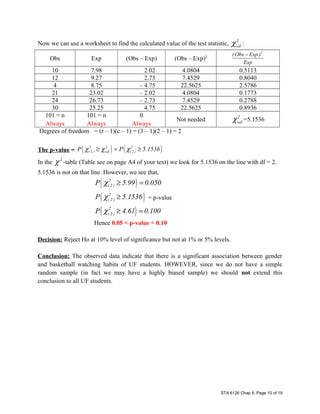
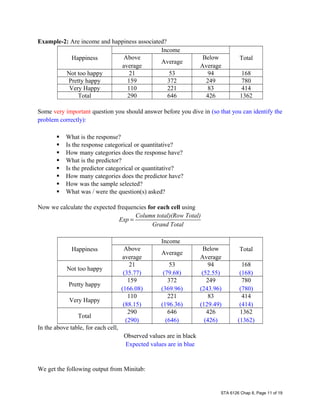
This document provides an overview of three Chi-Square tests: goodness-of-fit tests, tests of homogeneity, and tests of independence. Goodness-of-fit tests compare observed data to expected data based on a hypothesized distribution with one or more categories. Tests of homogeneity compare observed data across multiple populations to determine if they have the same distribution. Tests of independence examine the relationship between two categorical variables to determine if they are independent. All three tests use a Chi-Square test statistic and follow similar procedures: define hypotheses, calculate expected values, compare to observed values, and determine statistical significance. Examples are provided to illustrate how to set up and conduct each type of test.








![Conditional Distribution of Response
Watched?
Gender
Total
Male Female
Whole game
38.5%
(10/26)
28.0%
(21/75)
30.7%
(31/101)
Part of Game
46.2%
(12/26)
32.0%
(24/75)
35.6%
(36/101)
None
15.4%
( 4/26)
40.0%
(30/75)
33.7%
(34/101)
Total
100.0%
(26/26)
100.0%
(75/75)
100.0%
(101/101)
In the above table, we see that male students watched more of the
game than the females.
Can we extend this to the whole population of males and the whole
population of females?
The above data are from a sample.
In order to extend the findings to the whole populations of male and female UF students we need
to check if the following are satisfied:
Data should be a SRS from the population of interest (Do you think that is the case?)
If we can assume so, then we need to carry out a test of significance, to see if the
differences are strong enough to extend to the populations.
We will carry out a test of independence of the two variables (vs. not independence or no
association). [Why?]
If the two variables (gender and game watching) are independent of each other,
Then we would expect to see the same percentage distribution of response for both genders.
Thus we will have the following table of expected frequencies in each cell calculated by
assuming that the two variables are independent of each other.
Expected frequencies (Assuming independence)
Watched?
Gender
Total
Male Female
Whole
game
8
(26×0.307)
23
(75×0.307)
31/101
= 30.7%
Part of
Game
9
(26×0.356)
27
(75×0.356)
36/101
=35.6%
None
9
(26×0.337)
25
(75×0.337)
34/101
= 33.7%
Total 26 75 101
Expected frequencies are calculated using
( ) ( )
( )
Column Total Row Total
Exp
Grand Total
×
=
STA 6126 Chap 8, Page 8 of 19](https://image.slidesharecdn.com/chi-squaretests-140809003349-phpapp02/85/Chi-square-tests-8-320.jpg)