Download to read offline








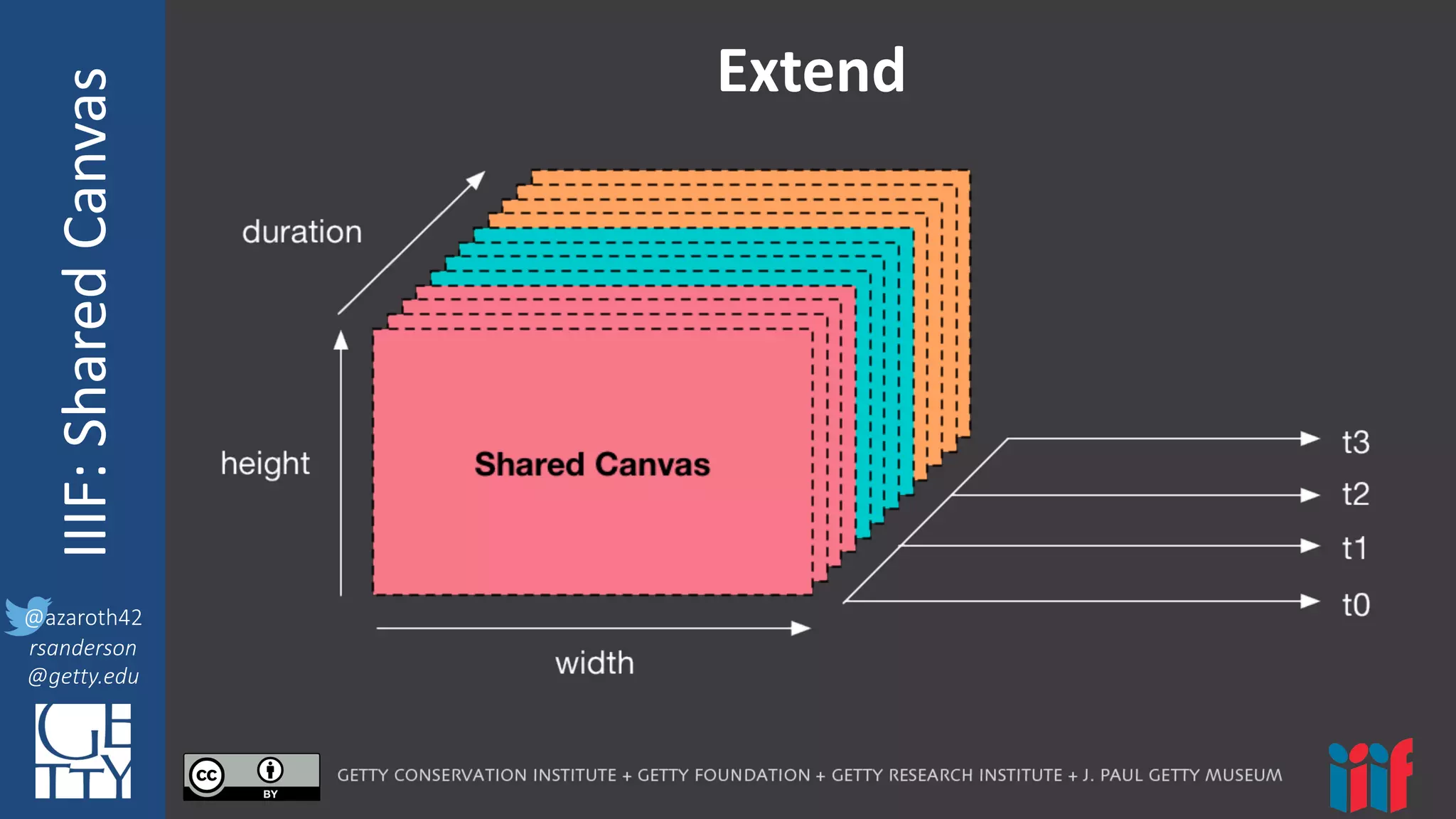
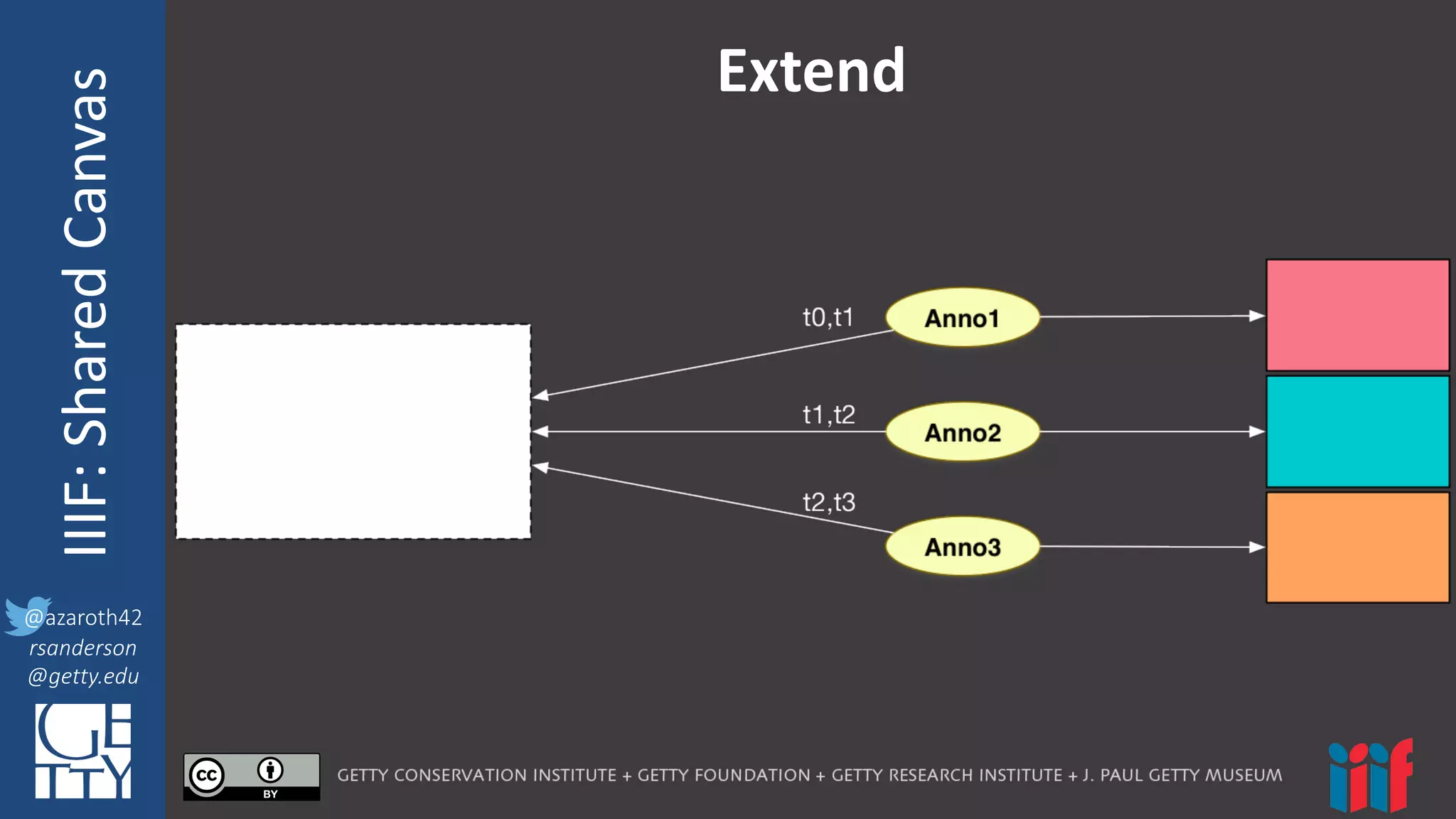




The document discusses updates and improvements to the IIIF Shared Canvas framework, emphasizing the need for synchronization between APIs and the underlying model. Key proposals include simplifying the model, adding new concepts for audio-visual content, and clarifying definitions and interactions. Additionally, it recommends deferring the implementation of 3D concepts until further experience is gathered.




























































































