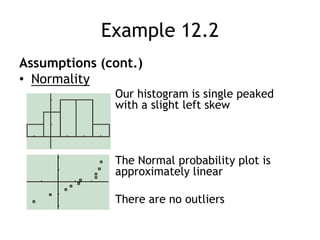
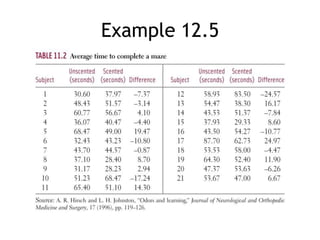
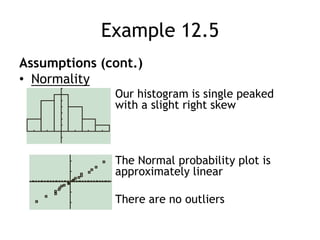
This document discusses significance tests for population means and proportions using Student's t-distribution and the normal distribution. It provides examples of hypothesis testing for a population mean using a paired t-test and for a population proportion using a single-sample z-test. It also discusses the assumptions, test statistics, and interpretations for these tests. Confidence intervals are presented as complementary to significance tests for estimating population parameters.
















































![Calculator UsageTI83/84: Since these functions are menu driven we will just list the tests and their usage [STAT] -> “TESTS”Z-Test = one or two tailed z test for meanT-Test = one or two tail t-test for means1-PropZTest = one or two tail test for proportionsZInterval = confidence interval for mean (-known)Tinterval = confidence interval for mean (-unknown)1-PropZInt = confidence interval for proportions](https://image.slidesharecdn.com/statschapter12-110327005842-phpapp01/85/Stats-chapter-12-51-320.jpg)




































































