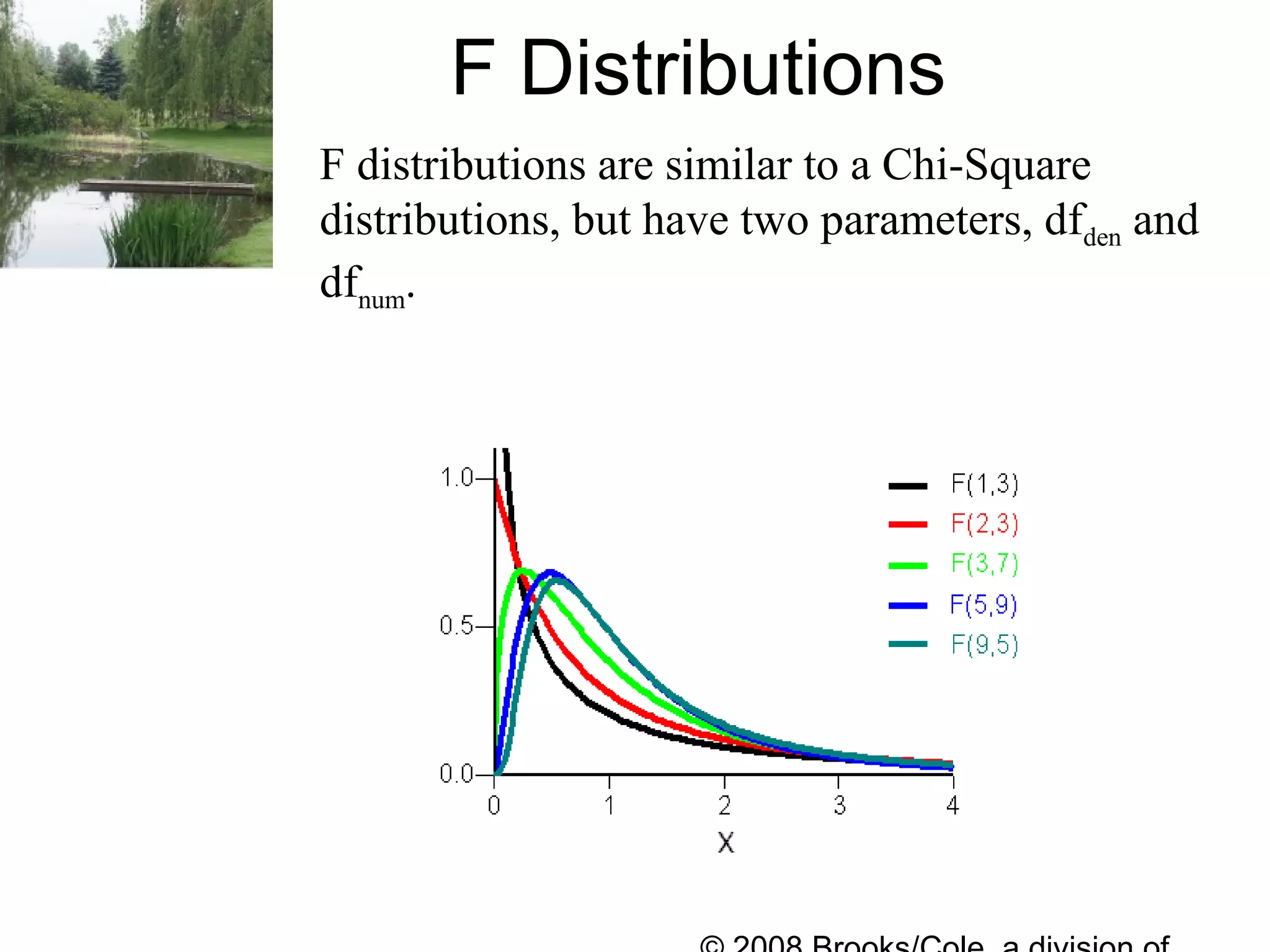
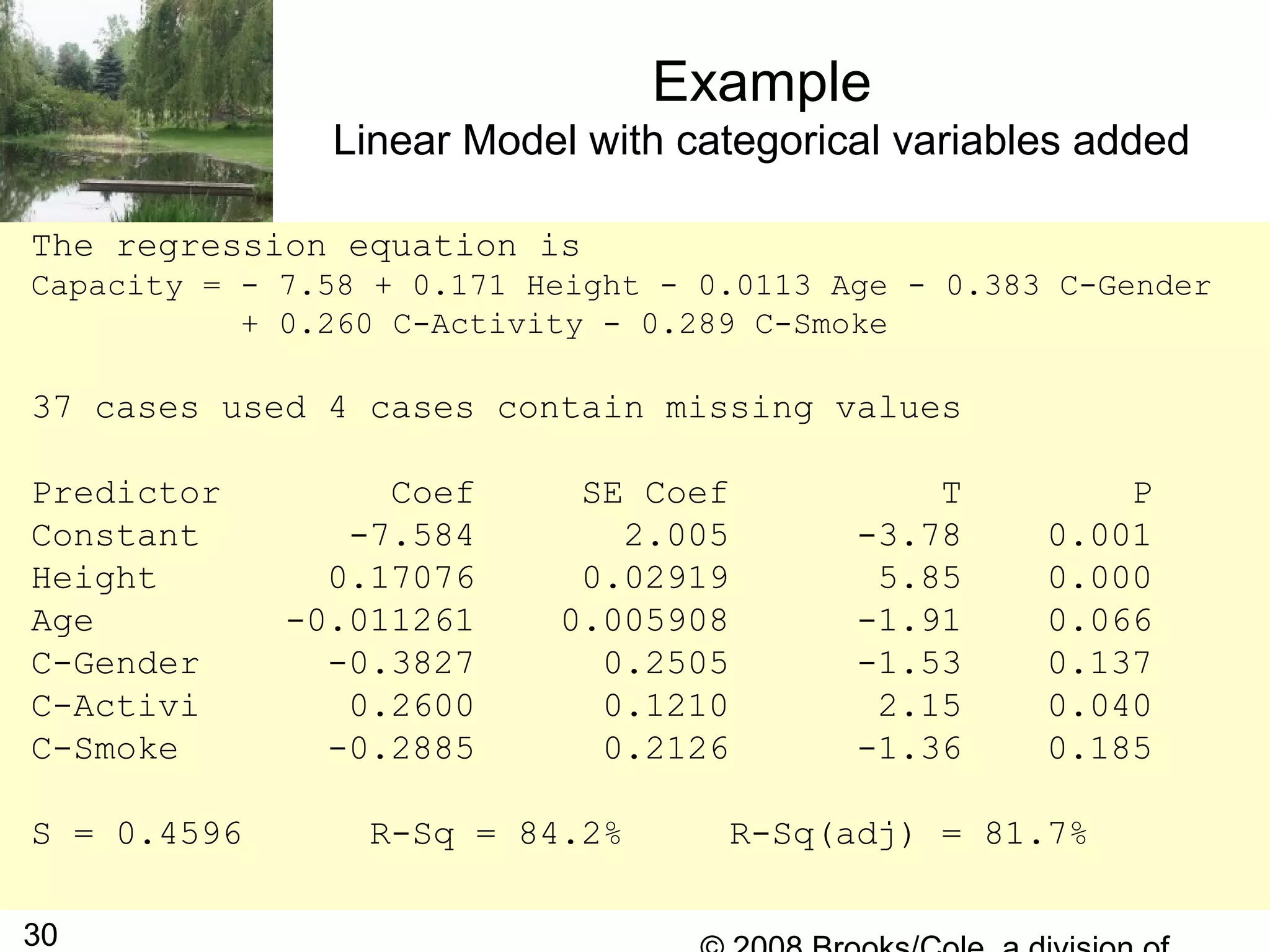
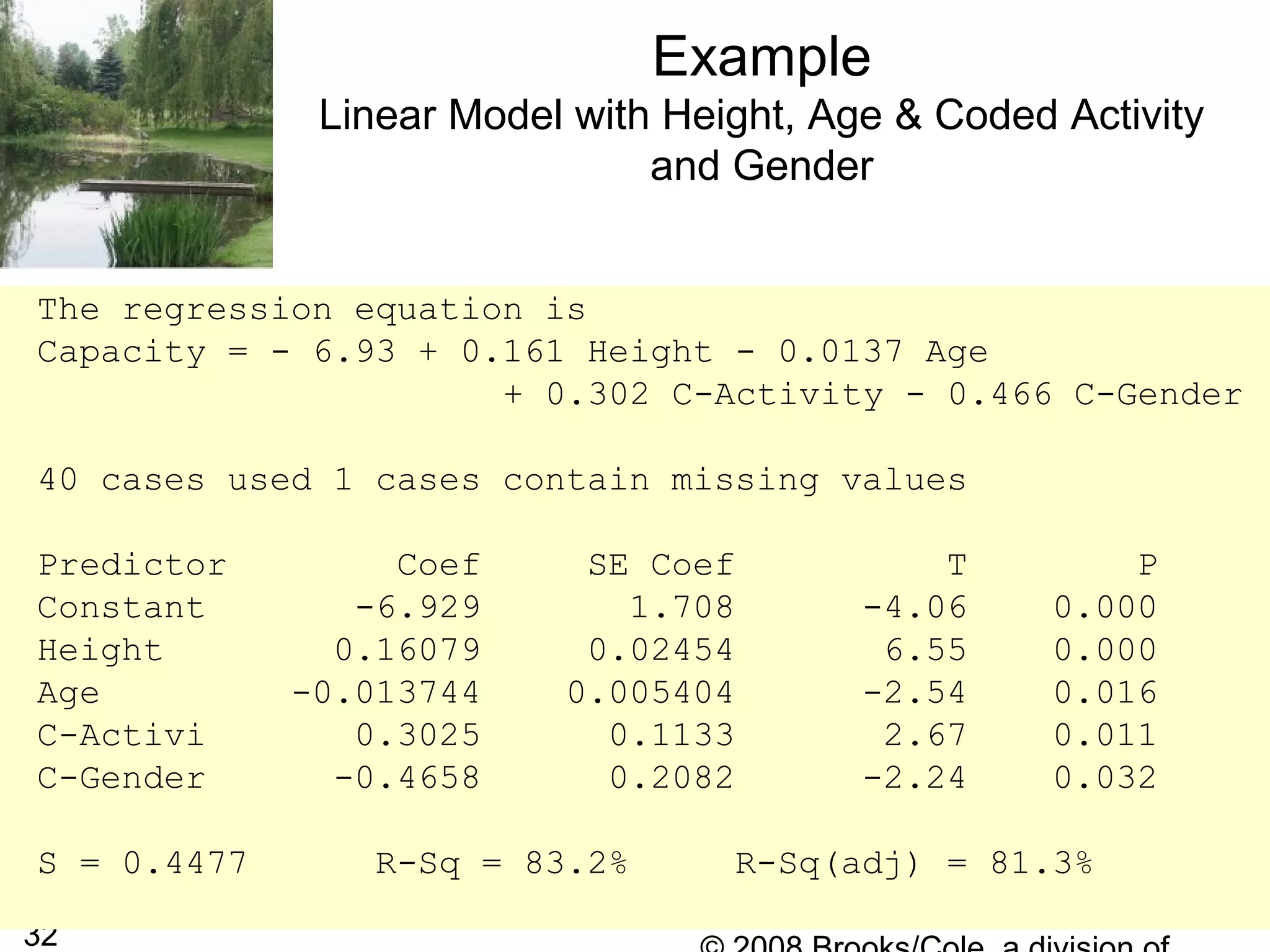
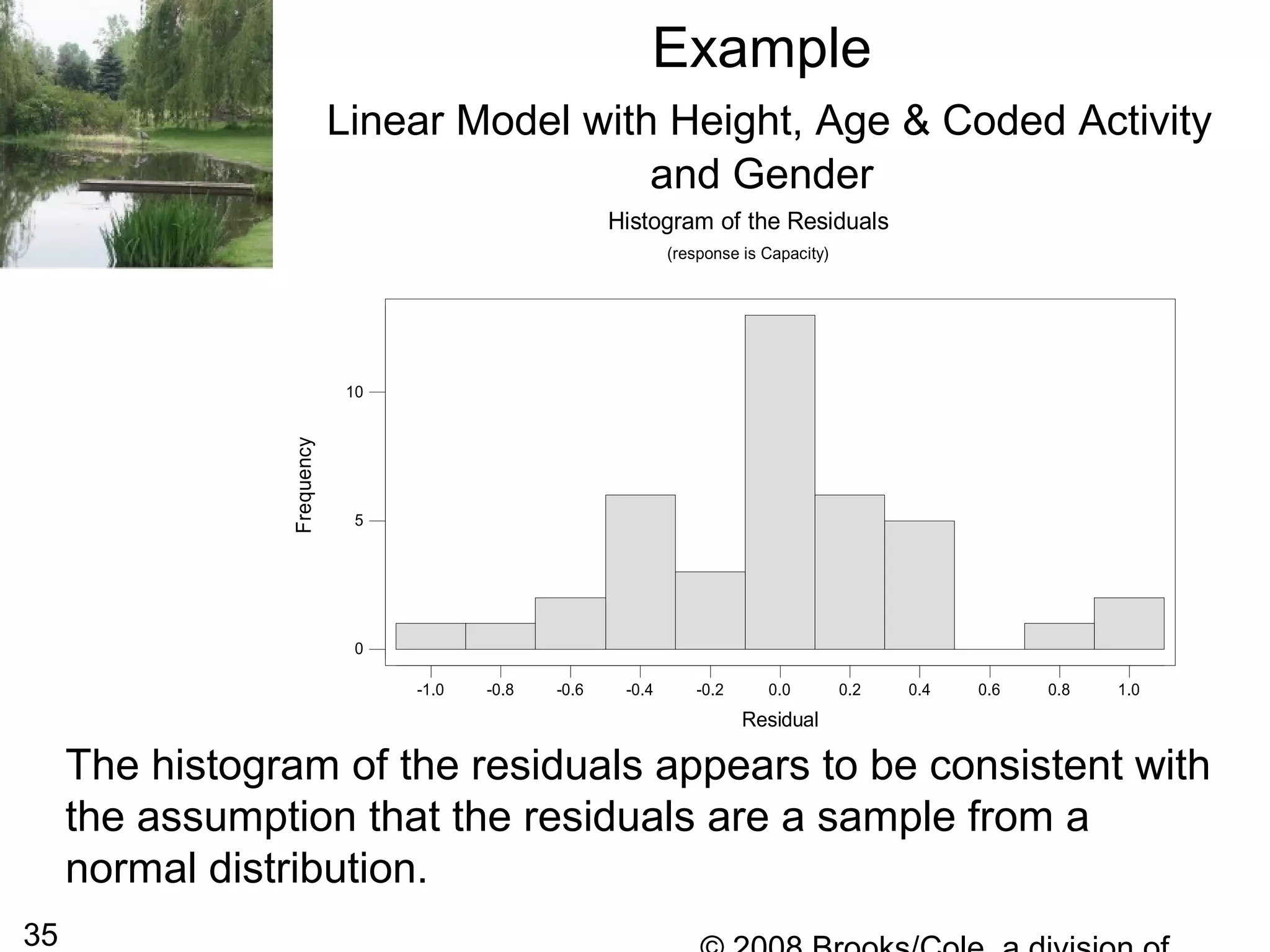
The document describes multiple regression models and their applications. It begins by defining a general multiple regression model that relates a dependent variable to multiple predictor variables. It then discusses key aspects of multiple regression models like regression coefficients, the regression function, polynomial regression models, and qualitative predictor variables. The document provides examples of applying multiple regression to model lung capacity based on variables like height, age, gender, and activity level. It describes building different regression models and evaluating their fit and significance.









![10
According to the principle of least squares,
the fit of a particular estimated regression
function a + b1x1 + b2x2 + … + bkxk to the
observed data is measured by the sum of
squared deviations between the observed y
values and the y values predicted by the
estimated function:
Σ[y –(a + b1x1 + b2x2 + … + bkxk )]2
Least Square Estimates
The least squares estimates of α, β1, β2,…, βk are
those values of a, b1, b2, … , bk that make this sum of
squared deviations as small as possible.](https://image.slidesharecdn.com/4mzcvhvzs8crhgnzx4o8-signature-7fbda3c2c0a8559944996f0c007e41f1da8dd3bd9ae740e99209c79d075fc765-poli-140819110159-phpapp01/75/Chapter14-10-2048.jpg)