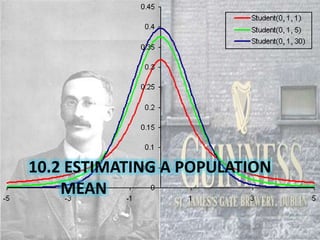
This document provides an overview of confidence intervals. It defines key terms like statistical inference, confidence level, and margin of error. It explains how to construct confidence intervals for means using the z-distribution when the population standard deviation is known, and using the t-distribution when it is unknown. It also covers how to estimate population proportions using the normal distribution. Examples are provided to demonstrate how to use the PANIC method to set up and calculate confidence intervals.








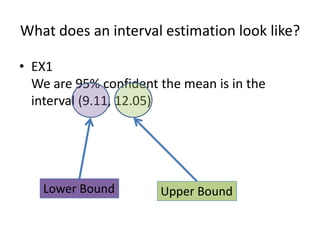


















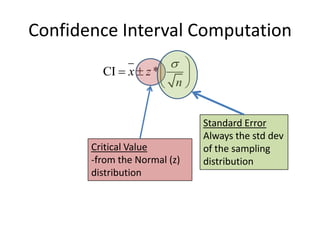

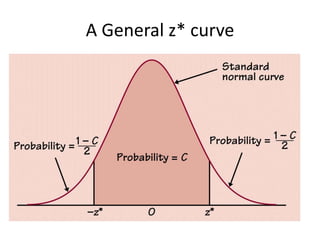
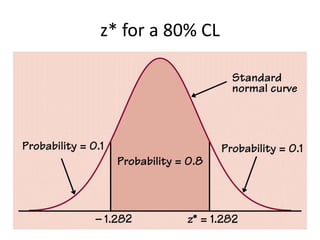




![Calculators TI83/TI84Your TI is very efficient for finding these intervals! This doesn’t excuse you from the mathematics, of course.[stat] -> “TESTS” -> “Zinterval”Inpt: “Stats” (if your data is in L1, you can use “Data”Enter values for , x-bar, n, and C-Level.Viola!](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-35-320.jpg)
![Calculators TI89Run the “Stats/List Editor” APP[2nd] -> [F2] (F7) -> “Zinterval”Input Method = “Stats”Choose Data if all the observations are in a ListEnter values for , x-bar, n, and C-Level.Viola!](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-36-320.jpg)




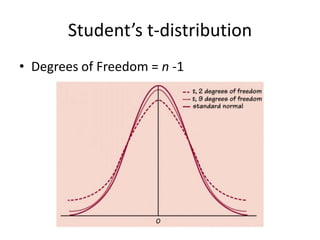


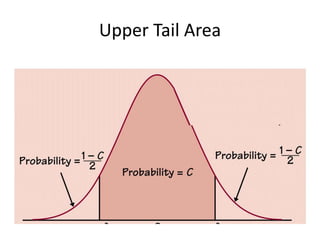
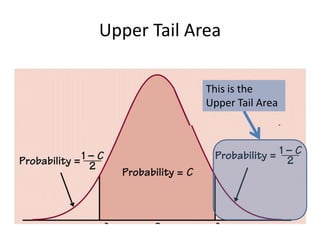

![Using the t-distributionUsing TI84 [2nd] -> [vars](DIST) -> “invT”“invT(1-Upper Tail Area, df)”Where “Upper Tail Area” = (1-CL)/2This is the area to the left of the right crit. Value.ALTERNATIVELY, you may use“−invT(Upper Tail Area, df)”](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-48-320.jpg)
![Using the t-distributionUsing TI84 [2nd] -> [vars](DIST) -> “invT”“invT(1-Upper Tail Area, df)”Where “Upper Tail Area” = (1-CL)/2This is the area to the left of the right crit. Value.ALTERNATIVELY, you may use“−invT(Upper Tail Area, df)”](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-49-320.jpg)
![Using the t-distributionUsing TI84 [2nd] -> [vars](DIST) -> “invT”“invT(1-Upper Tail Area, df)”Where “Upper Tail Area” = (1-CL)/2This is the area to the left of the right crit. Value.ALTERNATIVELY, you may use“−invT(Upper Tail Area, df)”Don’t forget the negative!](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-50-320.jpg)

![Using the t-distributionUsing TI89From home screen:[catalog] -> [F3](FlashApps) -> inv_t…TIStat“tistat.invT(1-Upper Tail Area, df)”Where “Upper Tail Area” = (1-CL)/2This is the area to the left of the right crit. Value.ALTERNATIVELY, you may use“-tistat.invT(Upper Tail Area, df)”](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-52-320.jpg)
![Using the t-distributionUsing TI89From home screen:[catalog] -> [F3](FlashApps) -> inv_t…TIStat“tistat.invT(1-Upper Tail Area, df)”Where “Upper Tail Area” = (1-CL)/2This is the area to the left of the right crit. Value.ALTERNATIVELY, you may use“-tistat.invT(Upper Tail Area, df)”](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-53-320.jpg)
![Using the t-distributionUsing TI89From home screen:[catalog] -> [F3](FlashApps) -> inv_t…TIStat“tistat.invT(1-Upper Tail Area, df)”Where “Upper Tail Area” = (1-CL)/2This is the area to the left of the right crit. Value.ALTERNATIVELY, you may use“-tistat.invT(Upper Tail Area, df)”Don’t forget the negative!](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-54-320.jpg)
![Using the t-distributionALTERNATIVE TI89 titanium[APPS] -> “Stat/List Editor” -> [F5] (distrib) -> “Inverse” -> “Inverse t…” “Area: 1- Upper Tail”Upper Tail = (1 – CL)/2“degrees of freedom, df: df”This takes longer to get to, but the menu “guides” you through](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-55-320.jpg)


















![TI83/84[stat] -> “TEST” -> “1-PropZInt”“x: number of successes” this can be computed with “p-hat x n”“n: number of people in sample”“C-Level : confidence level”“Calculate” and you are doneYou still need to fully write up “PANIC” procedures](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-75-320.jpg)

![TI 89[APPS] -> “Stat/List Editor”[2nd] -> [F2](F7) -> “1-PropZInt”“Successes x: # of successes”“n: number of people in sample”“C-Level : confidence level”“Calculate” and you are doneYou still need to fully write up “PANIC” procedures](https://image.slidesharecdn.com/statschapter10-110228112203-phpapp02/85/Stats-chapter-10-77-320.jpg)










































































