Downloaded 478 times












![Why are you storing the data?
• So what kind of questions are you asking the data?
• Entity-centric questions
• Give me everything about entity e
• Give me the most recent event v about entity e
• Give me the n most recent events V about entity e
• Give me all events V about e between time [t1,t2]
• Event and Time-centric questions
• Give me an aggregates on each entity between time [t1,t2]
• Give me an aggregate on each time interval for entity e
• Find events V that match some other given criteria
5/5/14 HBaseCon 2014; Lars George,
Jon Hsieh
14](https://image.slidesharecdn.com/casestudies-session7-140616154309-phpapp02/85/A-Survey-of-HBase-Application-Archetypes-14-320.jpg)








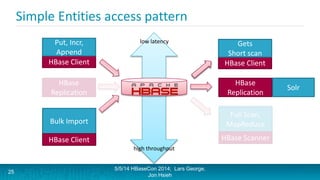


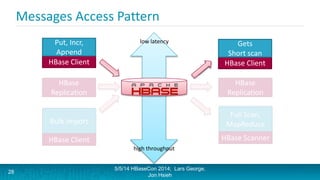

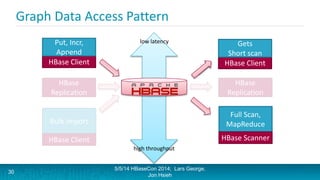

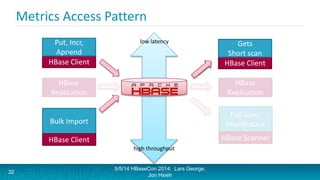




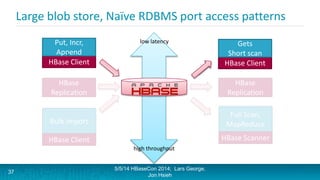


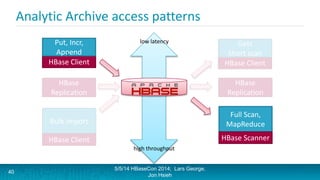





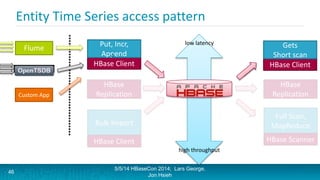

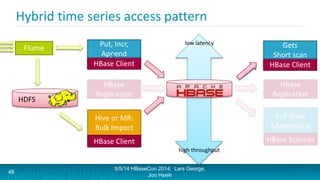

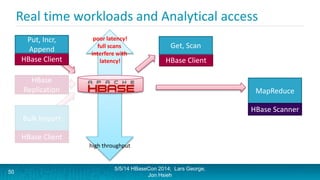
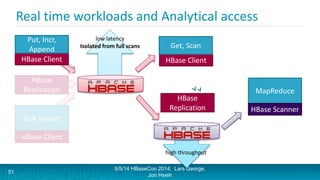

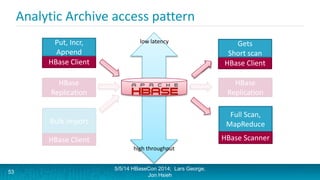
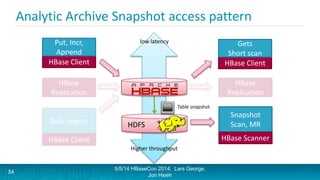
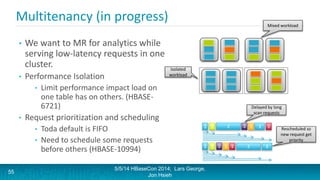

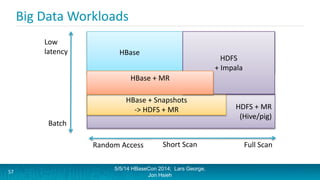
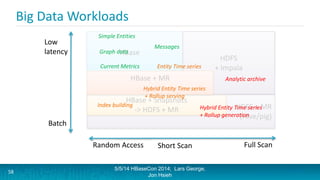



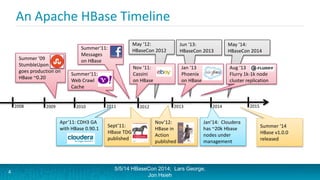
Lars George and Jon Hsieh presented archetypes for common Apache HBase application patterns. They defined archetypes as common architecture patterns extracted from multiple use cases to be repeatable. The presentation covered "good" archetypes that are well-suited to HBase's capabilities, such as storing simple entities, messaging data, and metrics. "Bad" archetypes that are not optimal fits for HBase included using it as a large blob store, naively porting a relational database schema, and as an analytic archive requiring frequent full scans. A discussion of access patterns and tradeoffs concluded the overview of HBase application archetypes.











































































































