Downloaded 163 times



![The Linking Open Data initiative
• “bootstrap” the data web with large, interconnected data sets
to reach a critical mass of semantics
• strict adherence to W3C standards
• identification and transportation (URI, HTTP) of resource
descriptions
• interpretation (RDF, RDFS, OWL) of resource descriptions
• LOD grows as data providers:
• publish structured data on the Web
• set RDF links between entities in different data sources
• transition of the web from a distributed document repository
into a universal, ubiquitous database [Erling 09]
4](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-4-2048.jpg)

![Describing linked datasets
• voiD (Vocabulary of Interlinked Datasets)
[Alexander, Cyganiak, Hausenblas, Zhao 09]
• describes data sets the link sets between them
• DING (Dataset RankING) [Toupikov, Umbrich,
Delbru, Hausenblas, Tummarello 09]
• ranking of linked datasets using formal
descriptions
• modeling of the Linked Data domain [Halpin,
Presutti 09]
8](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-8-2048.jpg)
![Keeping Linked Data connected
• network-shaped Entity Name System to enable
systematic reuse of URIs [Bouquet, Stoermer,
Cordioli, Tummarello 08]
• similar to DNS for interlinking hypertext
• n2Mate framework [Peterson, Cregan, Atkinson,
Brisbin 08]
• use social networking principles to facilitate
vocabulary and instance reuse
• graph-based disambiguation of Semantic Web
entities with idMesh [Cudré-Mauroux, Haghani,
Jost, Aberer, de Meer 09]
9](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-9-2048.jpg)
![Managing co-reference
• many conflated resources in DBpedia [Jaffri,
Glaser, Millard 08]
• representative of LOD as a whole
• Co-Reference Resolution Service [Glaser, Jaffri,
Millard 09]
• when co-reference is context-specific,
owl:sameAs is inappropriate
• stores co-reference information as a first-class
entity
• ontology-level alignment should precede data-level
alignment [Nikolov, Uren, Motta 09]
10](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-10-2048.jpg)
![Growing the data web
• how to get data out there?
• challenges of the read-write Semantic Web
• user awareness of social context of data (e.g.
licensing, privacy)
• view update problem
• is the wiki model applicable?
• incentives for posting data on the SW
• validating existing Linked Data with Vapour
[Berrueta, Fernandez, Frade 08]
11](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-11-2048.jpg)
![Examples of LOD data sets
• DBpedia [Auer, Bizer, Kobilarov, Lehmann,
Cyganiak, Ives 07]
• extracts structured information from Wikipedia
• linking hub for the LOD cloud
• RDF Book Mashup [Bizer, Cyganiak, Gauss 07]
• product metadata from Amazon.com
12](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-12-2048.jpg)
![Music and movies as Linked Data
• Linked Movie Database [Hassanzadeh, Consens 09]
• combines data from IMDb, Freebase, OMDB,
DBPedia, RottenTomatoes.com, Stanford Movie
Database
• interlinked music datasets [Raimond, Sutton,
Sandler 08]
• combines data from Jamendo on DBTune, BBC
John Peel sessions, SBSimilarity, Musicbrainz,
DBpedia, Geonames
• links artists, albums, tracks, personal music
collections
• generated links based similarity of resources,
similarity of neighbors
13](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-13-2048.jpg)
![Other sources of data
• the hypertext Web itself [Li, Zhao 08]
• extraction of semantic links from hypertext links and
hierarchical relationships among Web documents
• RDF representation of HTML DOM from using SparqPlug
[Coetzee, Heath, Motta 08]
• multimedia metadata
• interlinking multimedia fragments [Hausenblas, Troncy,
Bürger, Raimond 09]
14](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-14-2048.jpg)
![Other sources of data (cont.)
• XML Business Reporting Language (XBRL) [Garcia, Gil
09]
• mapping data to RDF and schemas to OWL
facilitates interoperability
• large thesauri [Neubert 09]
• as interlinking hubs for professional communities
• enterprise data, e.g. technical documentation [Servant
08]
• MARC21 bibliographic records [Styles, Ayers, Shabir
08]
15](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-15-2048.jpg)
![Mapping tools
• D2R Server for customizable mappings from
relational databases to ontologies [Bizer, Cyganiak
06]
• browser-based tools for defining RDB-to-RDF
mappings [Zhou, Xu, Chen, Idehen 08]
• Triplify [Auer, Dietzold, Lehmann, Hellmann,
Aumueller 09]
• from generic data silos to Linked Data using
OpenLink Data Spaces [Idehen, Erling 08]
16](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-16-2048.jpg)
![Aggregated resources
• Open Archives Initiative Protocol for Metadata
Harvesting (OAI-PMH)
• can be made Web-accessible with OAI2LOD
Server [Haslhofer, Schandl 08]
• Open Archives Initiative - Object Reuse and
Exchange (OAI-ORE) [Van de Sompel, Lagoze,
Nelson, Warner, Sanderson, Johnston 09]
• adheres to Web principles
17](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-17-2048.jpg)

![User-driven Linked Data (cont.)
• direct modification using SPARQL/Update
• e.g. in Tabulator [Berners-Lee, Hollenbach, Lu, Presbrey,
Prud’hommeaux, Schraefel 08]
• User Contributed Interlinking [Halb, Raimond, Hausenblas]
• semantic wikis
• Loomp [Roesch, Heese 09]
• semantic annotation of content using a text editor
interface
19](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-19-2048.jpg)
![User-driven Linked Data (cont.)
• public data from existing social networks
• wrappers for Web 2.0 services [Passant 08]
• unifying personal identity across various
networks [Rowe 09]
• Semantically Interlinked Online Communities
(SIOC)
• integrating social media sites (forums, blogs,
wikis, etc. with the data web [Bojars, Passant,
Cyganiak, Breslin 08]
• Meaning of a Tag (MOAT) ontology gives meaning
to tags on Web 2.0 [Passant, Laublet 08]
20](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-20-2048.jpg)
![Usability and licensing
• usability (for humans) of Linked Data [Halb,
Raimond, Hausenblas 08]
• current LOD datasets are primarily for machine
consumption
• low semantic strength of current LOD link sets
• provenance information for Linked Data [Hartig
09]
• Open Data Commons license [Miller, Styles, Heath
08]
21](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-21-2048.jpg)
![Indexing and searching
• W3C’s TAP semantic search [Guha, McCool 01]
• Swoogle [Ding, Finin, Joshi, Pan, Cost, Peng, Reddivari,
Doshi, Sachs 04]
• adapts PageRank concept to ontologies
• SWSE [Hogan, Harth, Umbrich, Decker 07]
• MultiCrawler [Harth, Umbrich, Decker 06]
• RDF Gateway search
• Watson document-based search
• Falcons [Cheng, Ge, Wu, Qu 08]
• textual search using class hierarchies for query restriction
• Sindice Semantic Web index [Tummarello, Delbru, Oren 07]
22](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-22-2048.jpg)
![Link discovery
• Silk link discovery framework [Volz, Bizer, Gaedke,
Kobilarov 09]
• find relationships between entities within
different data sources
• generation of owl:sameAs links
• value of Web of Data depends on the amount and
quality of links between data sources
23](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-23-2048.jpg)
![Navigation
• like early Web, it’s easy to get “Lost in Hyperspace”
• Tabulator generic Linked Data browser [Berners-
Lee, Chen, Chilton, Connolly, Dhanaraj,
Hollenbach, Lerer, Sheets 06]
• encourage deployment of Linked Data
• test, refine and promote Linked Data standards
• faceted views over large-scale linked data with
Virtuoso Cluster Edition [Erling 09]
• Explorator RDF browser [Araujo, Schwabe 09]
• exploratory search using direct manipulation
24](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-24-2048.jpg)
![Navigation (cont.)
• DBPedia Mobile map view and faceted Linked
Data browser [Becker, Bizer 08]
• explore the geospatial Semantic Web
• uses current GPS position as a starting point
• potential for Linked Data publishing
25](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-25-2048.jpg)
![Navigation (cont.)
• Fenfire generic Linked Data browser [Hastrup,
Cyganiak, Bojars 08]
• uses graph views rather than tables or outlines
• shows graph data as directly as possible
• related to Fentwine [Fallenstein, Lukka 04]
26](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-26-2048.jpg)
![Navigation (cont.)
• Humboldt [Kobilarov,
Dickinson 08]
• exploratory browsing
• faceted views
• “resource at a time”
• uses a “pivot” operation
to refocus the view
27](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-27-2048.jpg)
![Navigation (cont.)
• zLinks plugin [Bergman, Giasson 08]
• WordPress plugin with supporting server
• relates hypertext links with contextually
relevant Linked Data
• WOWY (WordNet, OpenCyc, Wikipedia, YAGO)
• distinguish between types of resources
• disambiguate alternate senses
28](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-28-2048.jpg)
![Navigation (cont.)
• mapping of Linked Data to a file system model
[Schandl 09]
• enables use of this data within desktop
applications
29](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-29-2048.jpg)
![Other applications
• how to use the data that is out there?
• emerging applications which exploit Linked
Data [Hausenblas 09]
• integrating data sources related to drug and
clinical trials [Jentzsch, Andersson, Hassanzadeh,
Stephens, Bizer 09]
• mashups
• MashQL [Jarrar, Dikaiakos 09]
• Internet is a database, mashup is a query
over that database
• benefit of specialized, independent Linked Data
services acting together [Bojars, Passant, Giasson,
Breslin 07]
30](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-30-2048.jpg)
![The gray area
• U-P2P framework for peer-to-peer linked data [Davoust,
Esfandiari 09]
• data replication provides a measure of popularity
• Linked Data with Named Graphs
• e.g. interlinks with embedded provenance information
[Zhao, Klyne, Shotton 08]
• Ripple scripting language [Shinavier 07]
• embeds Turing-complete programs in the Web of Data
31](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-31-2048.jpg)
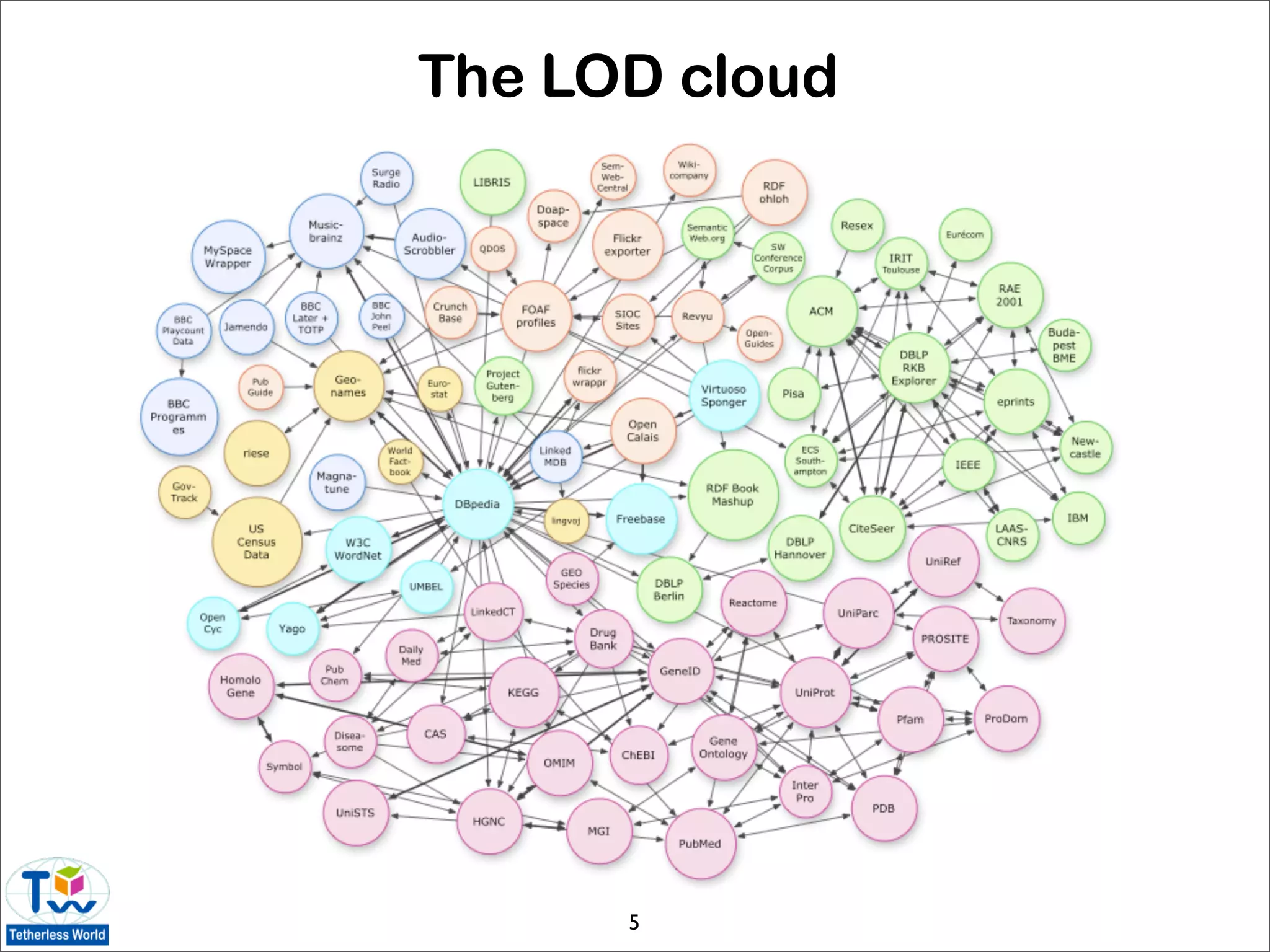
![State of the data web
• where are we with the Linked Data graph?
• size
• number and type of links
• usefulness to end users
• network characteristics
• single-point-of-access (e.g. DBpedia, GeoNames)
vs. distributed datasets (e.g. FOAF-o-sphere,
SIOC-land)
• syntactic and semantic analysis of the LOD
dataset [Hausenblas, Halb, Raimond, Heath 08]
32](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-32-2048.jpg)
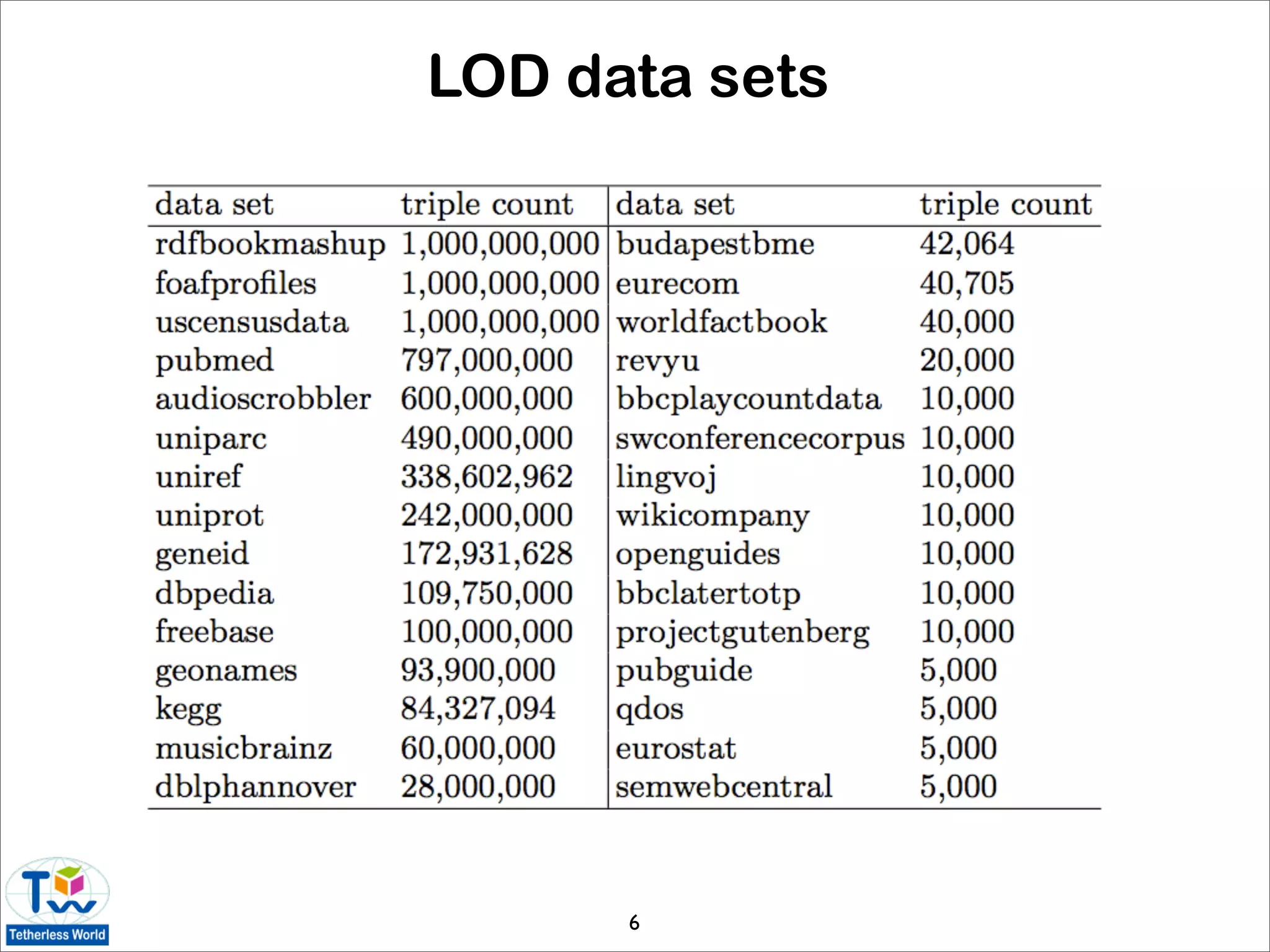
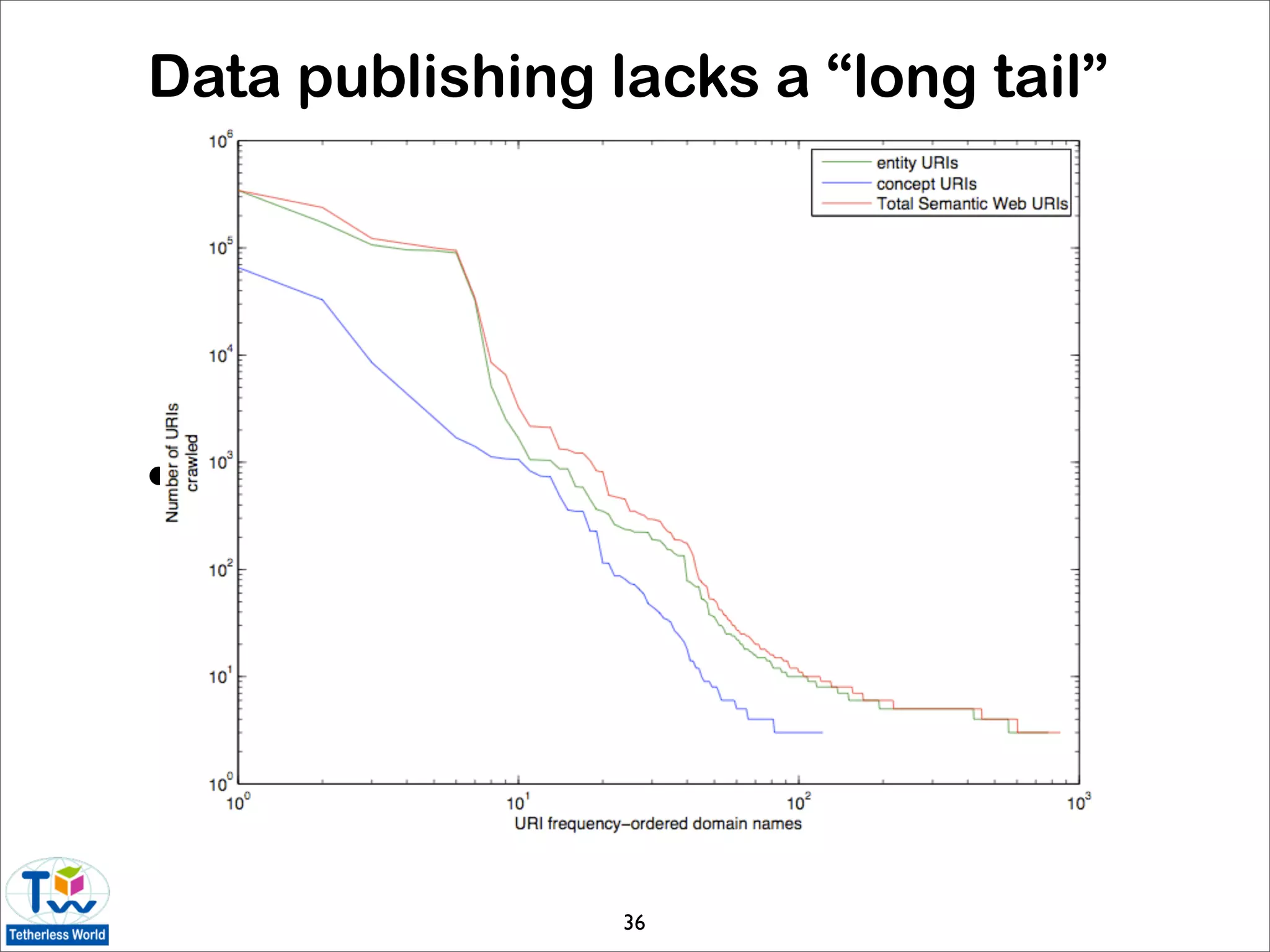
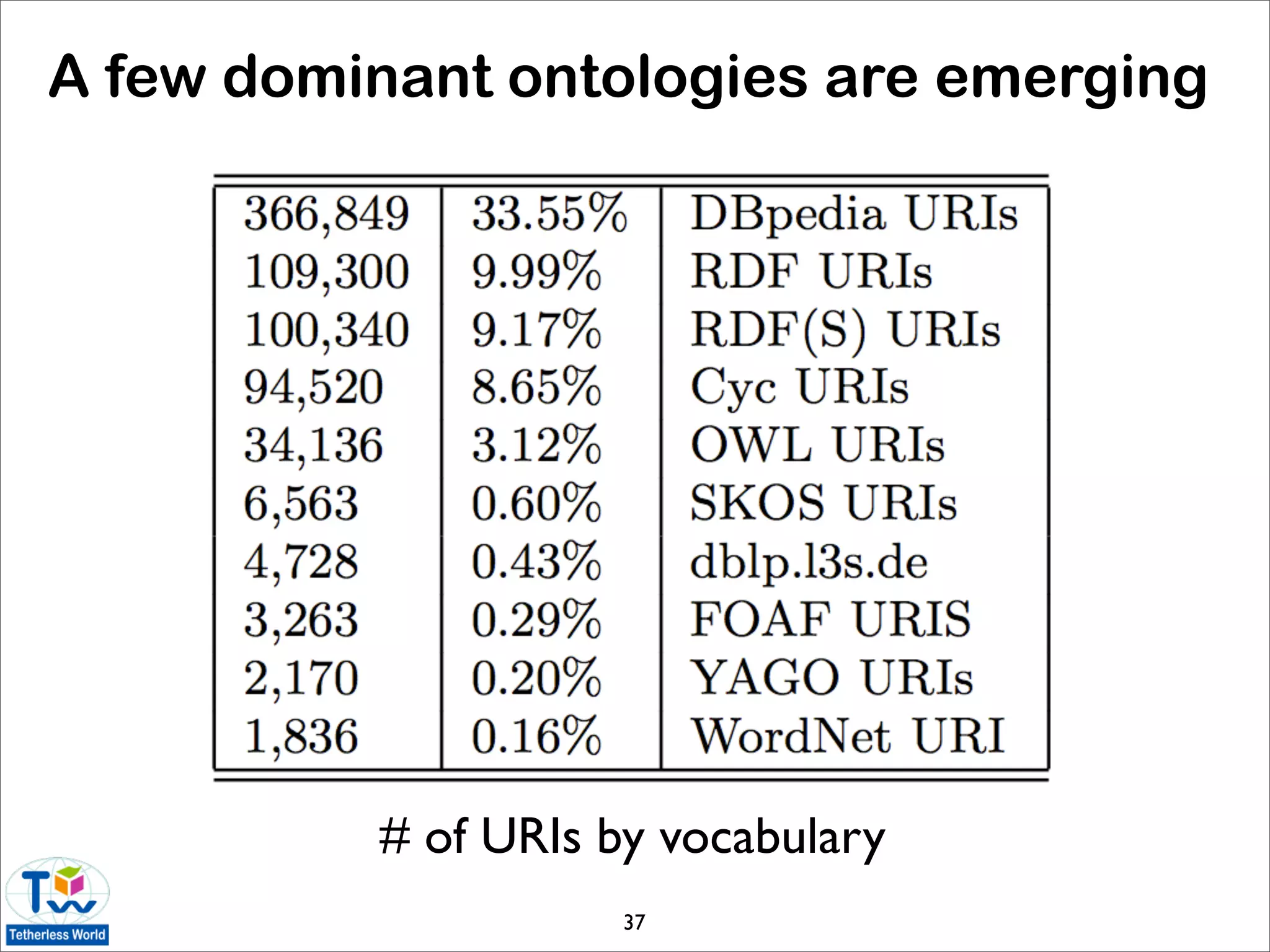
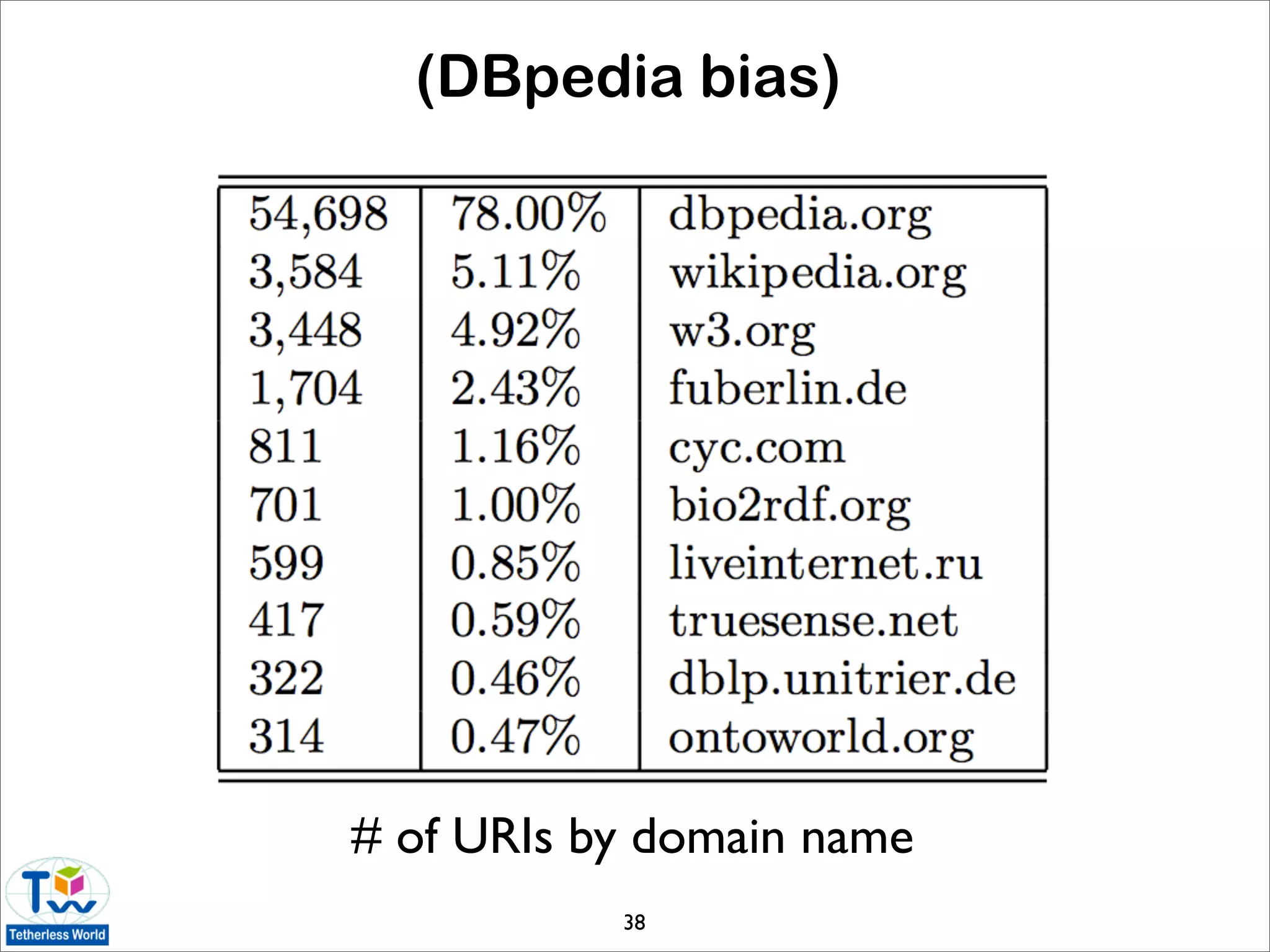
![Statistics of the data web
• today’s Linked Data is very different than the first-
generation data web [Halpin 09]
• LOD data accounts for the vast majority of data
• power-law distributions are emerging
• data web is not growing organically
• Web standards are generally adhered to
• is Linked Data useful to ordinary users?
• sampling of Linked Data using Live.com query
logs and FALCON-S semantic search engine
33](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-33-2048.jpg)
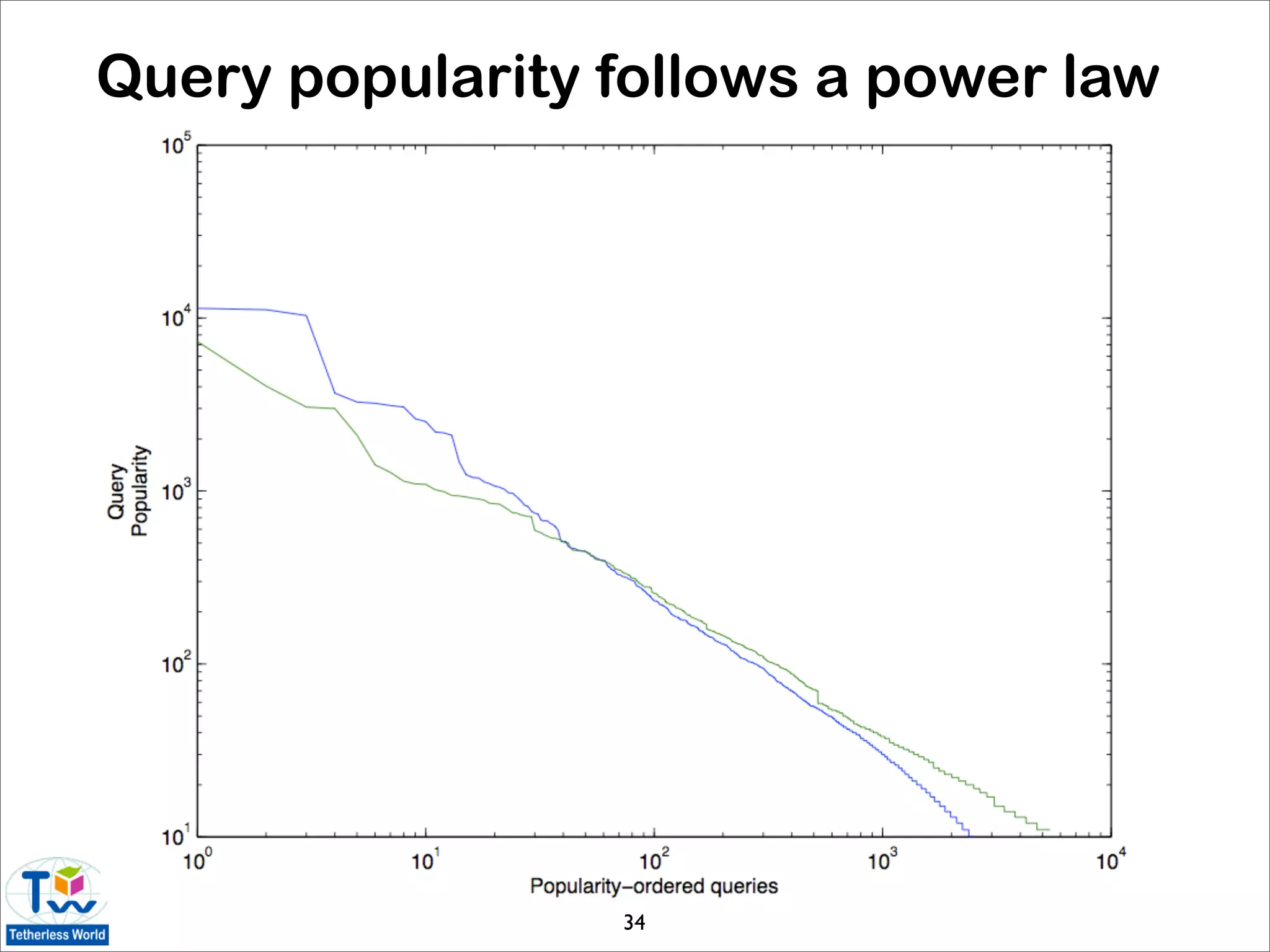
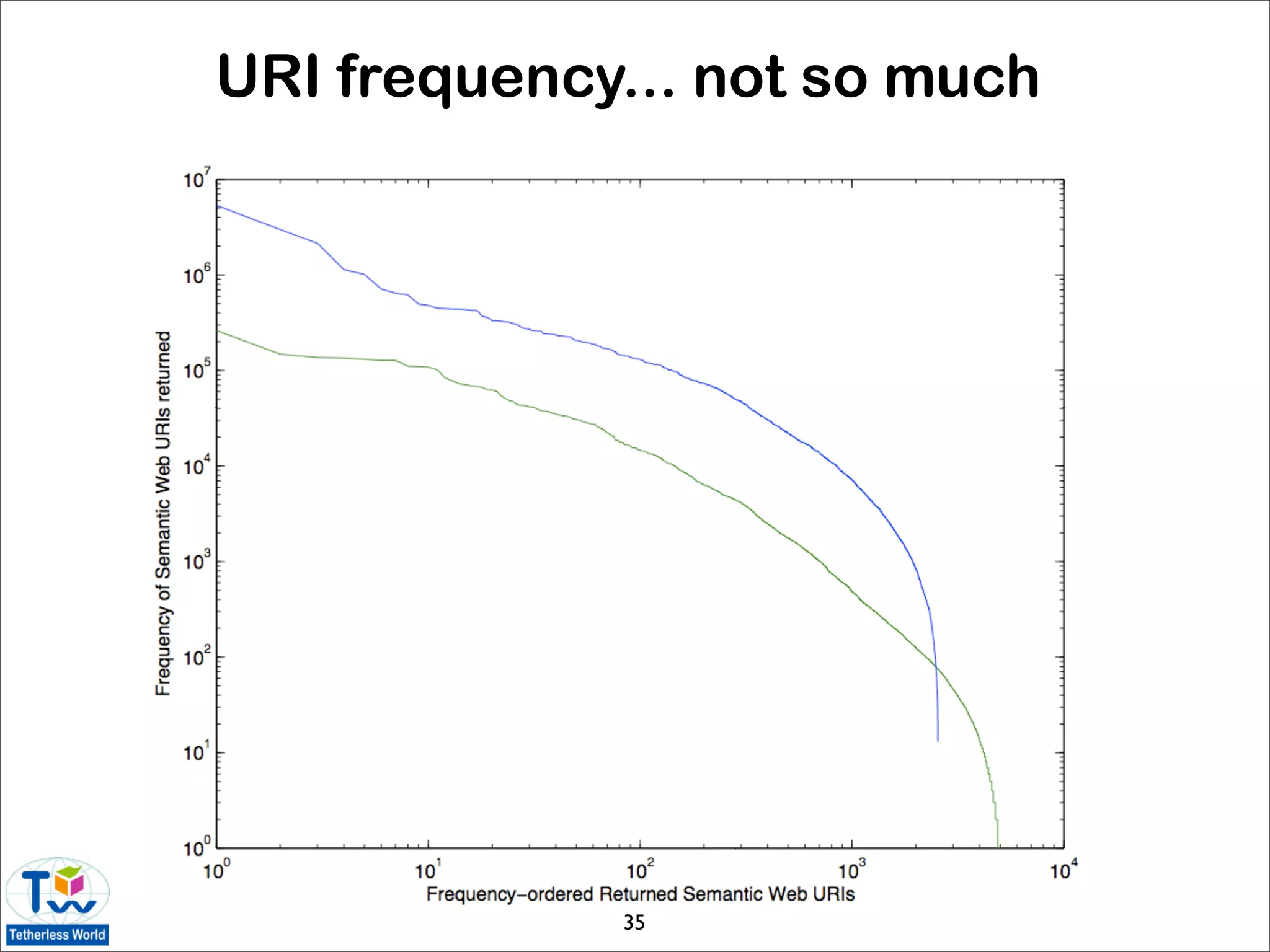
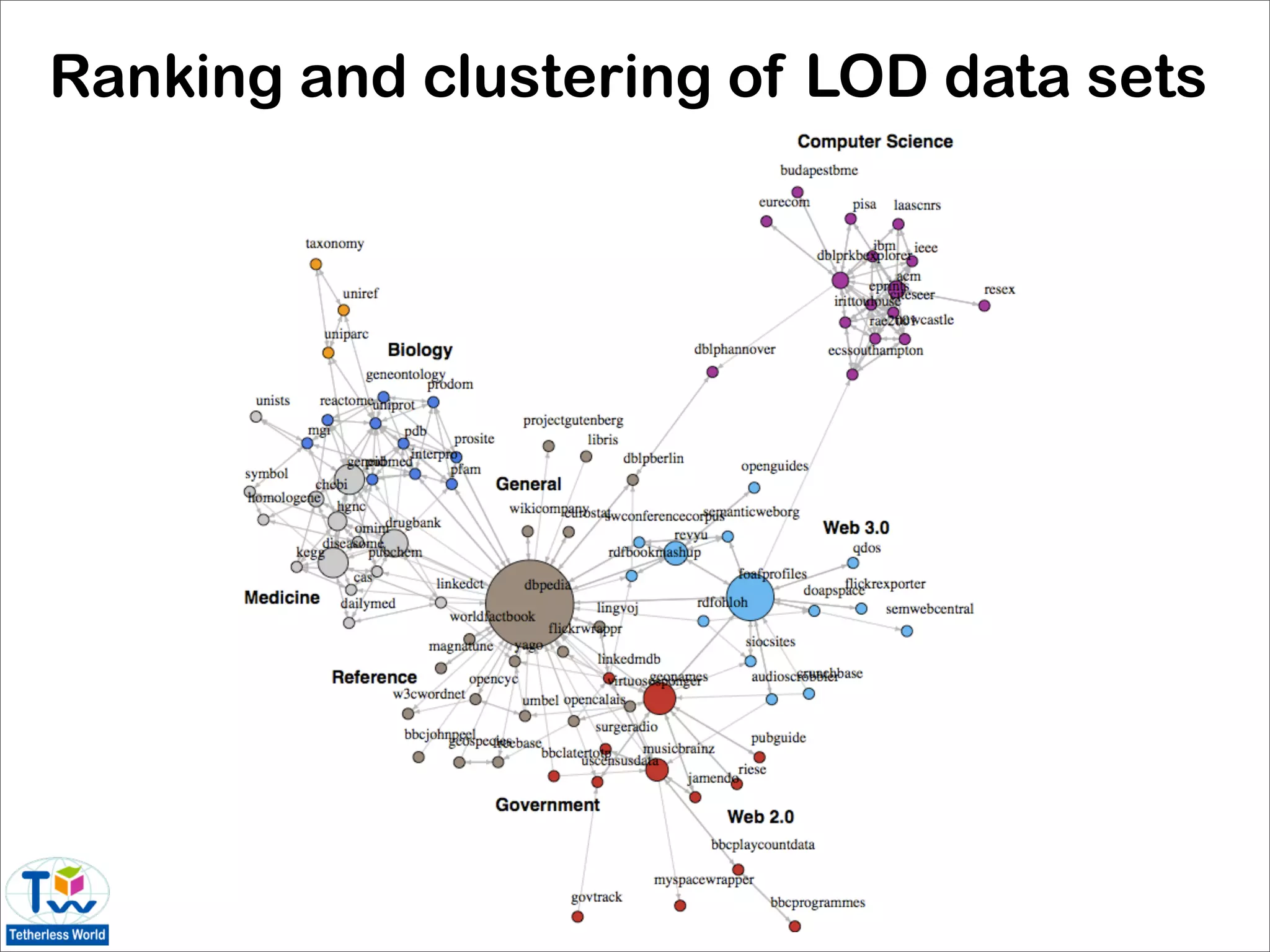
![Graph analysis for the data web
• common network analysis techniques can be used
to investigate interoperability and structural
patterns of the LOD cloud [Rodriguez 09]
• results based on March 2009 statistics of the LOD
data set graph:
• LOD graph is not strongly connected
• diameter of 8 is large given relatively small size
of the cloud
• data sets have nearly identical incoming and
outgoing link patterns (⇒ majority of reciprocal
owl:sameAs links)
39](https://image.slidesharecdn.com/linkeddatasurvey-100216122047-phpapp02/75/The-state-of-the-art-in-Linked-Data-39-2048.jpg)


This document provides an overview of the state of Linked Data and the Linking Open Data initiative. It describes key concepts like URIs, RDF, and the LOD cloud. It outlines datasets published as part of LOD and tools for mapping, indexing, searching, and navigating Linked Data. Statistics are presented on the size and structure of the LOD graph. The document concludes by discussing challenges in growing the data web and making Linked Data more usable and useful to end users.

















































































