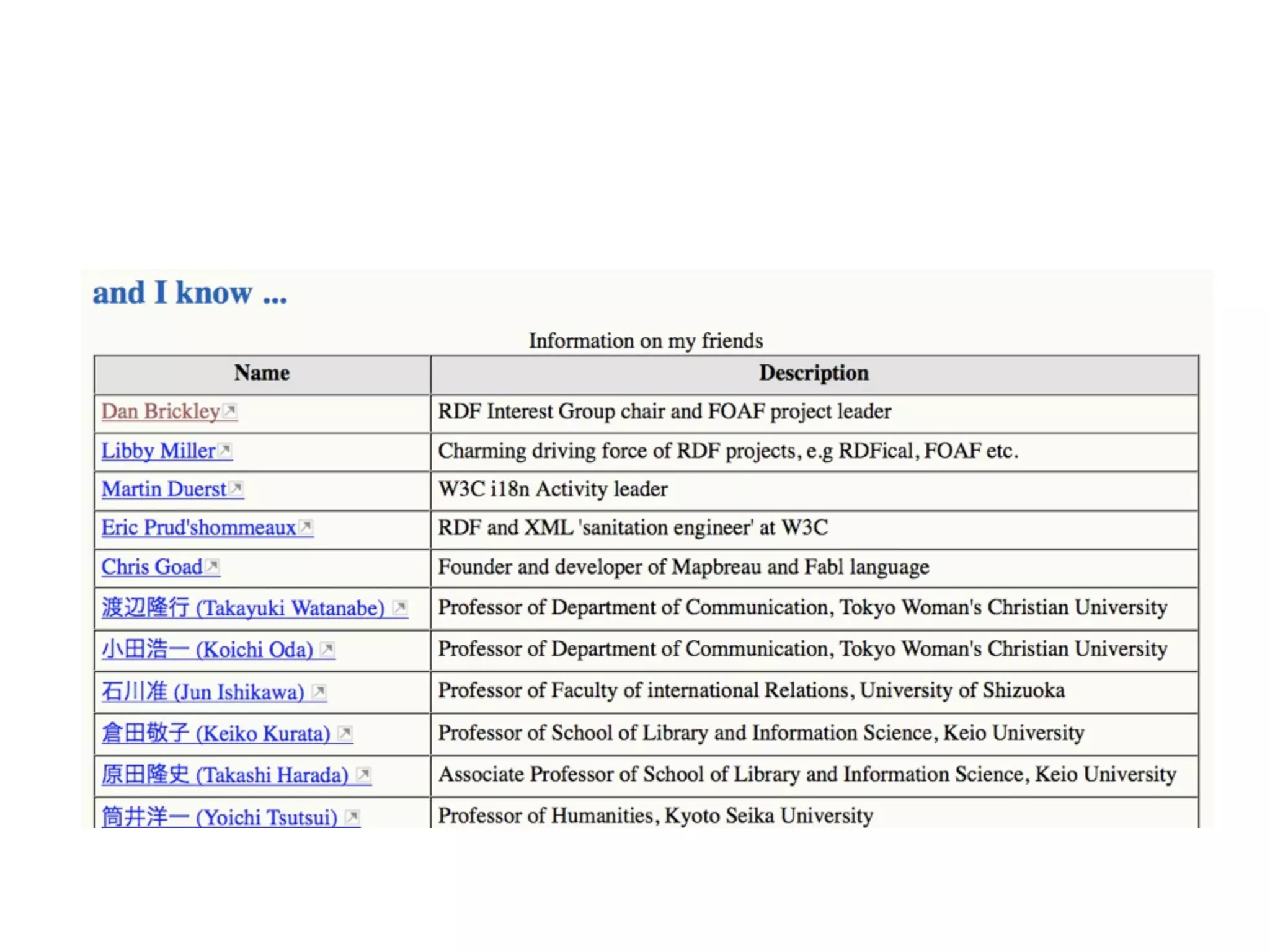












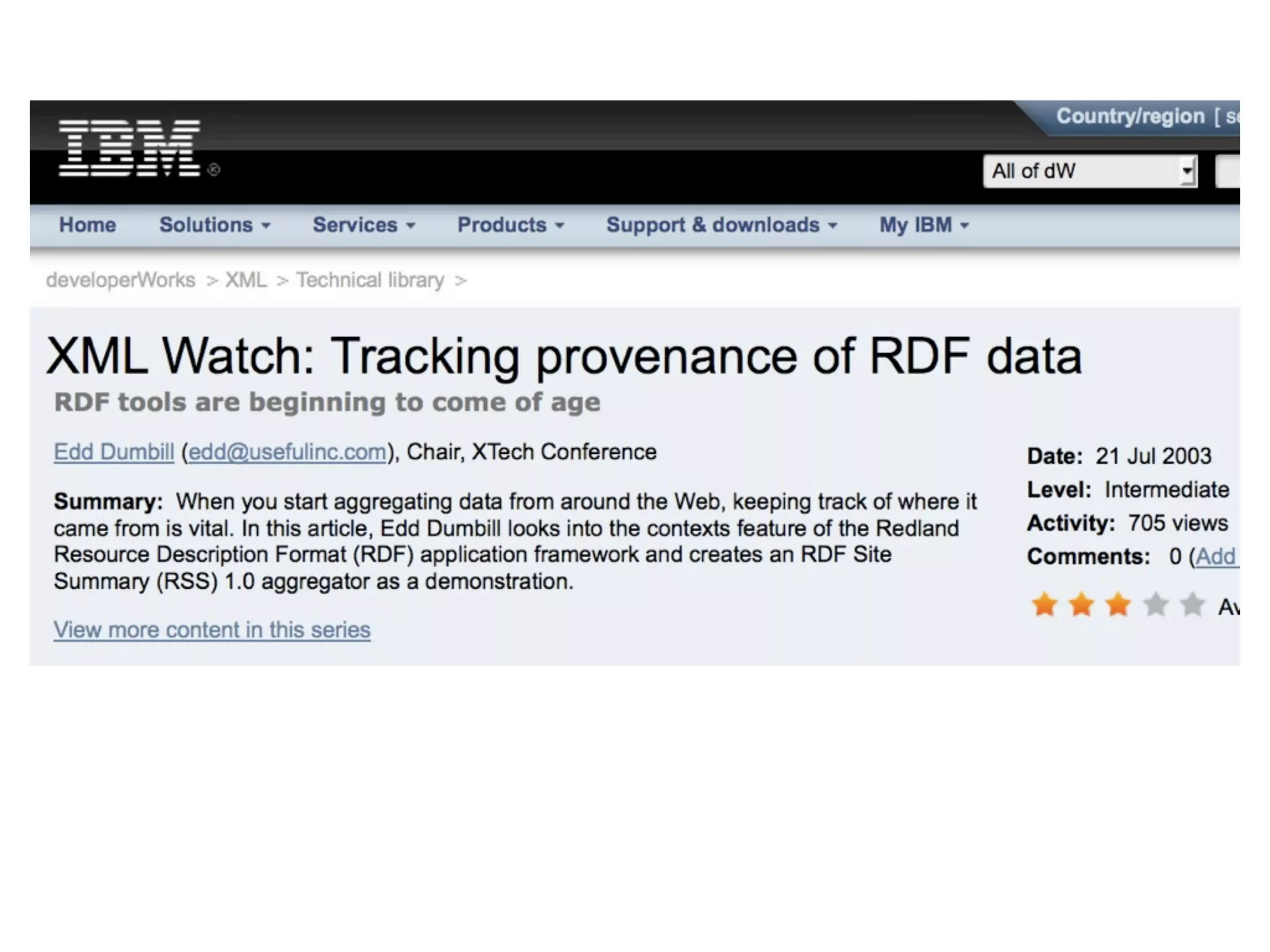




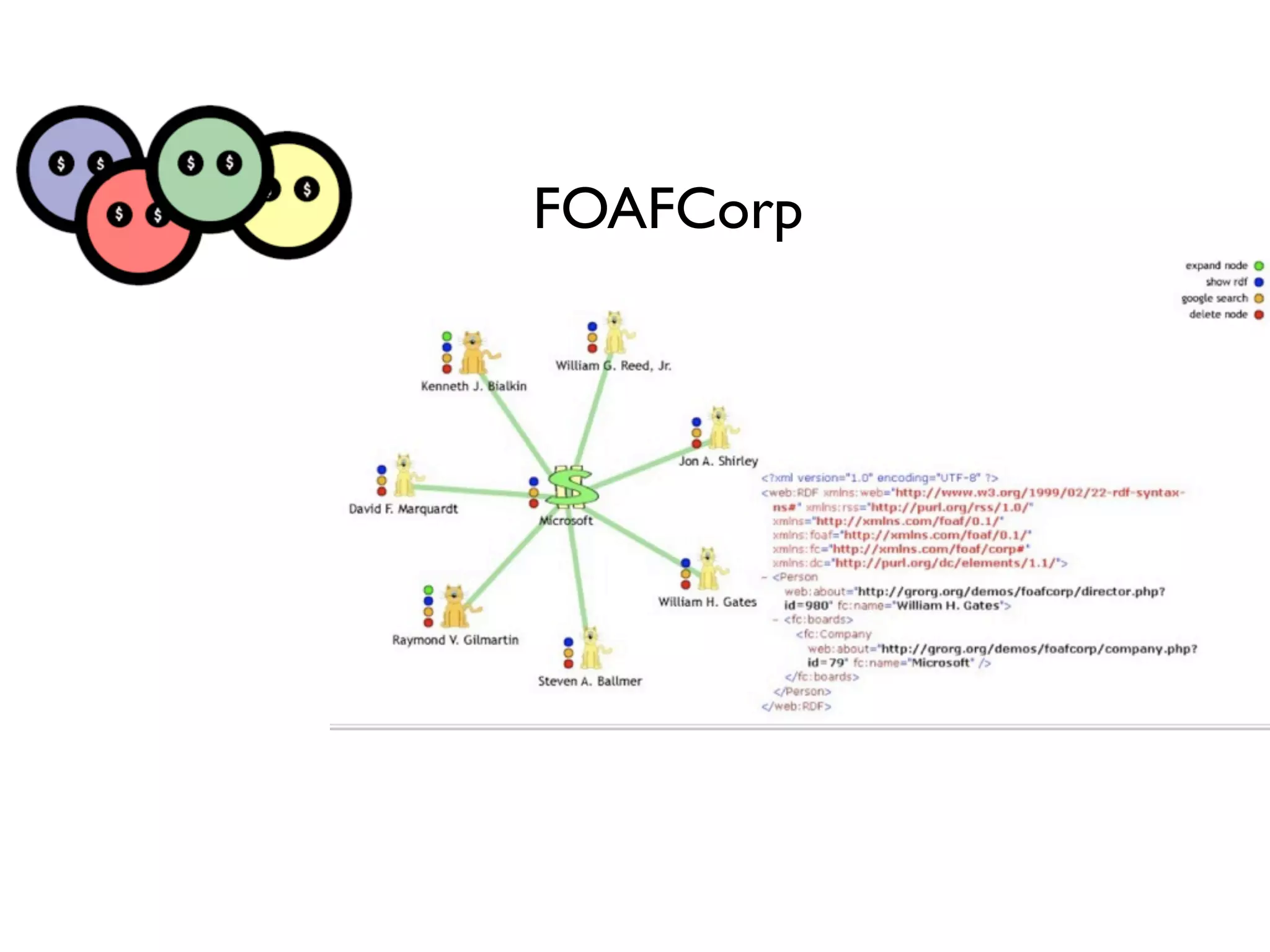
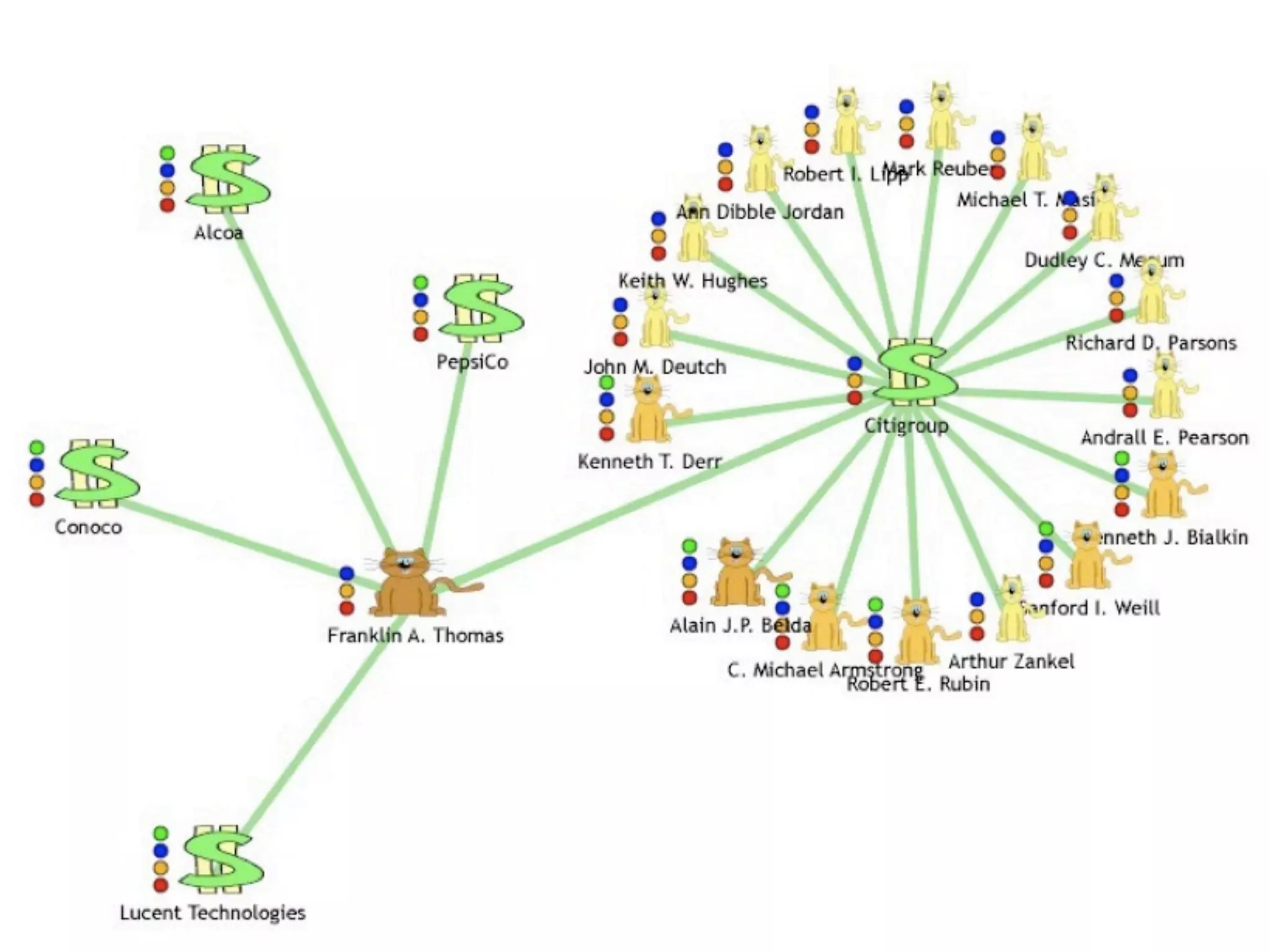

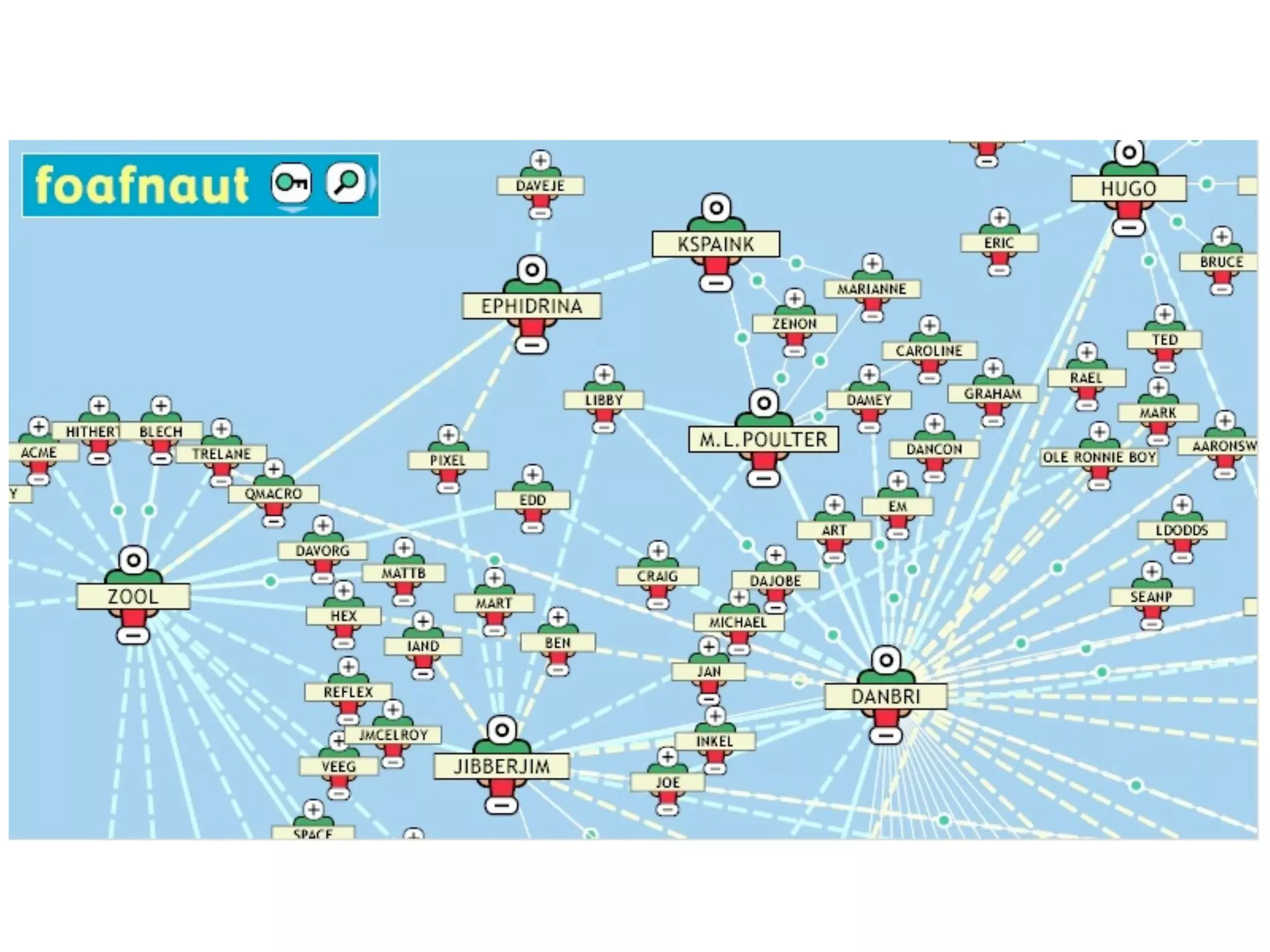
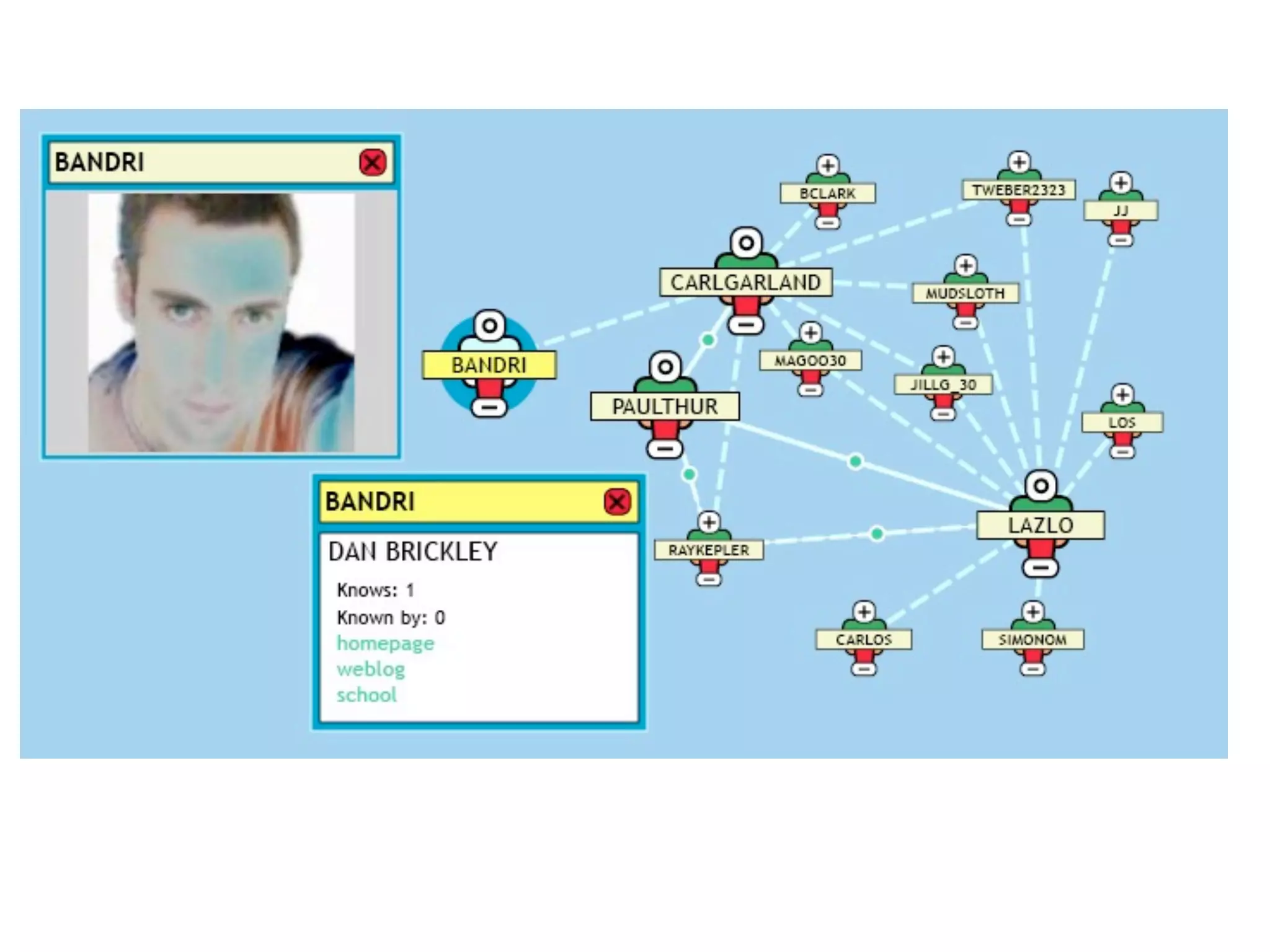
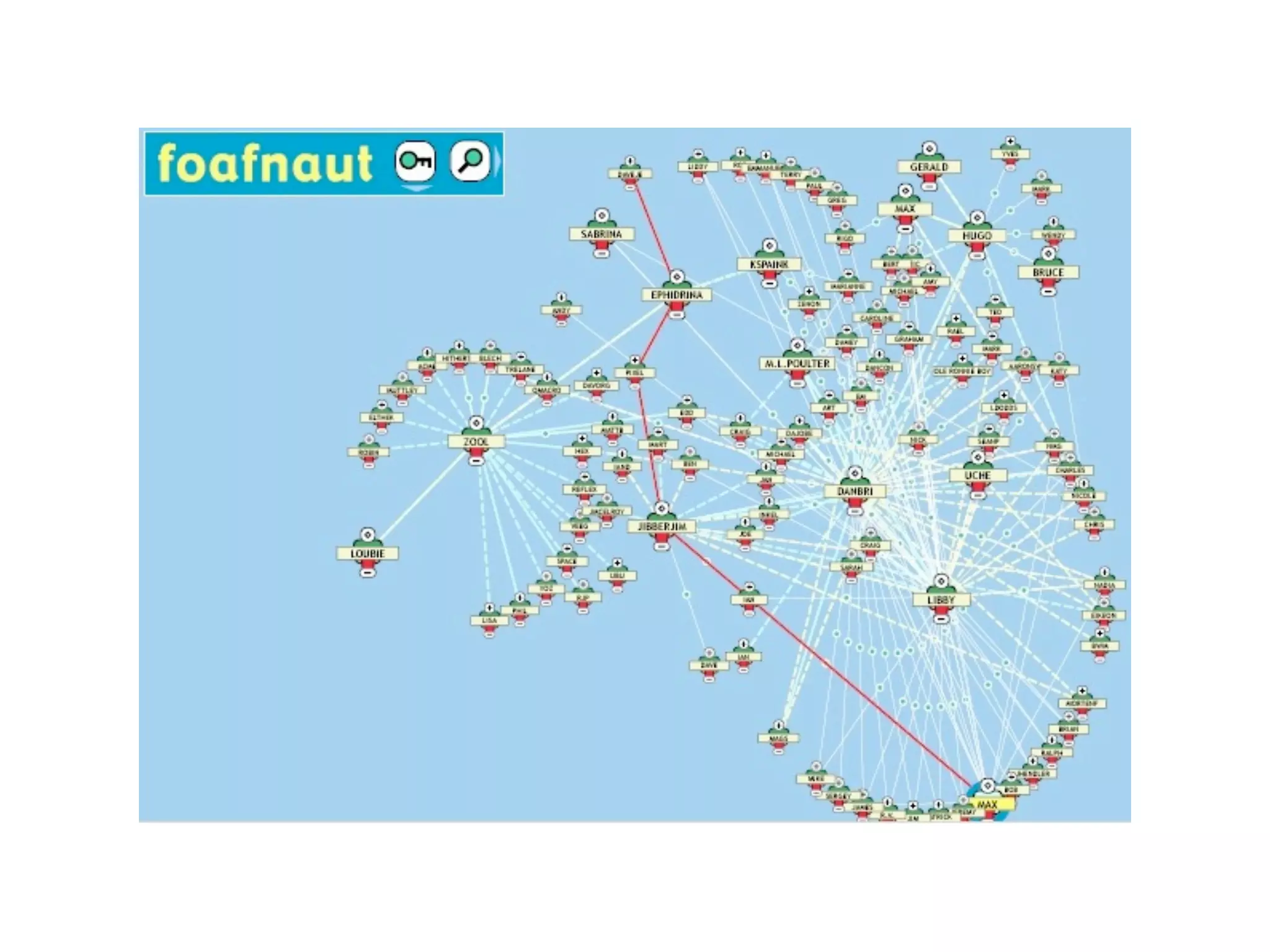
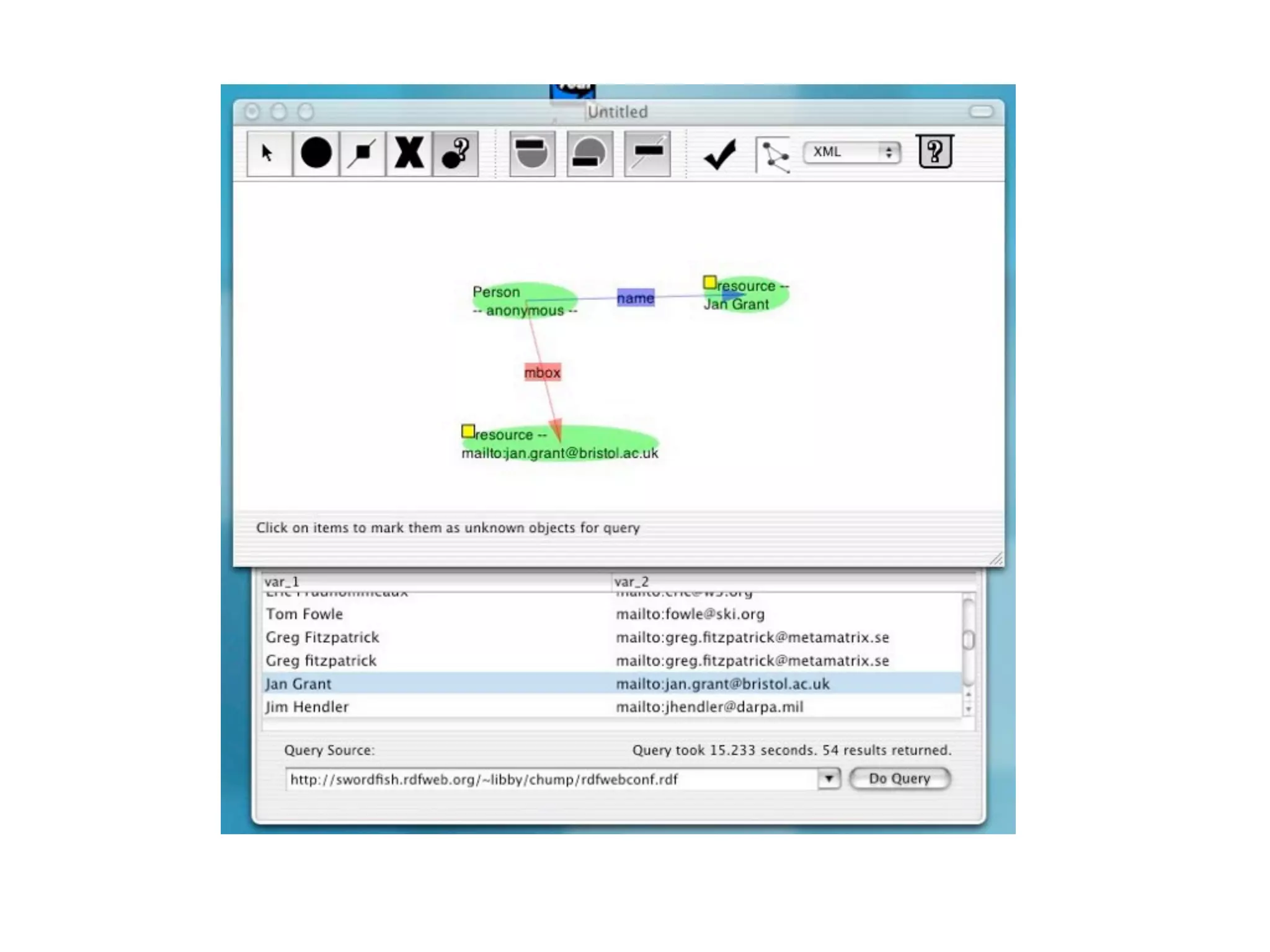


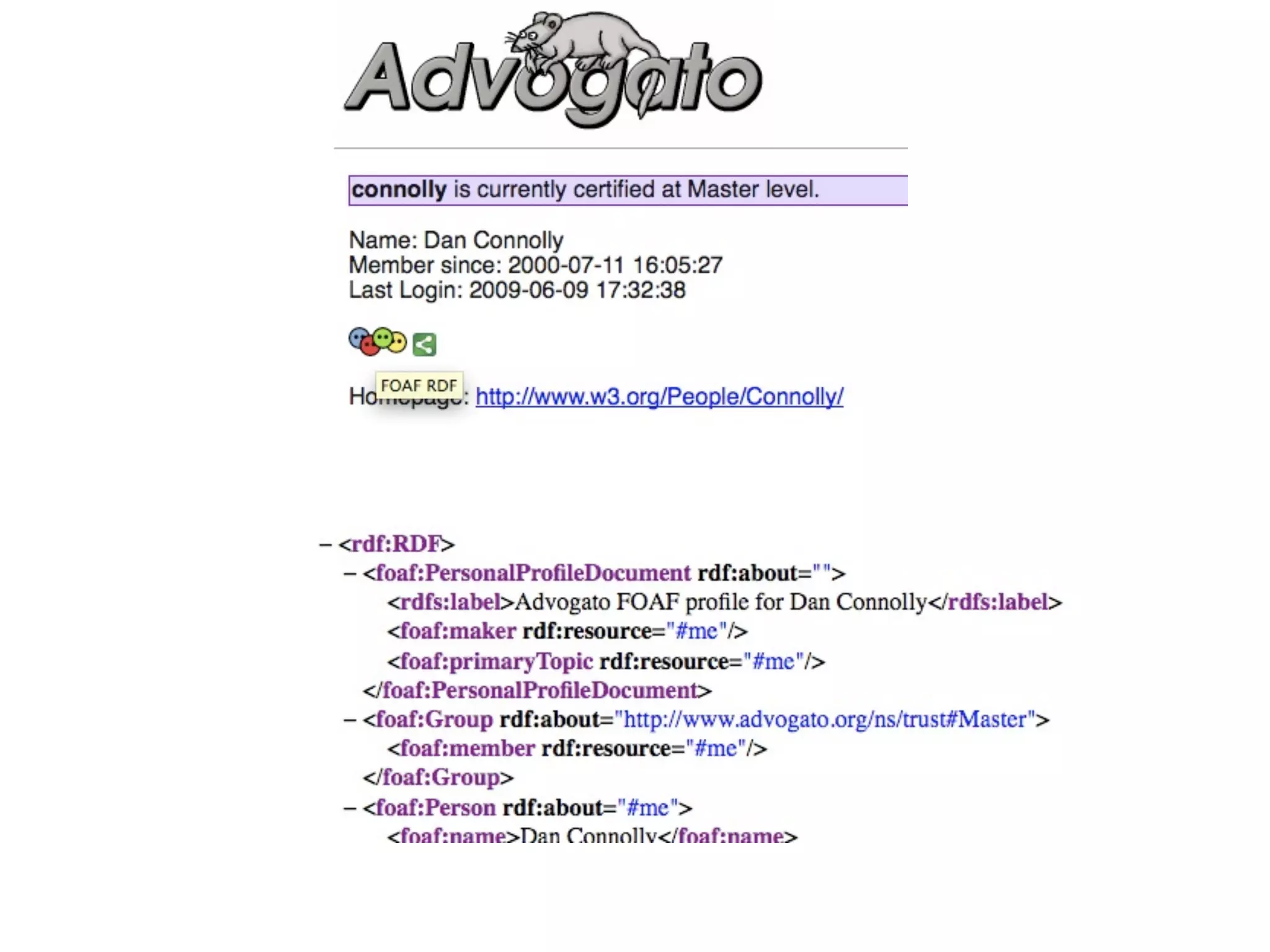

















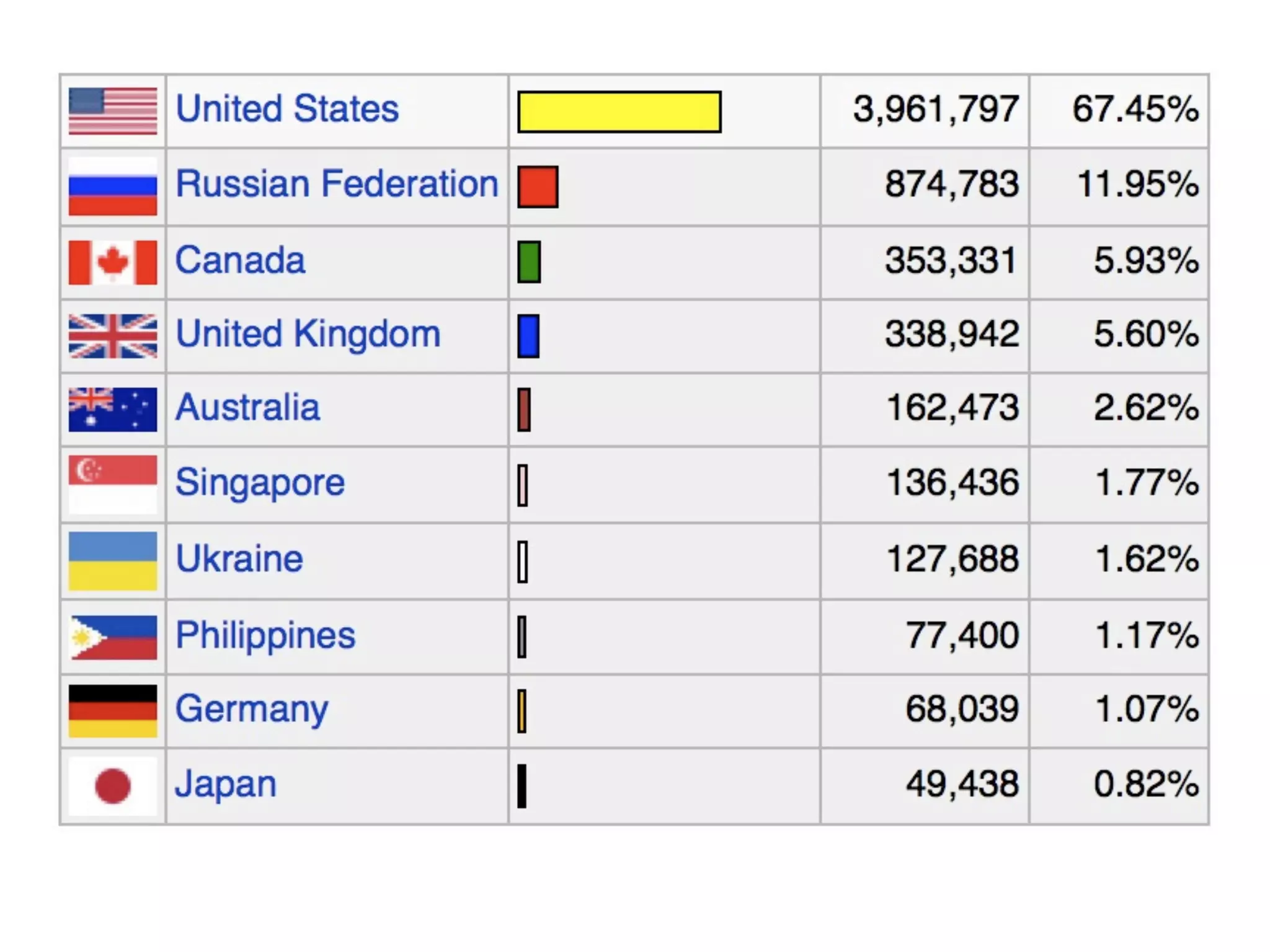









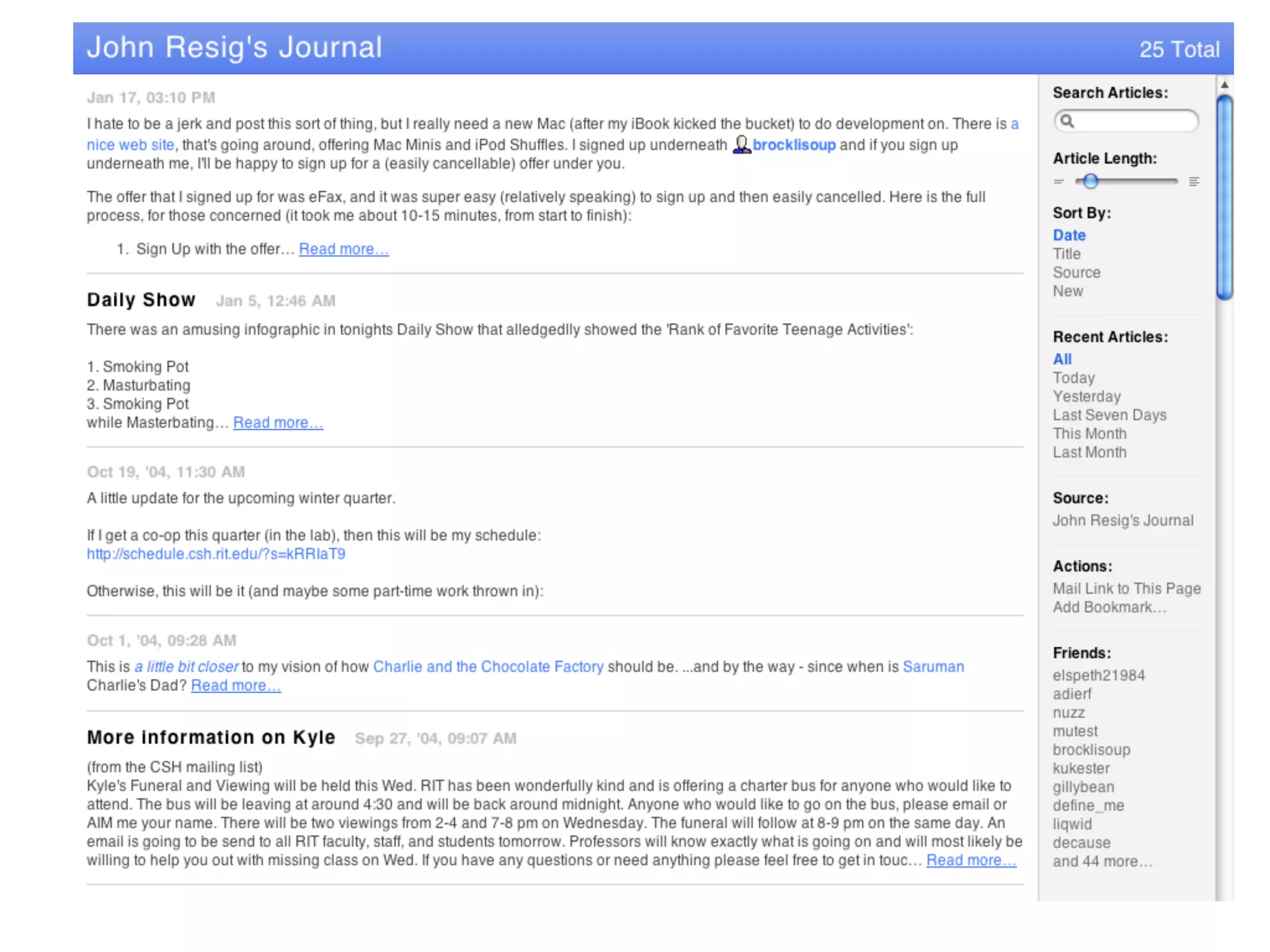


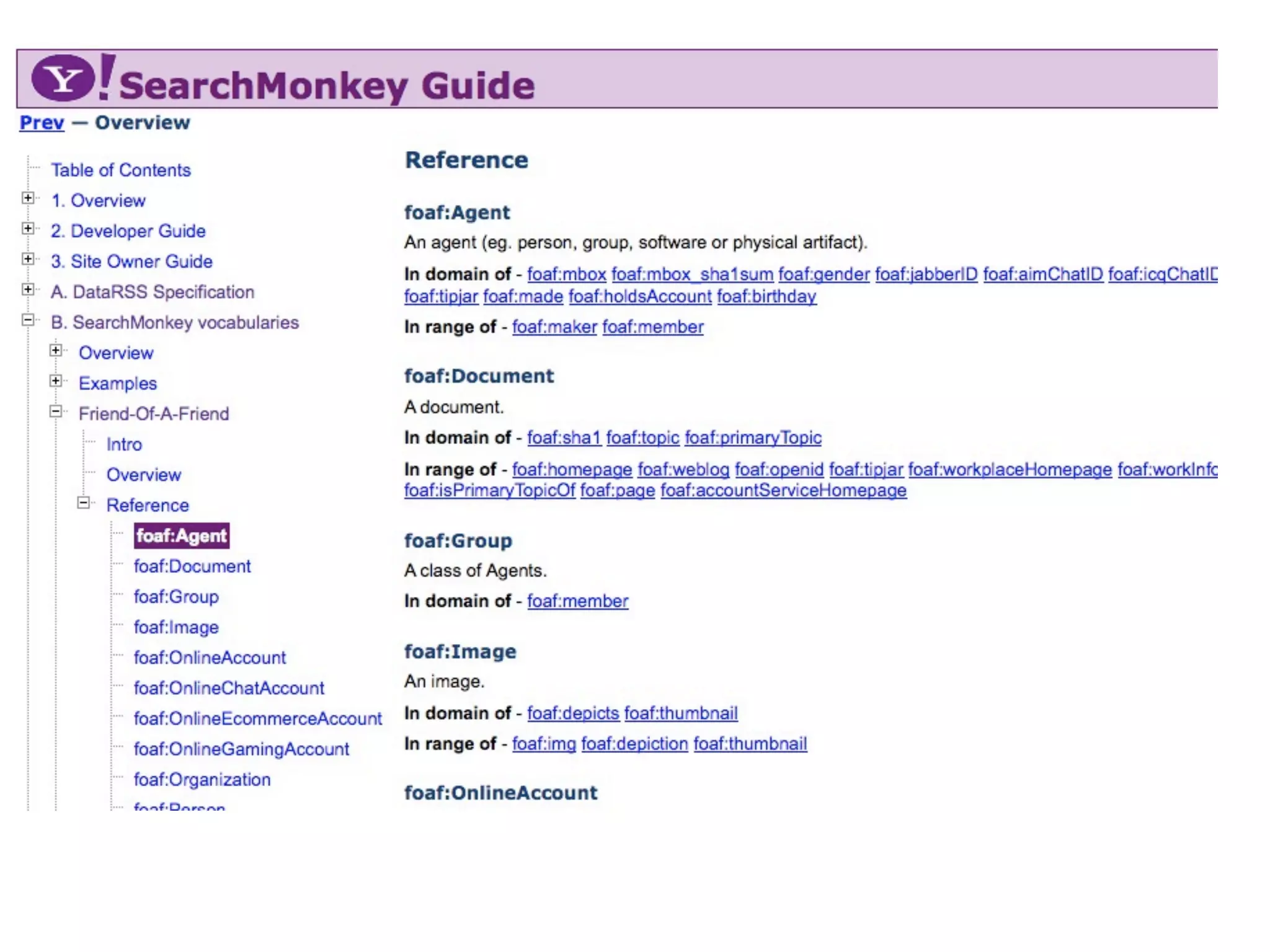



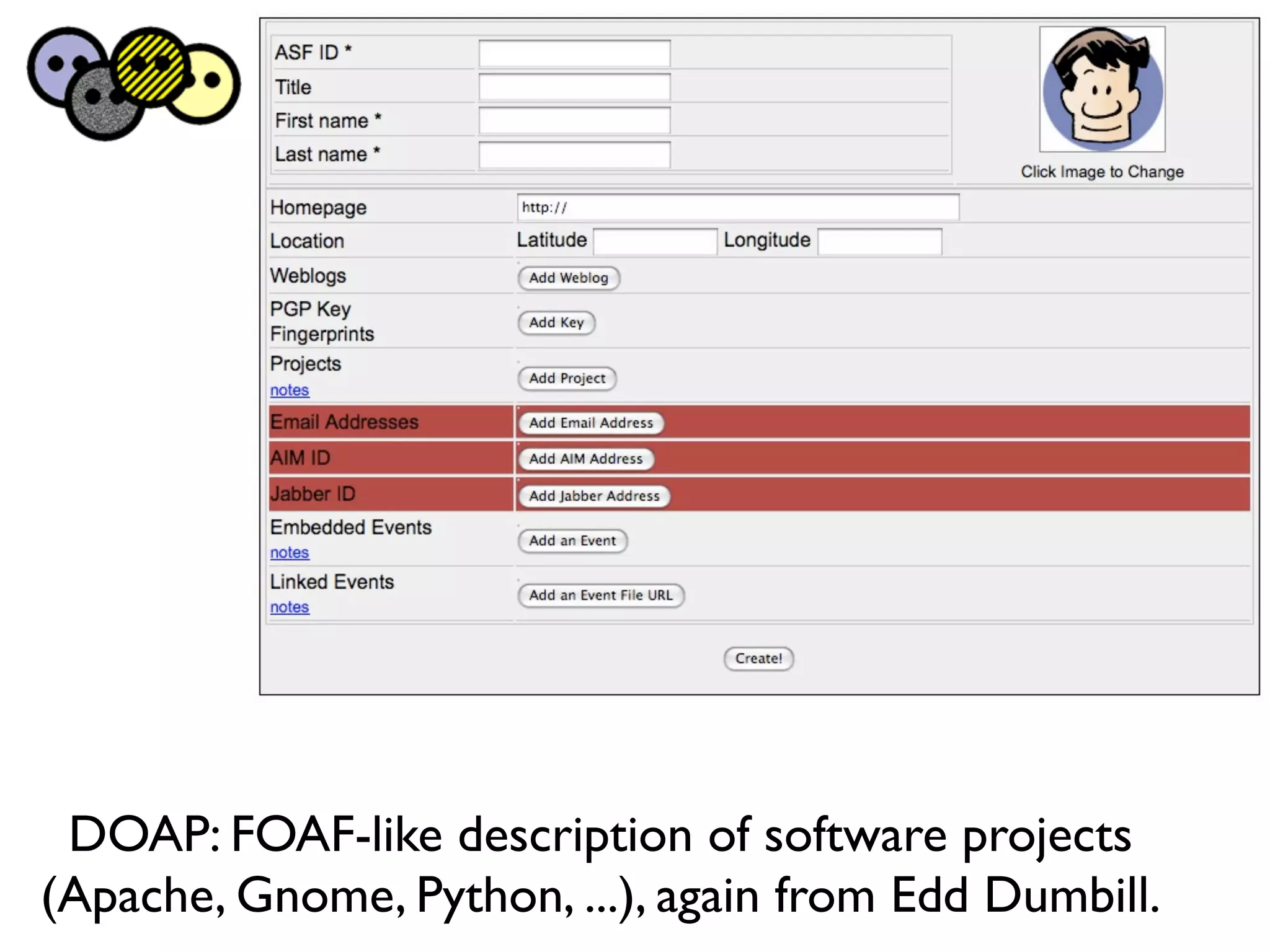

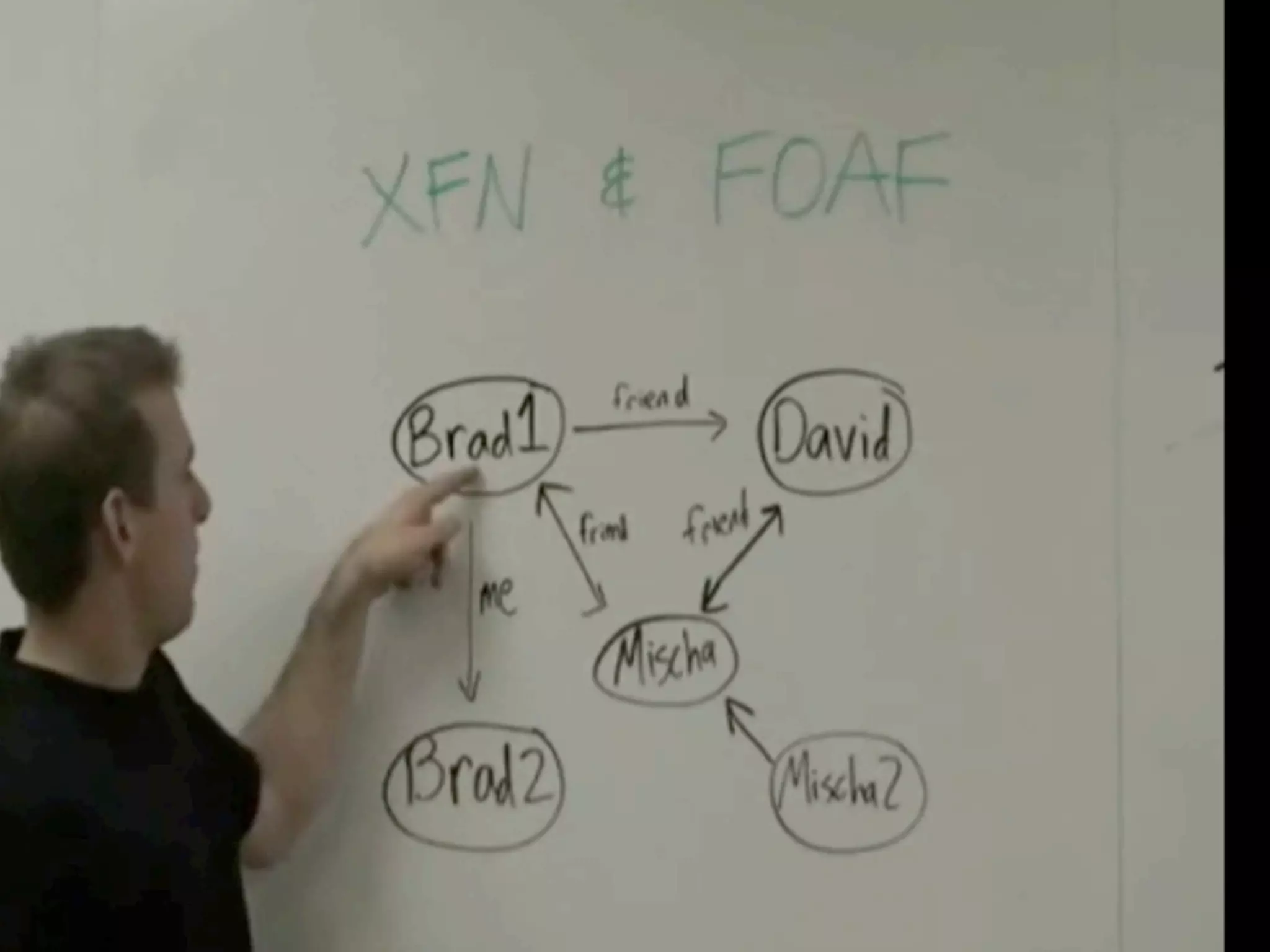
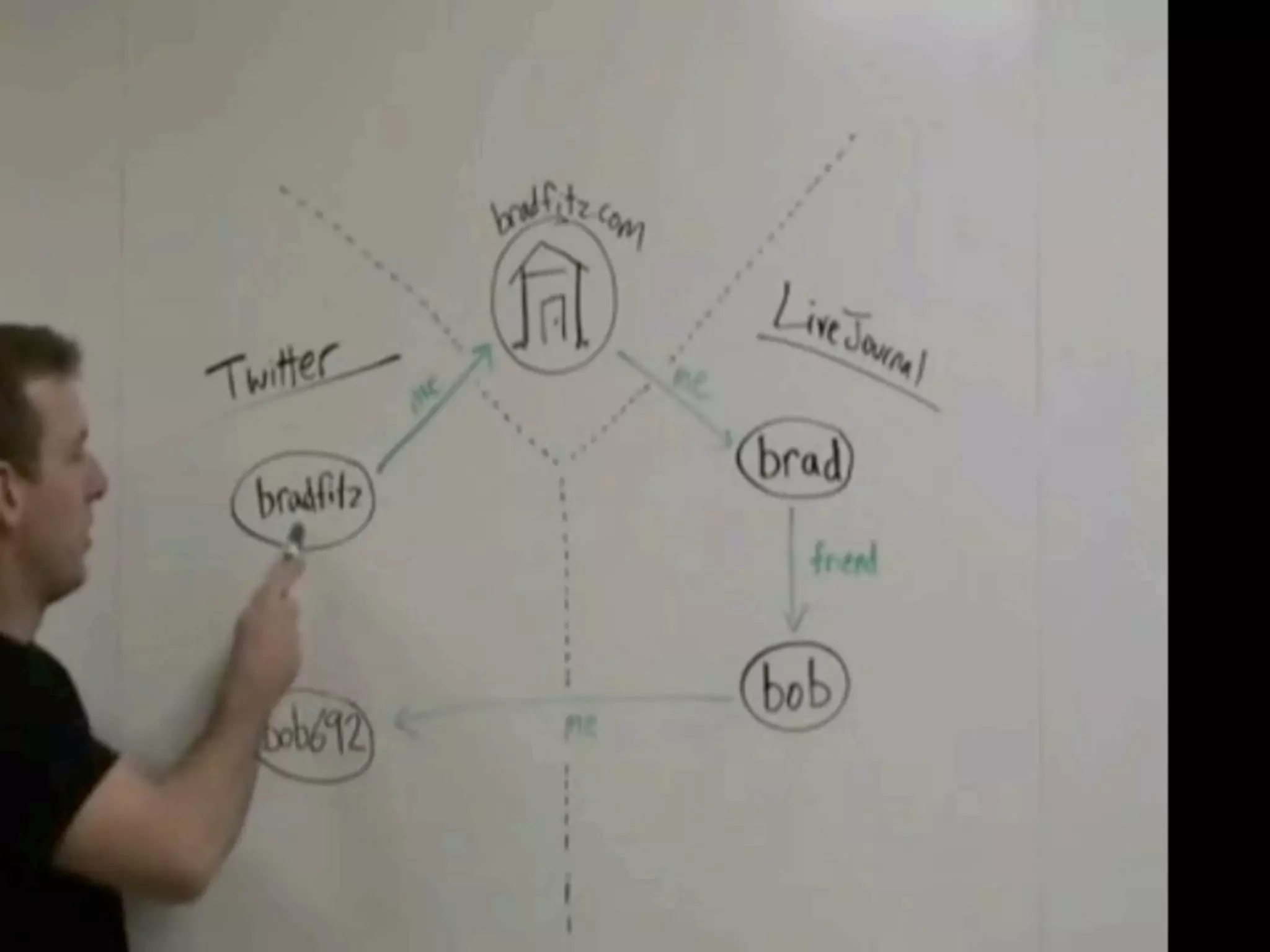

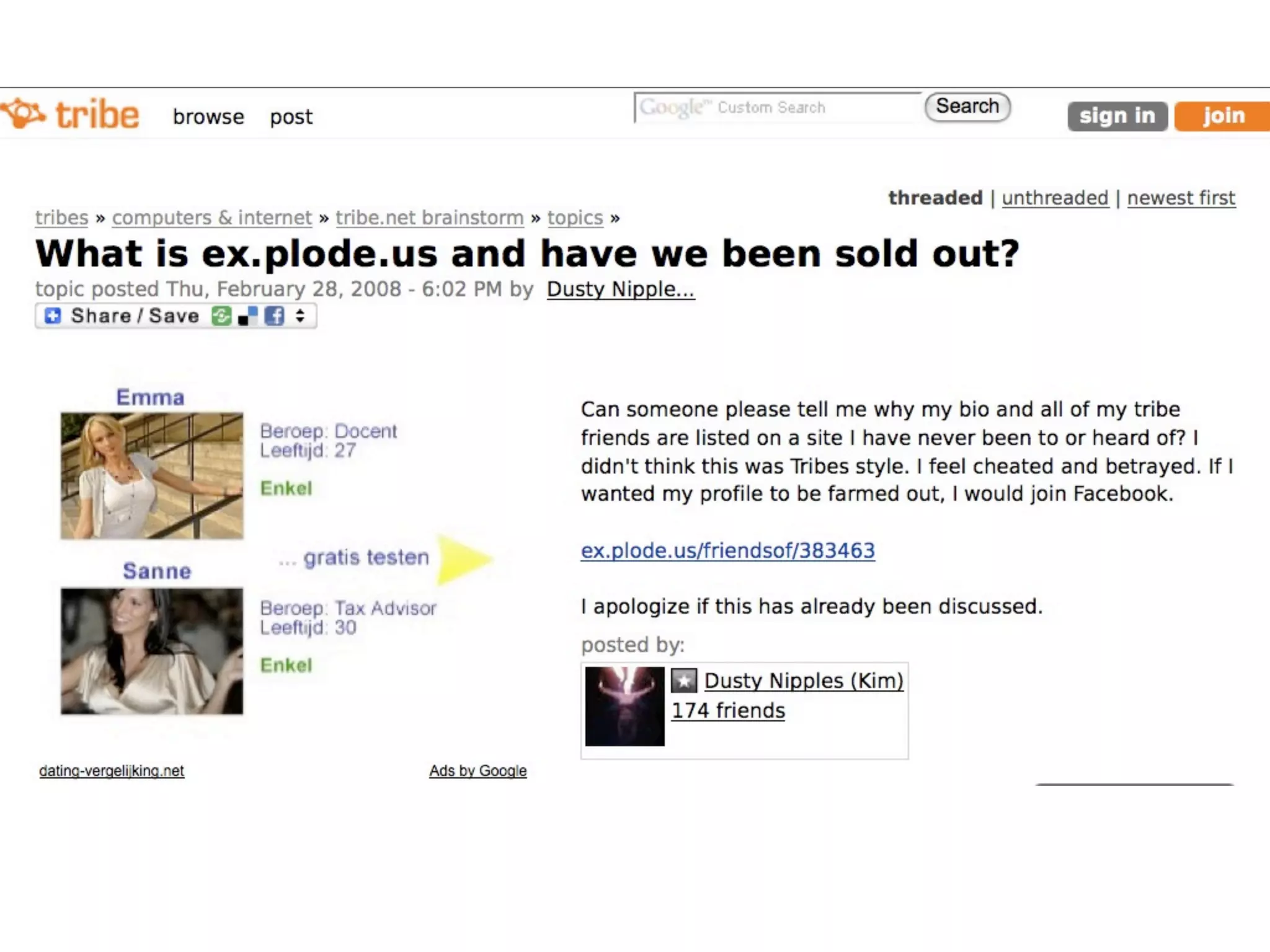










FOAF (Friend of a Friend) is the most used ontology in the history of the universe. The document discusses the origins and rise of FOAF, which started as the RDFWebRing in 2000 to describe personal profiles and connections between individuals on the semantic web. It became widely used through applications like LiveJournal and Tribe in the early 2000s. The simple concept of describing people and their relationships enabled FOAF to spread organically and become very active despite starting as a side project.















![Solid: An Ecology of Digital Being [@SLA Europe October 28, 2020]](https://cdn.slidesharecdn.com/ss_thumbnails/solidanecologyofdigitalbeingteodorapetkovaslaeuropeoctober282020-201227152013-thumbnail.jpg?width=640&height=640&fit=bounds)

















































![[Webinar] Semantic Technologies](https://cdn.slidesharecdn.com/ss_thumbnails/webinar-nuxeo-semantic-110526075831-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)



