NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
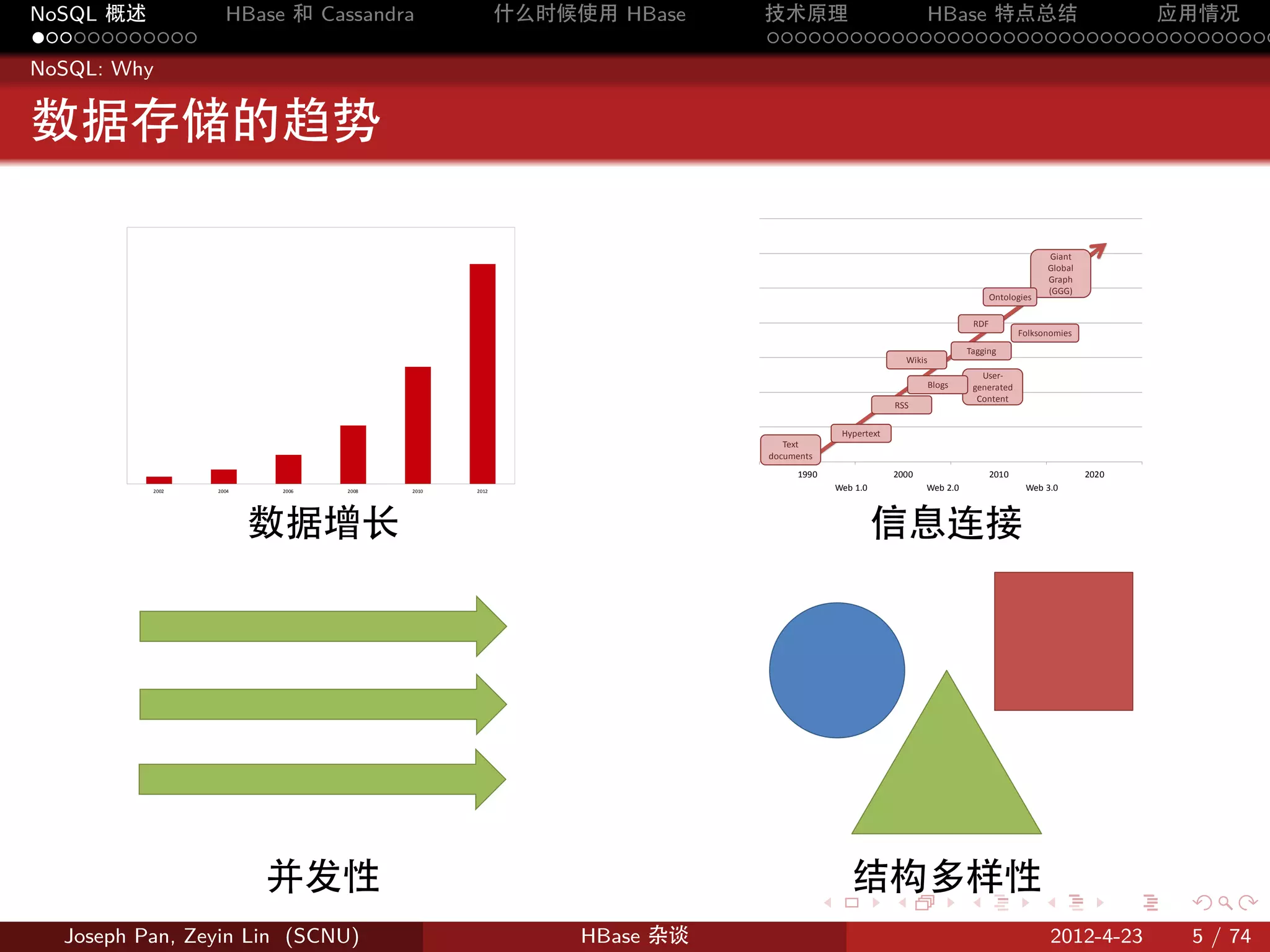
NoSQL: What
NoSQL 的定义
No to SQL No Only SQL
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 8 / 74
9.
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
NoSQL: What
Martin Fowler 的定义
.
NosqlDefinition
.
“Some characteristics are common amongst
these databases, but none are definitional.
Not using the relational model (nor the
SQL language)
Open source
Designed to run on large clusters
Based on the needs of 21st century web
properties
No schema, allowing fields to be added Figure 2: Martin Fowler
to any record without controls ”
.
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 9 / 74
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
数据模型
构造函数
./src/main/java/org/apache/hadoop/hbase/keyvalue.java:
§
p u b l i c KeyValue ( f i n a l b y t e [ ] row , f i n a l b y t e [ ] f a m i l y , f i n a l by t e [ ]
q u a l i f i e r , f i n a l l o n g timestamp , f i n a l b y t e [ ] v a l u e )
{
t h i s ( row , f a m i l y , q u a l i f i e r , timestamp , Type . Put , v a l u e ) ;
}
p u b l i c KeyValue ( f i n a l b y t e [ ] row , f i n a l i n t r o f f s e t , f i n a l i n t r l e n g t h
, f i n a l by t e [ ] f a m i l y , f i n a l i n t f o f f s e t , f i n a l i n t f l e n g t h ,
f i n a l by t e [ ] q u a l i f i e r , f i n a l i n t q o f f s e t , f i n a l i n t q l e n g t h ,
f i n a l l o n g timestamp , f i n a l Type type ,
f i n a l byte [ ] value , f i n a l i n t v o f f s e t , f i n a l i n t vlength ) {
t h i s . b y t e s = c r e a t e B y t e A r r a y ( row , r o f f s e t , r l e n g t h ,
family , f o f f s e t , flength , q u a l i f i e r , q o f f s e t , qlength ,
timestamp , type , v a l u e , v o f f s e t , v l e n g t h ) ;
t h i s . length = bytes . length ;
this . o f f s e t = 0;
}
¥
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 28 / 74
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
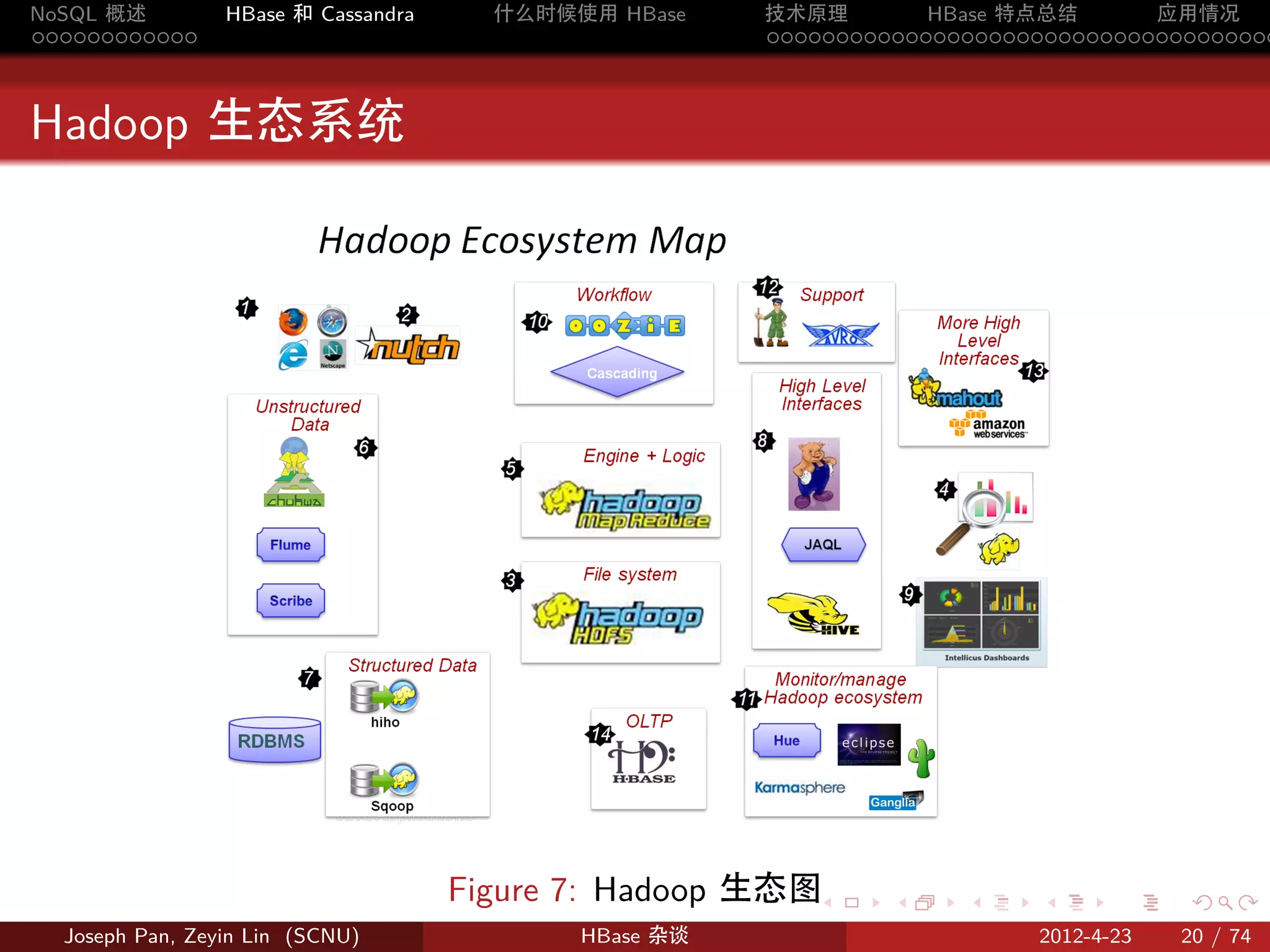
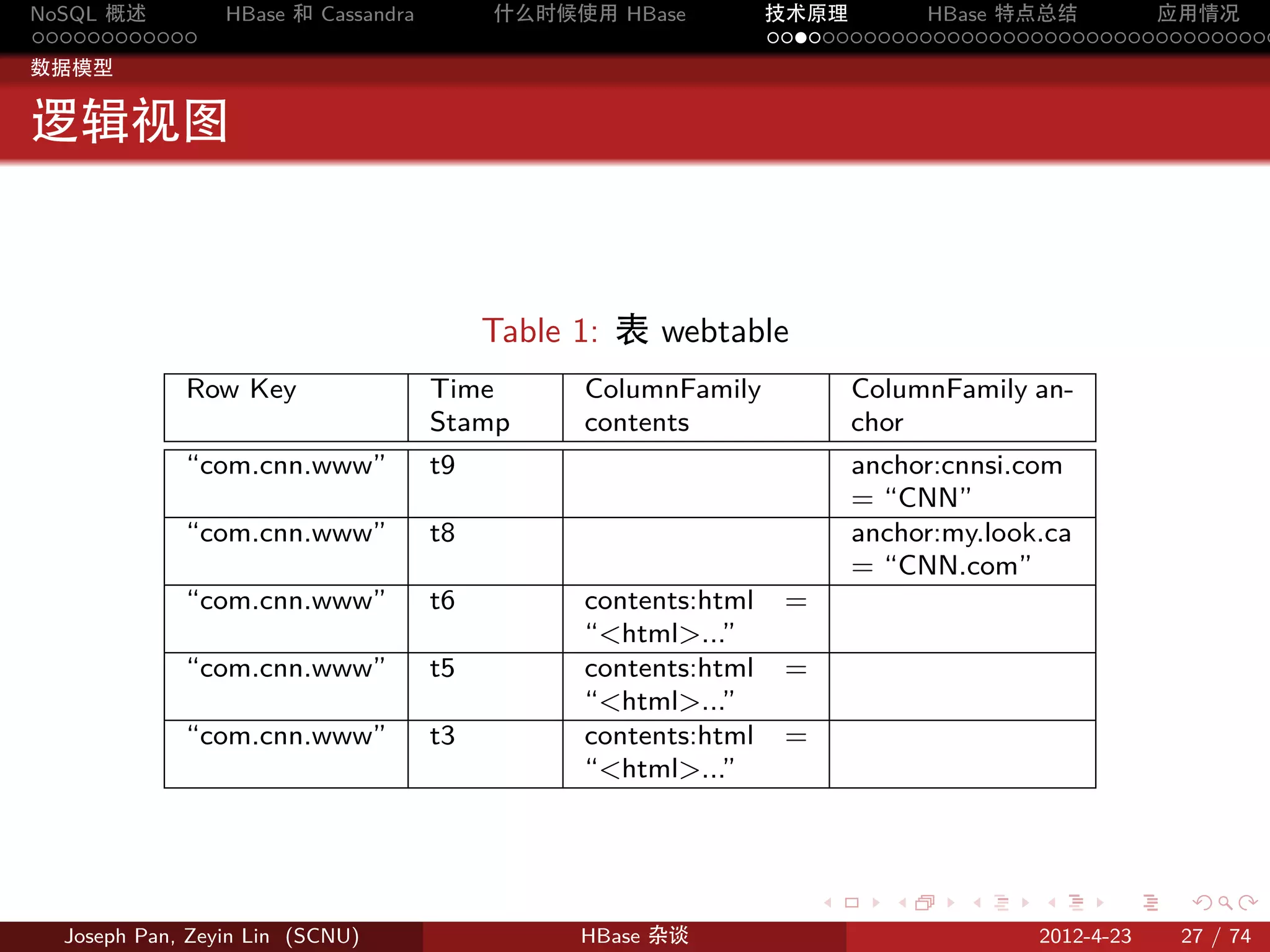
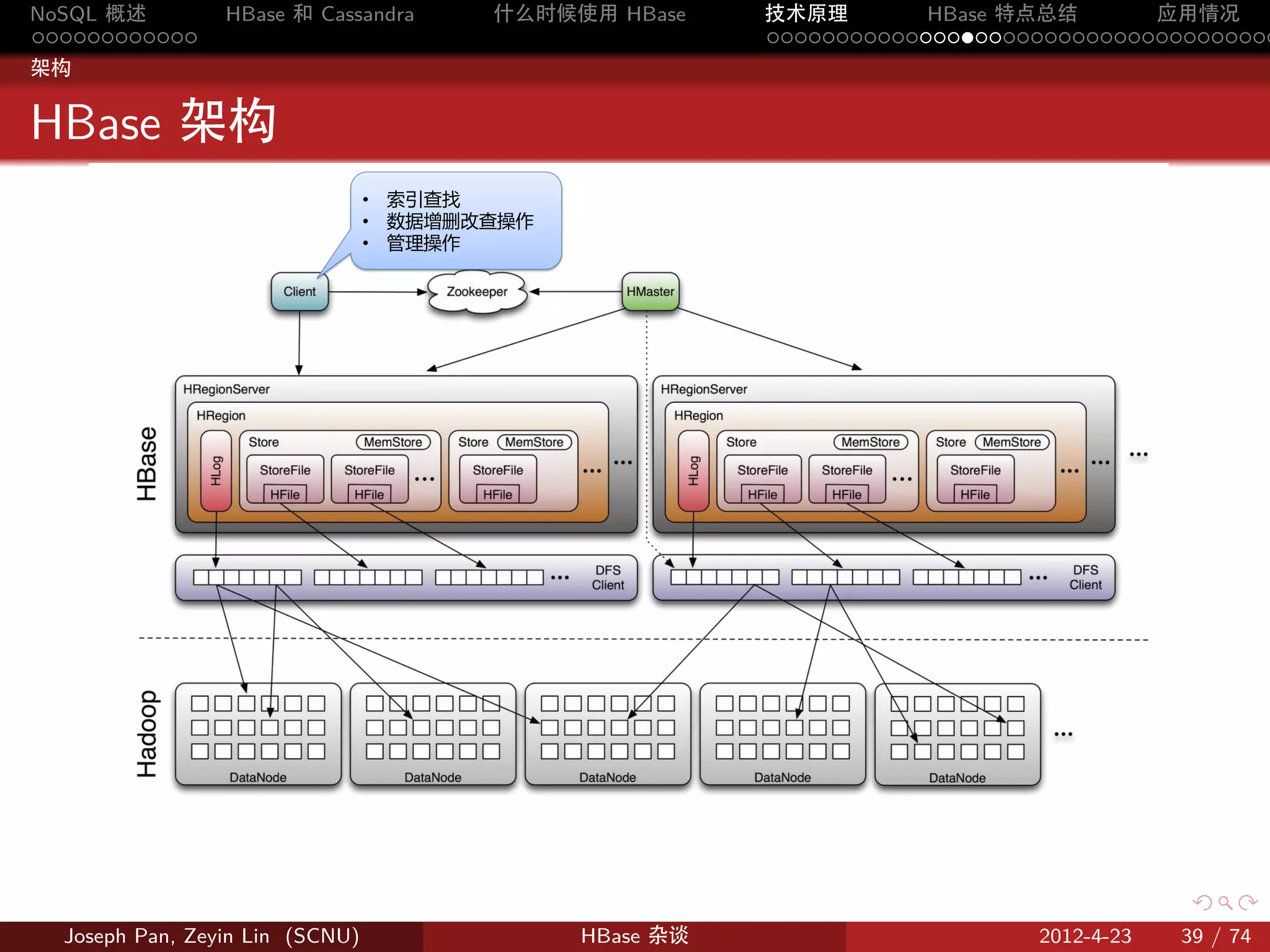
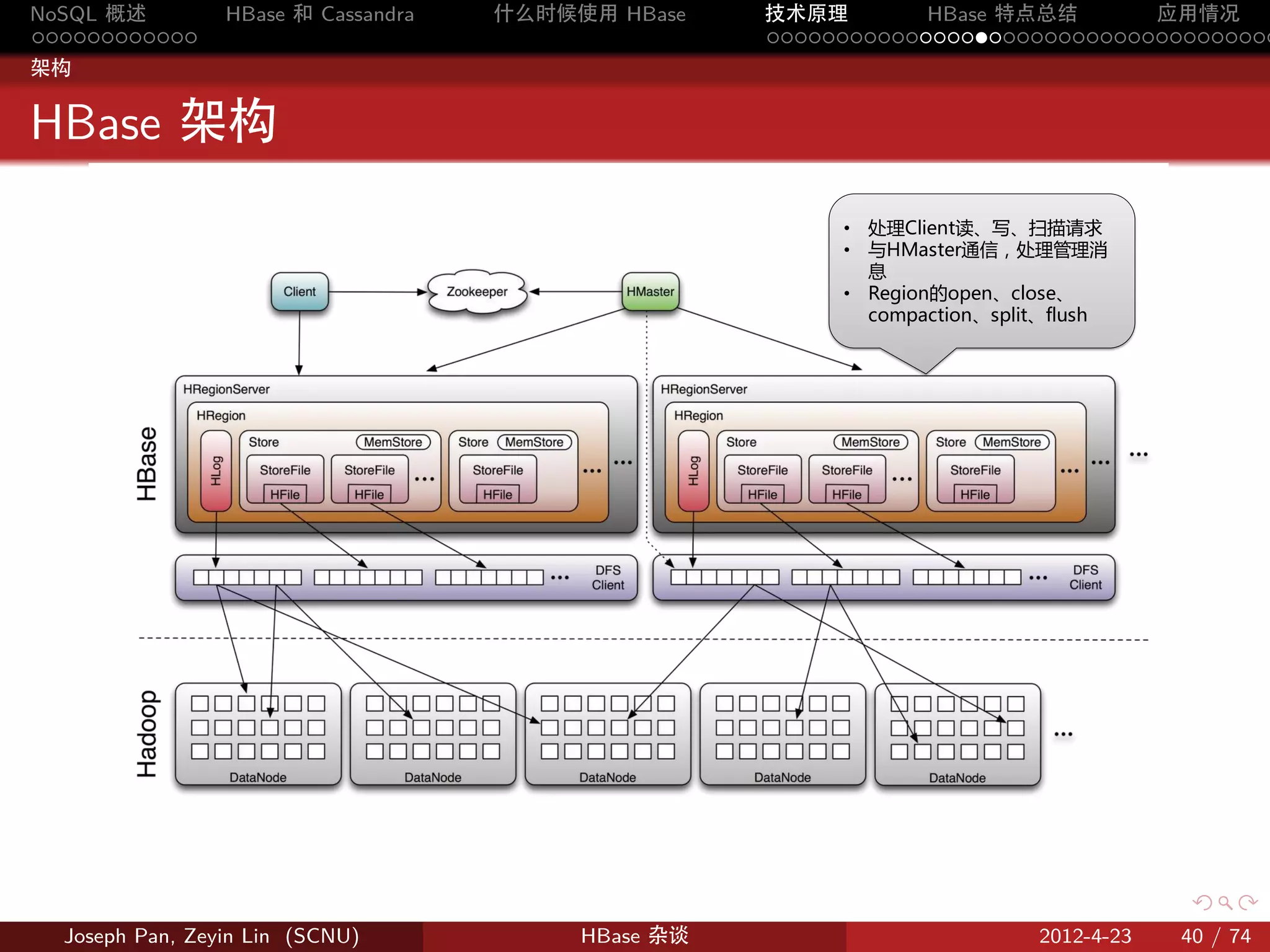
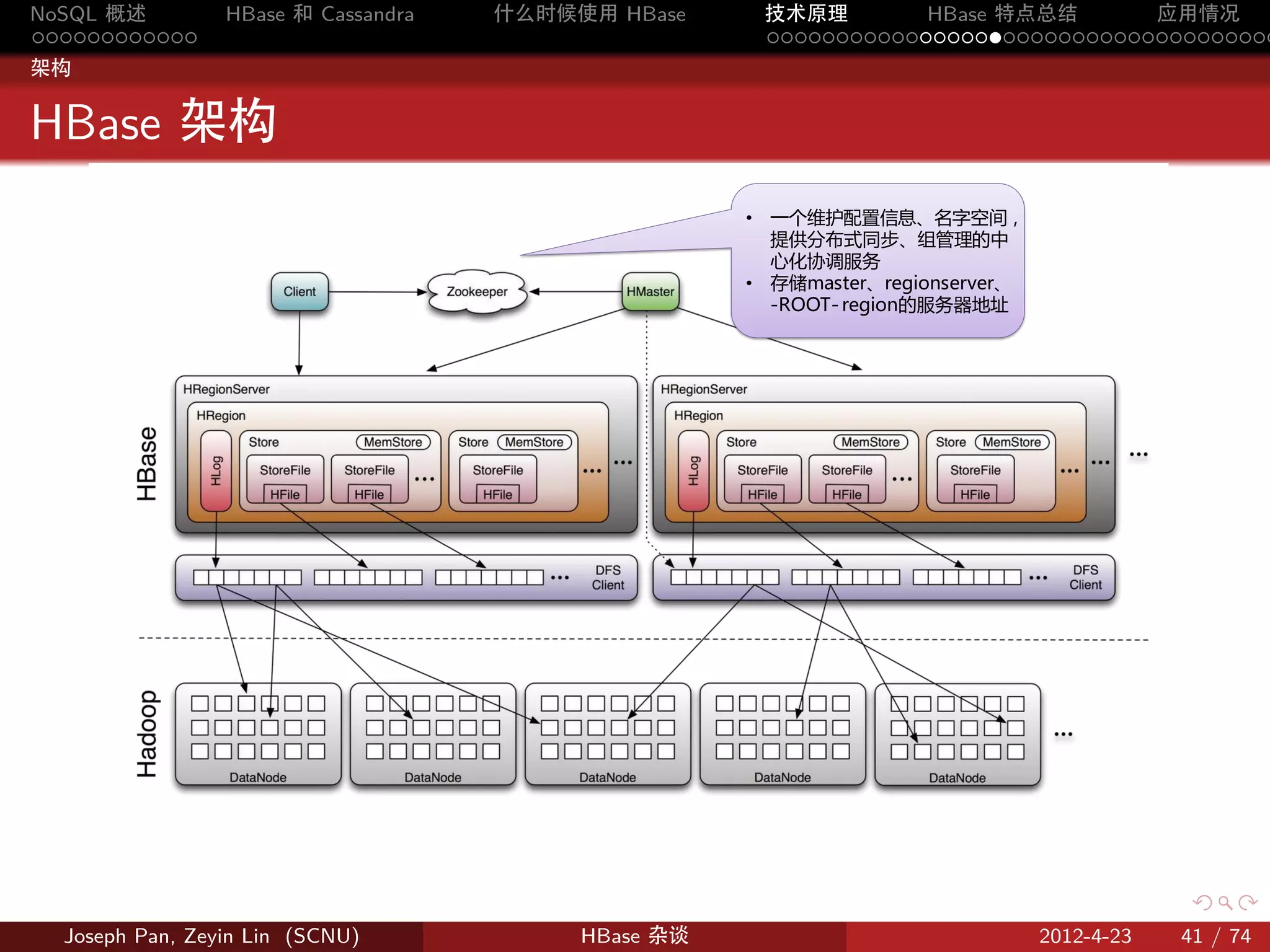
物理存储
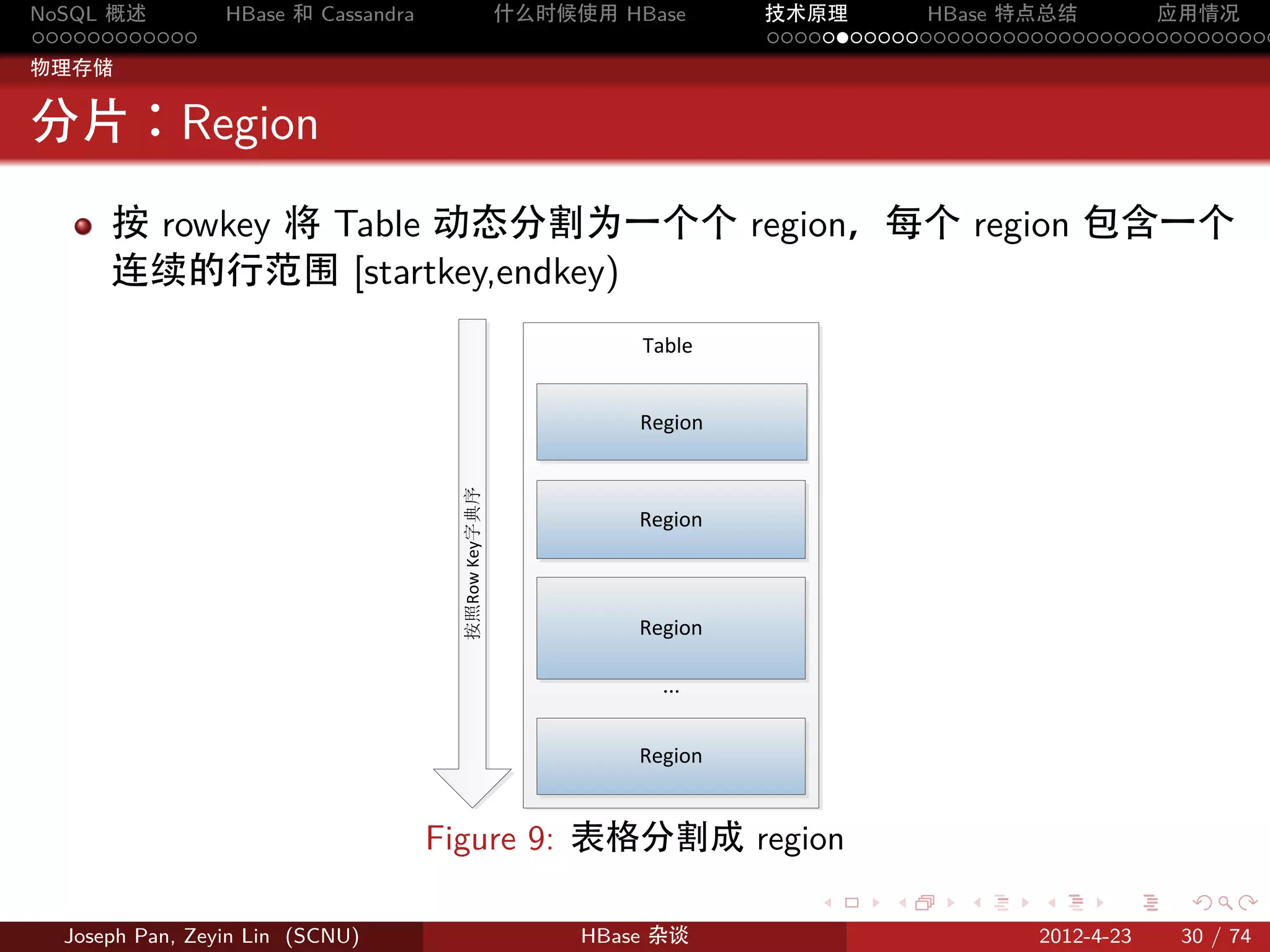
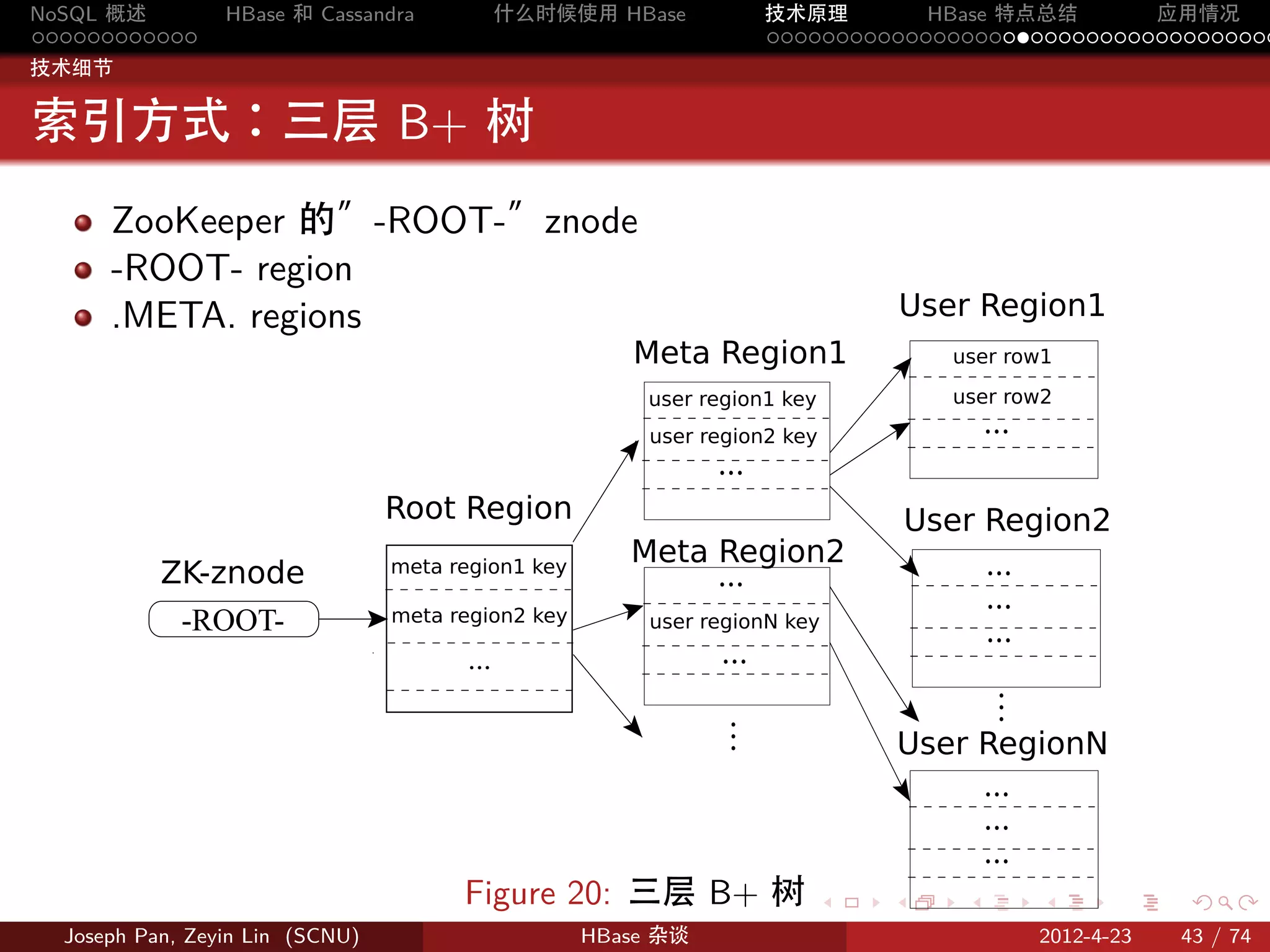
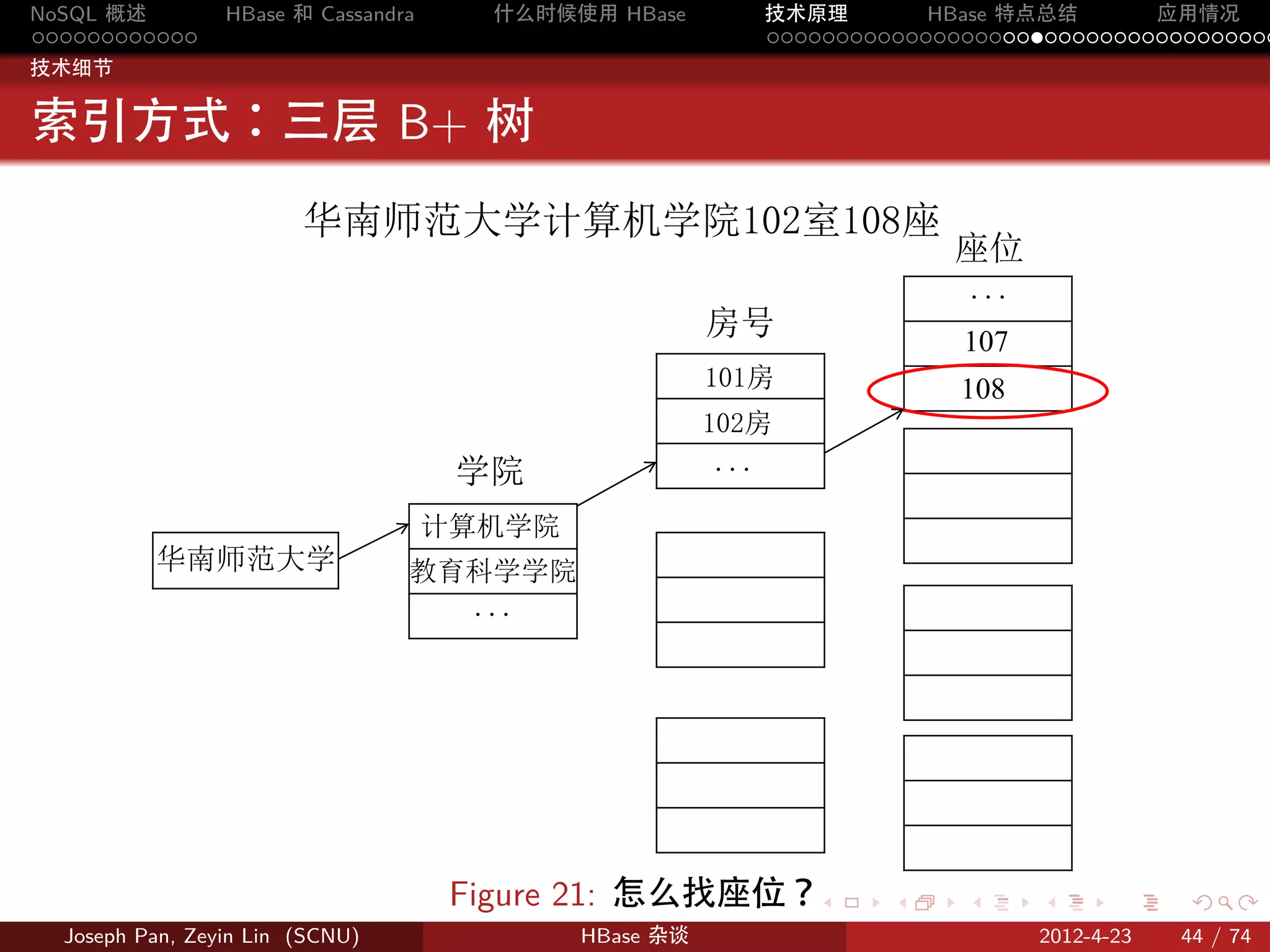
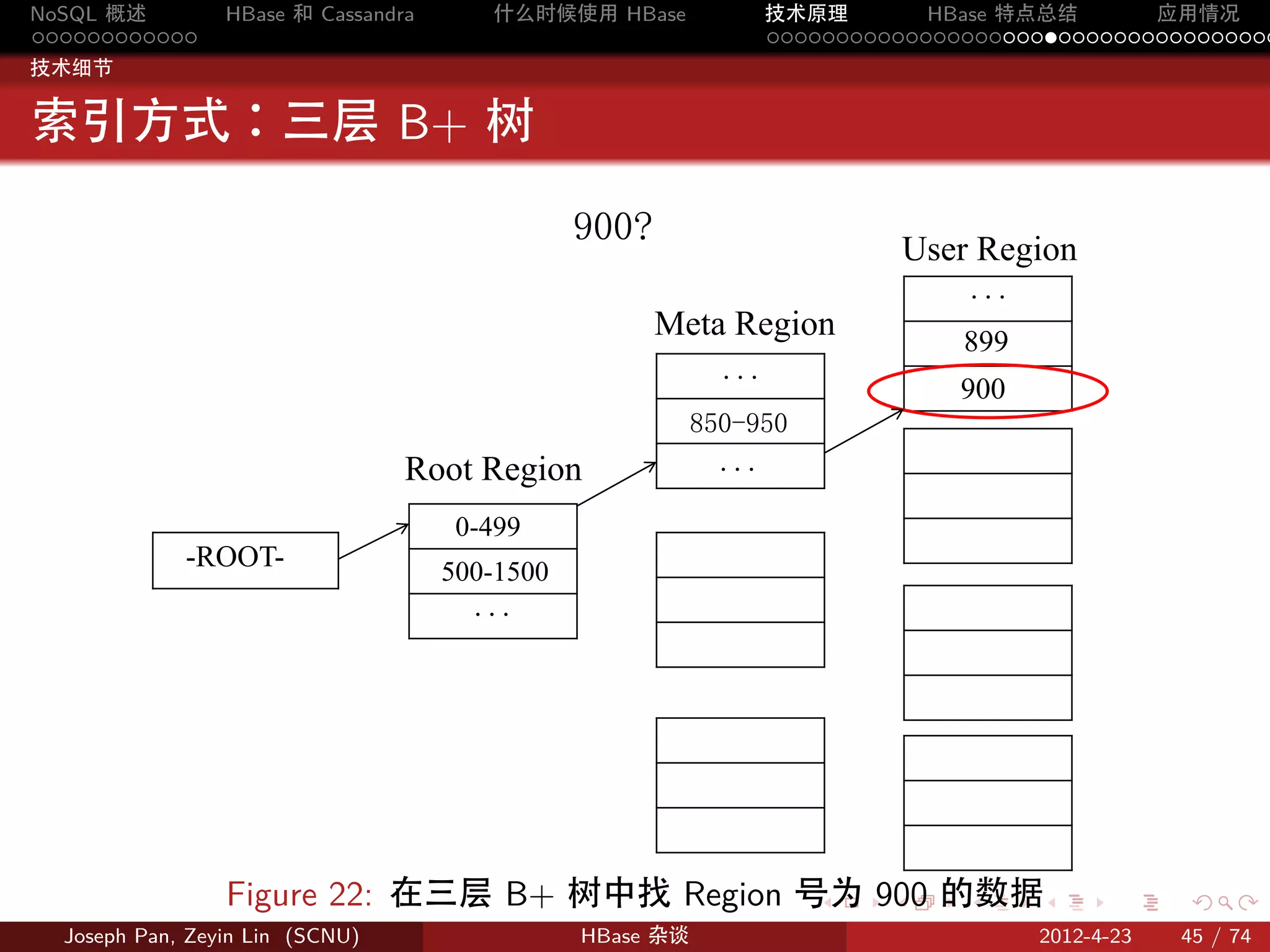
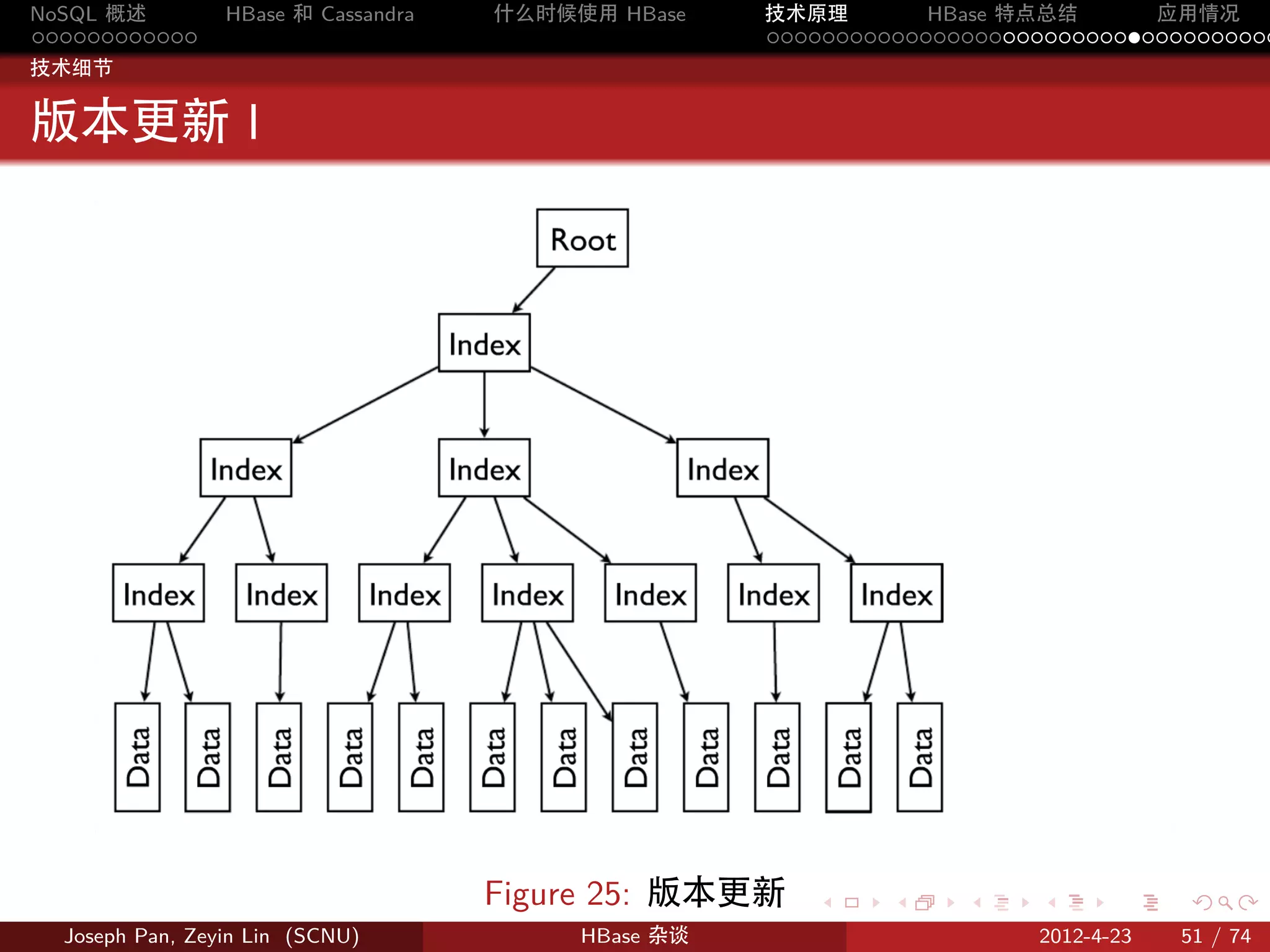
分片:Region
按 rowkey 将 Table 动态分割为一个个 region,每个 region 包含一个
连续的行范围 [startkey,endkey)
Table
Region
按照Row Key字典序
Region
Region
…
Region
Figure 9: 表格分割成 region
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 30 / 74
31.
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
物理存储
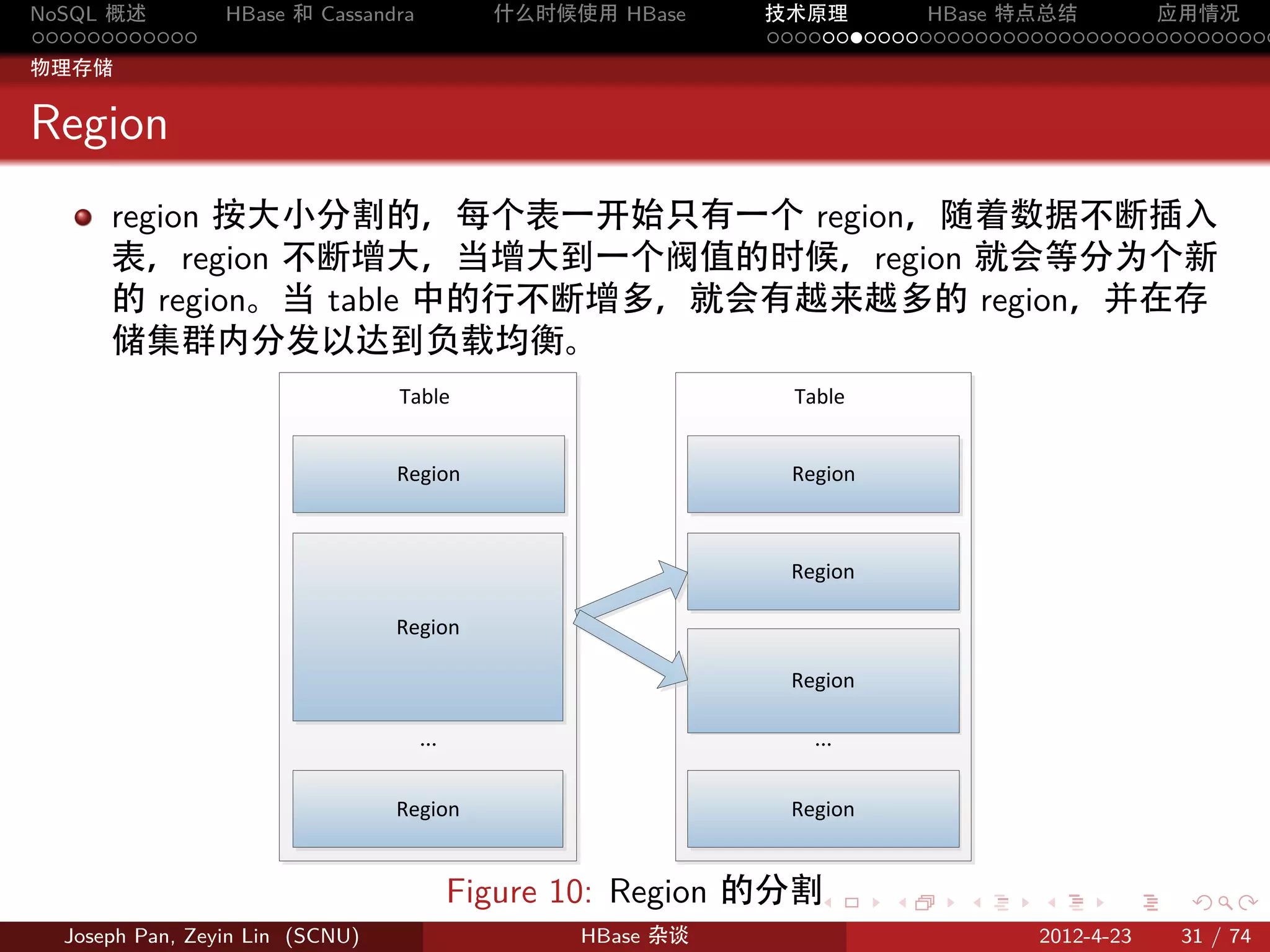
Region
region 按大小分割的,每个表一开始只有一个 region,随着数据不断插入
表,region 不断增大,当增大到一个阀值的时候,region 就会等分为个新
的 region。当 table 中的行不断增多,就会有越来越多的 region,并在存
储集群内分发以达到负载均衡。
Table Table
Region Region
Region
Region
Region
… …
Region Region
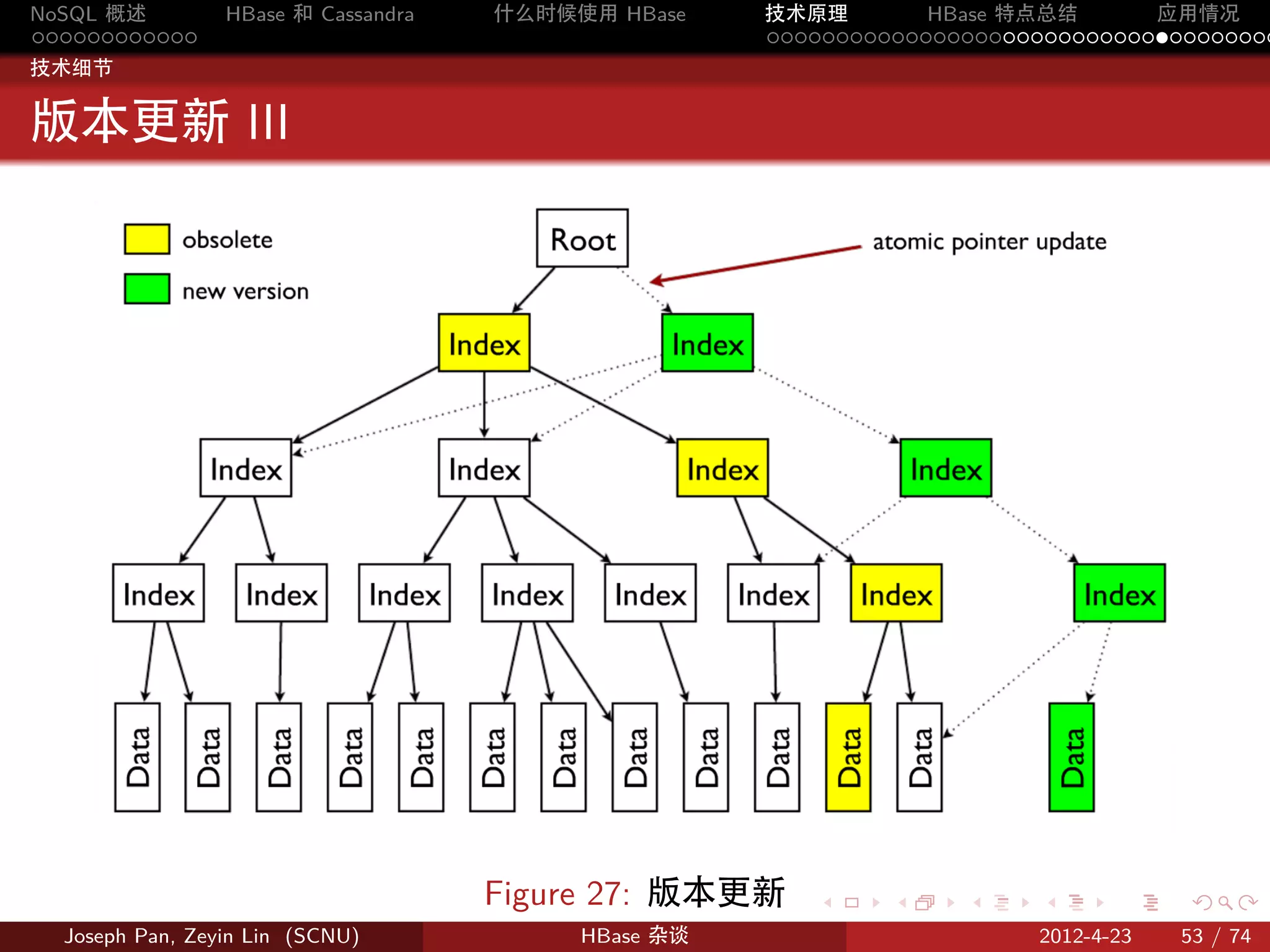
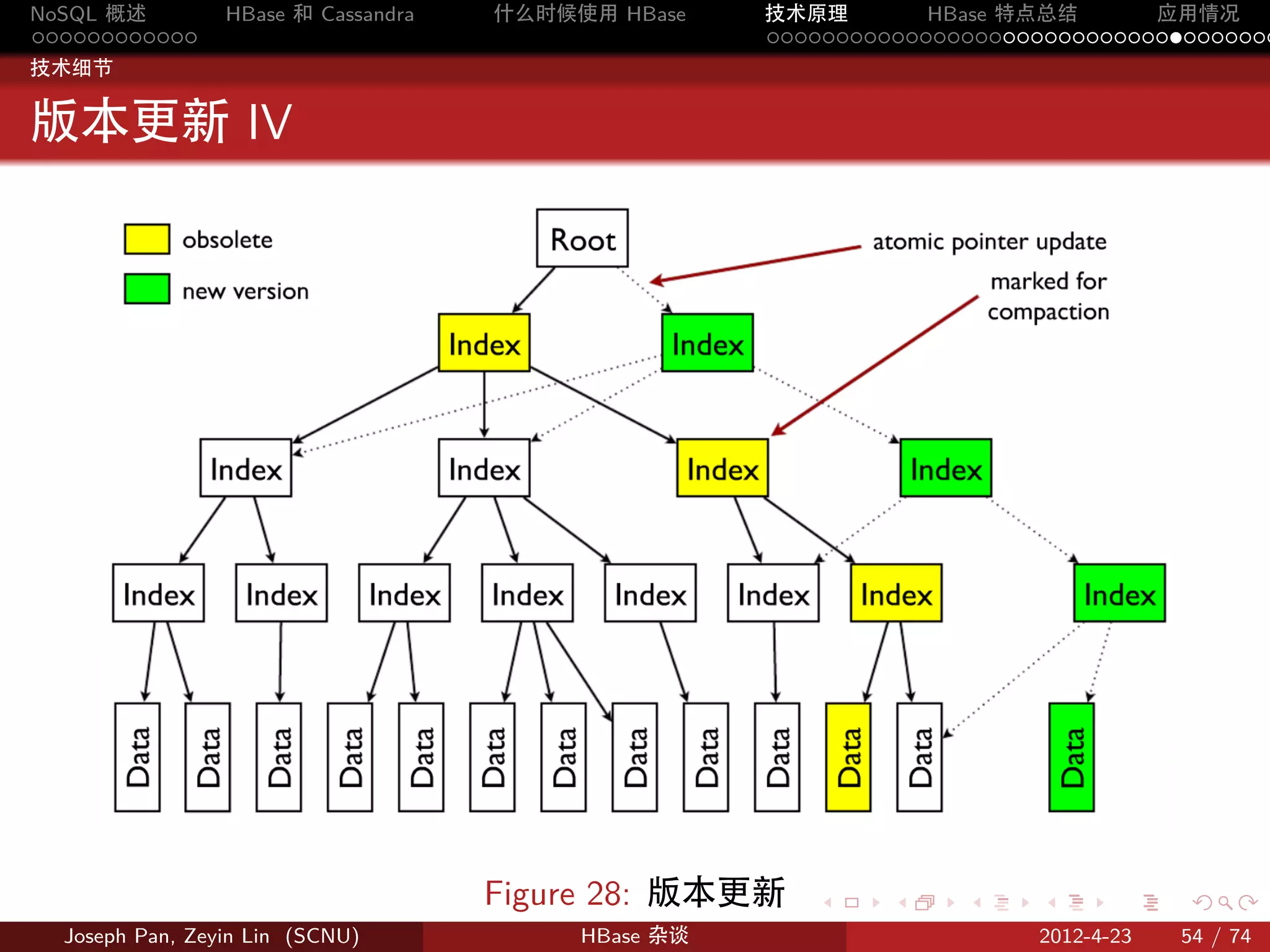
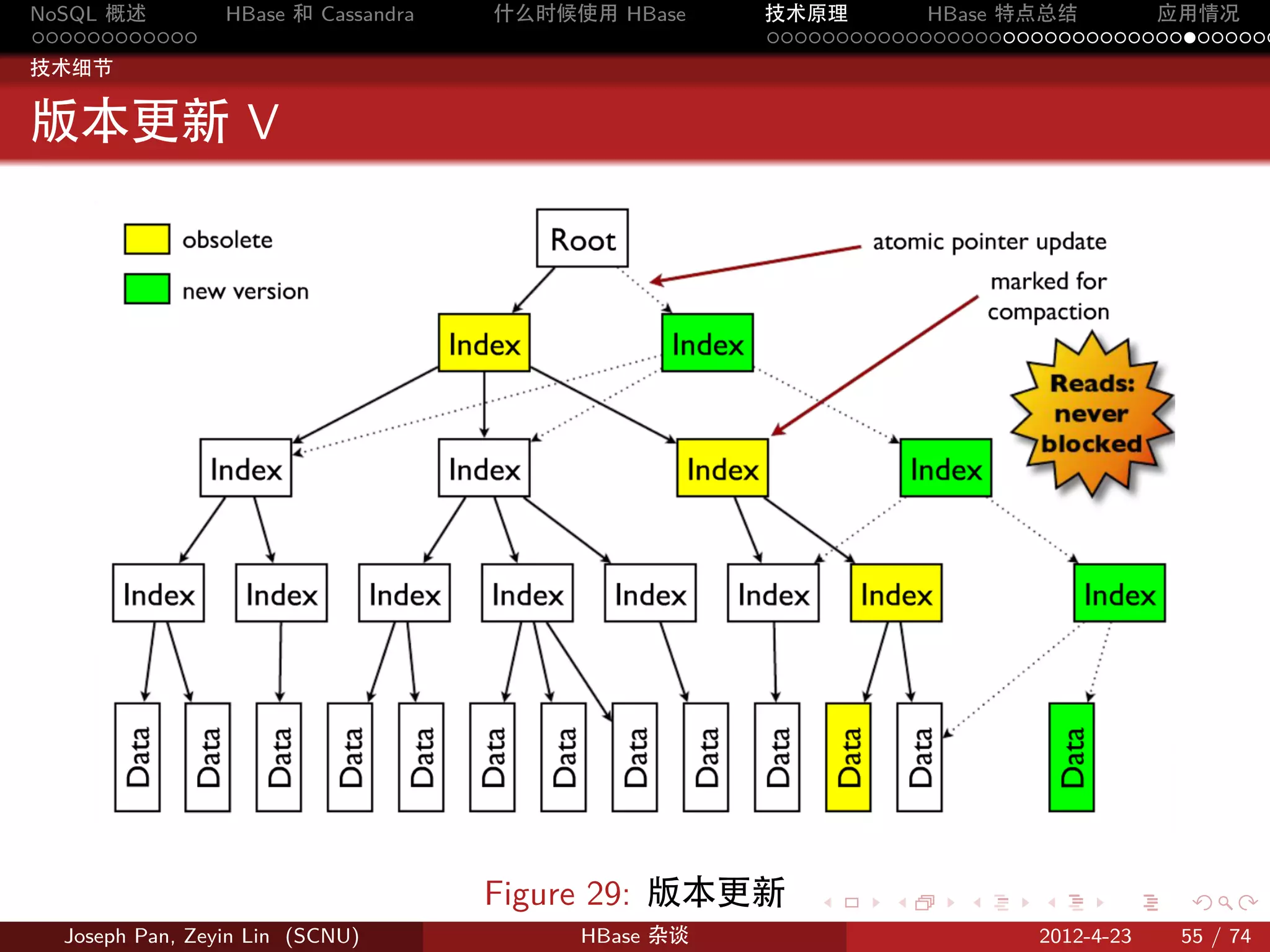
Figure 10: Region 的分割 . . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 31 / 74
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
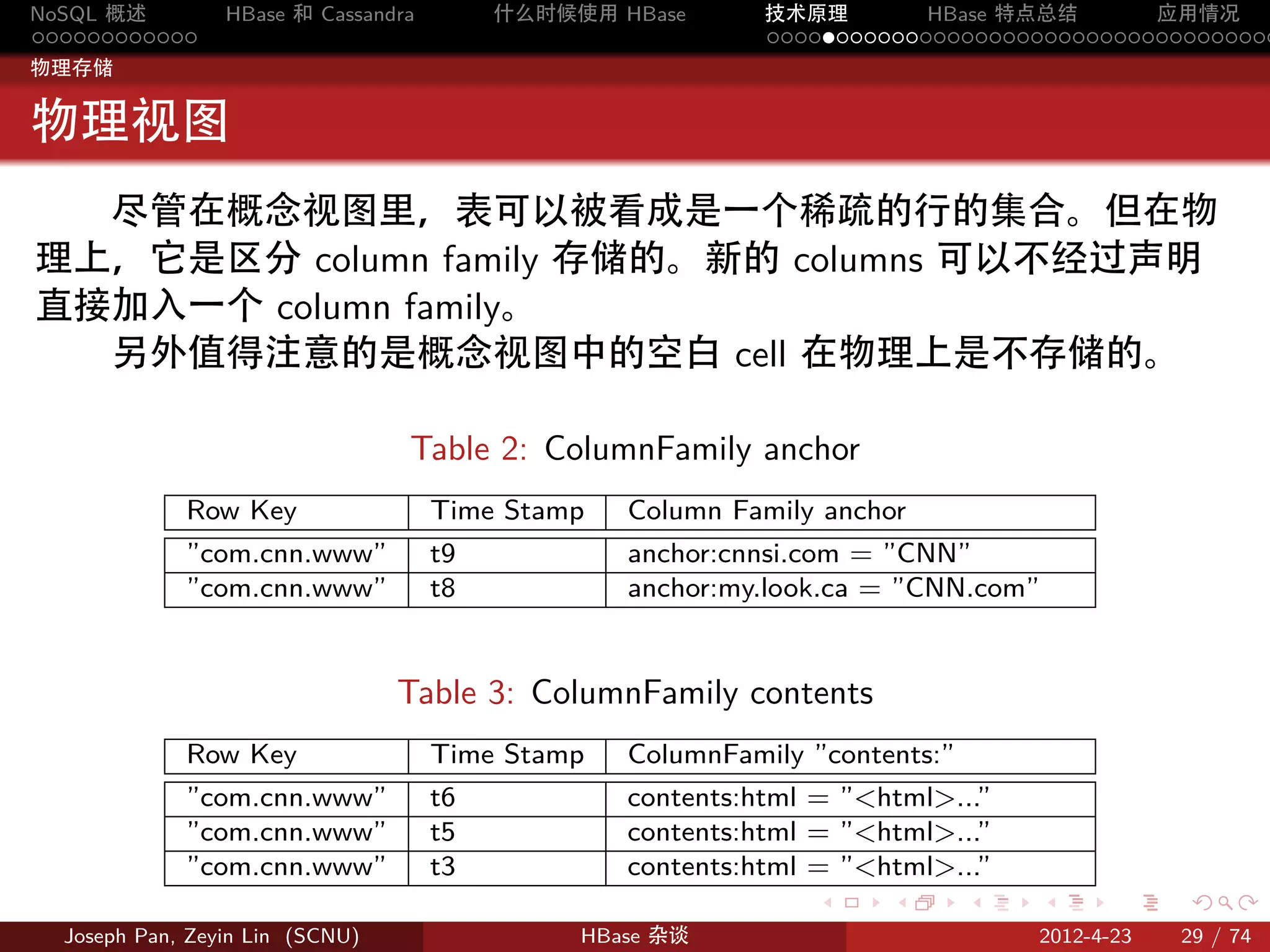
物理存储
Store
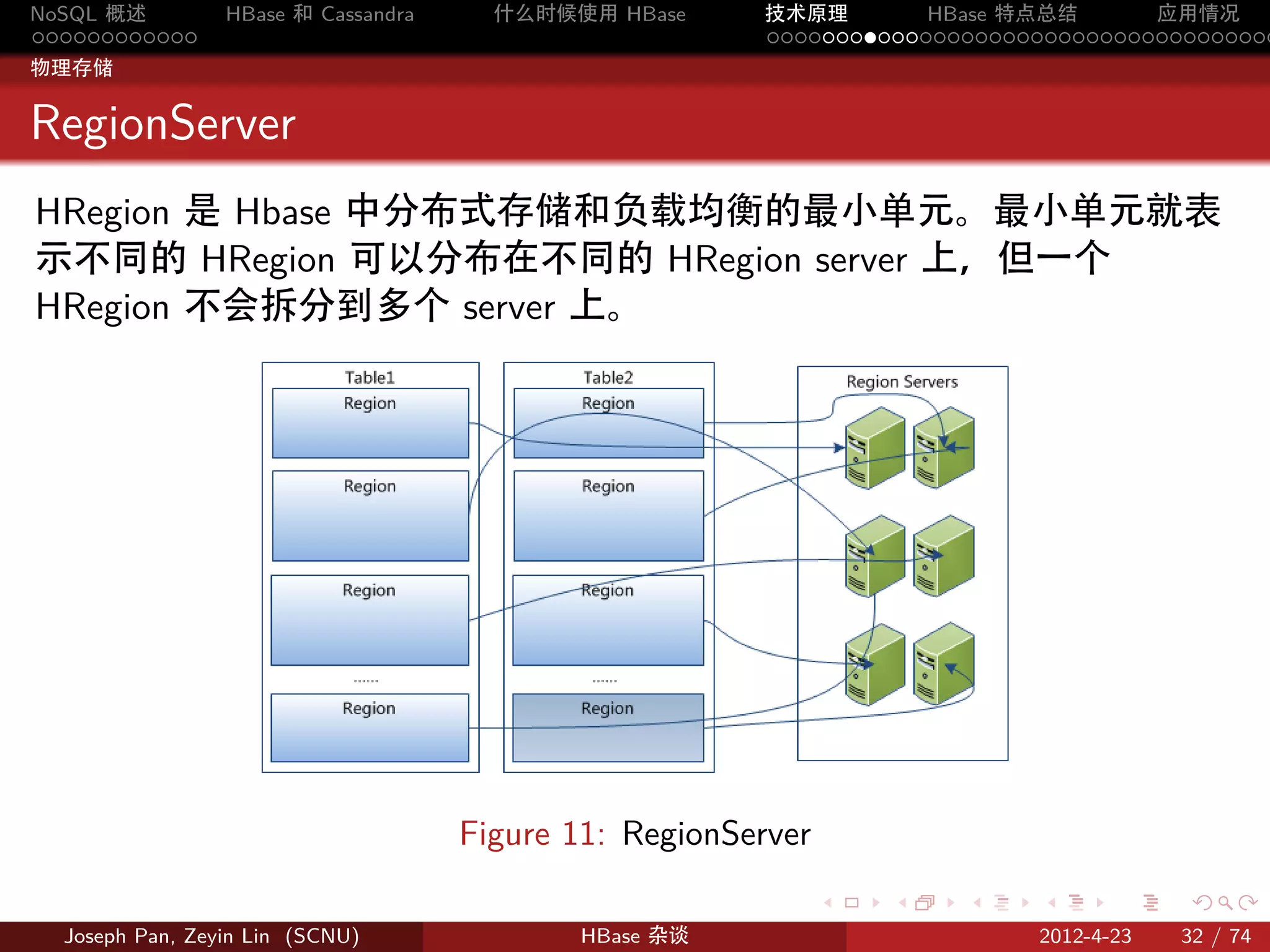
HRegion 虽然是分布式存储的最小单元,但并不是存储的最小单元。
事实上,HRegion 由一个或者多个 Store 组成,每个 Store 保存一个
columns family。每个 Strore 又由一个 memStore 和 0 至多个 StoreFile
组成。
StoreFile 以 HFile 格式保存在 HDFS 上。
Figure 12: Store
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 33 / 74
34.
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
物理存储
HFile 的格式
HFile 分为 6 个部分:
. Data Block 段:保存表中的数据,这部分可以被压缩;
1
.
2 Meta Block 段 (可选):保存用户自定义的元信息,可以被压缩;
. File Info 段:Hfile 的元信息,不被压缩,用户也可以在这一部分添加自己
3
的元信息;
.
4 Data Block Index 段:Data Block 的索引。每条索引的 key 是被索引的
block 的第一条记录的 key;
.
5 Meta Block Index 段 (可选的):Meta Block 的索引;
. Trailer:这一段是定长的。保存了每一段的偏移量,读取一个 HFile 时,
6
会首先读取 Trailer,Trailer 保存了每个段的起始位置 (段的 Magic Number
用来做安全 check),然后,DataBlock Index 会被读取到内存中,这样,当
检索某个 key 时,不需要扫描整个 HFile,而只需从内存中找到 key 所在
的 block,通过一次磁盘 io 将整个 block 读取到内存中,再找到需要的
key。DataBlock Index 采用 LRU 机制淘汰。
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 34 / 74
35.
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
物理存储
HFile 的格式
KeyLen (int) ValLen (int) Key (byte[]) Value (byte[])
Data Block 0
DATA BLOCK MAGIC (8B)
Data Block 1
TRAILER BLOCK MAGIC (8B)
Data Block 2 File Info Offset (long)
KeyLen Key id ValLen Val
(vint) (byte[]) (1B) (vint) (byte[]) Trailer Data Index Offset (long)
Meta Block 0
(Optional) User Defined Metadata, Data Index Count (int)
start with METABLOCKMAGIC
Meta Block 1 Meta Index Offset (long)
(Optional)
Meta Index Count (int)
File Info
Total Uncompressed Data Bytes (long)
Entry Count or Data K-V Count (int)
User Defined
Compression Codec (int)
Meta Index Version (int)
(Optional)
Total Size of Trailer: 4xLong + 5xInt + 8Bytes = 60 Bytes
Trailer
Index of Meta Block 0
…
Figure 14: Trailer
Offset(long) MetaSize (int) MetaNameLen (vint) MetaName (byte[])
Offset(long) DataSize (int) KeyLen (vint) Key (byte[])
Figure 13: HFile 的格式 3
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 35 / 74
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
HBase API
HBase API
Java API
Get
Put
Delete
Scan
HBaseAdmin
MapReduce
HBase shell (like mysql/hive)
Thrift
REST
Jython,Scala,Groovy DSL, Cascading, Pig, Hive...
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 64 / 74
66.
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
HBase API
Get/Scan
Gets 是在 Scan 的基础上实现的。下面的讨论 Get 同样可以用 Scan 来
描述。
.
1 默认 Get 例子
§
Get g e t = new Get ( Bytes . t o B y t e s ( ”row1” ) ) ;
Result r = htable . get ( get ) ;
b y t e [ ] b = r . g e t V a l u e ( Bytes . t o B y t e s ( ” c f ” ) , Bytes . t o B y t e s ( ” a t t r ” ) )
; // r e t u r n s c u r r e n t v e r s i o n o f v a l u e
¥
2. 含有版本的 Get 例子
§
Get g e t = new Get ( Bytes . t o B y t e s ( ”row1” ) ) ;
g e t . s e t M a x V e r s i o n s ( 3 ) ; // w i l l r e t u r n l a s t 3 v e r s i o n s o f row
Result r = htable . get ( get ) ;
b y t e [ ] b = r . g e t V a l u e ( Bytes . t o B y t e s ( ” c f ” ) , Bytes . t o B y t e s ( ” a t t r ” ) )
; // r e t u r n s c u r r e n t v e r s i o n o f v a l u e
L i s t KeyValue kv = r . getColumn ( Bytes . t o B y t e s ( ” c f ” ) , Bytes .
t o B y t e s ( ” a t t r ” ) ) ; // r e t u r n s a l l v e r s i o n s o f t h i s column
¥
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 65 / 74
67.
NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
HBase API
Put
一个 Put 操作会给一个 cell, 创建一个版本,默认使用当前时间戳,
当然你也可以自己设置时间戳。这就意味着你可以把时间设置在过去或
者未来,或者随意使用一个 Long 值。要想覆盖一个现有的值,就意味
着你的 row,column 和版本必须完全相等。
.
1 不指明版本的例子(Hbase 会用当前时间作为版本)
§
Put put = new Put ( Bytes . t o B y t e s ( row ) ) ;
put . add ( Bytes . t o B y t e s ( ” c f ” ) , Bytes . t o B y t e s ( ” a t t r 1 ” ) , Bytes .
t o B y t e s ( data ) ) ;
h t a b l e . put ( put ) ;
¥
2. 指明版本的例子
§
Put put = new Put ( Bytes . t o B y t e s ( row ) ) ;
l o n g e x p l i c i t T i m e I n M s = 5 5 5 ; // j u s t an example
put . add ( Bytes . t o B y t e s ( ” c f ” ) , Bytes . t o B y t e s ( ” a t t r 1 ” ) ,
e x p l i c i t T i m e I n M s , Bytes . t o B y t e s ( data ) ) ;
h t a b l e . put ( put ) ;
¥
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 66 / 74












![NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
数据模型
构造函数
./src/main/java/org/apache/hadoop/hbase/keyvalue.java:
§
p u b l i c KeyValue ( f i n a l b y t e [ ] row , f i n a l b y t e [ ] f a m i l y , f i n a l by t e [ ]
q u a l i f i e r , f i n a l l o n g timestamp , f i n a l b y t e [ ] v a l u e )
{
t h i s ( row , f a m i l y , q u a l i f i e r , timestamp , Type . Put , v a l u e ) ;
}
p u b l i c KeyValue ( f i n a l b y t e [ ] row , f i n a l i n t r o f f s e t , f i n a l i n t r l e n g t h
, f i n a l by t e [ ] f a m i l y , f i n a l i n t f o f f s e t , f i n a l i n t f l e n g t h ,
f i n a l by t e [ ] q u a l i f i e r , f i n a l i n t q o f f s e t , f i n a l i n t q l e n g t h ,
f i n a l l o n g timestamp , f i n a l Type type ,
f i n a l byte [ ] value , f i n a l i n t v o f f s e t , f i n a l i n t vlength ) {
t h i s . b y t e s = c r e a t e B y t e A r r a y ( row , r o f f s e t , r l e n g t h ,
family , f o f f s e t , flength , q u a l i f i e r , q o f f s e t , qlength ,
timestamp , type , v a l u e , v o f f s e t , v l e n g t h ) ;
t h i s . length = bytes . length ;
this . o f f s e t = 0;
}
¥
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 28 / 74](https://image.slidesharecdn.com/hbase-120423062727-phpapp02/75/HBase-28-2048.jpg)


![NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
物理存储
HFile 的格式
KeyLen (int) ValLen (int) Key (byte[]) Value (byte[])
Data Block 0
DATA BLOCK MAGIC (8B)
Data Block 1
TRAILER BLOCK MAGIC (8B)
Data Block 2 File Info Offset (long)
KeyLen Key id ValLen Val
(vint) (byte[]) (1B) (vint) (byte[]) Trailer Data Index Offset (long)
Meta Block 0
(Optional) User Defined Metadata, Data Index Count (int)
start with METABLOCKMAGIC
Meta Block 1 Meta Index Offset (long)
(Optional)
Meta Index Count (int)
File Info
Total Uncompressed Data Bytes (long)
Entry Count or Data K-V Count (int)
User Defined
Compression Codec (int)
Meta Index Version (int)
(Optional)
Total Size of Trailer: 4xLong + 5xInt + 8Bytes = 60 Bytes
Trailer
Index of Meta Block 0
…
Figure 14: Trailer
Offset(long) MetaSize (int) MetaNameLen (vint) MetaName (byte[])
Offset(long) DataSize (int) KeyLen (vint) Key (byte[])
Figure 13: HFile 的格式 3
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 35 / 74](https://image.slidesharecdn.com/hbase-120423062727-phpapp02/75/HBase-35-2048.jpg)















![NoSQL 概述 HBase 和 Cassandra 什么时候使用 HBase 技术原理 HBase 特点总结 应用情况
............ .....................................
HBase API
Get/Scan
Gets 是在 Scan 的基础上实现的。下面的讨论 Get 同样可以用 Scan 来
描述。
.
1 默认 Get 例子
§
Get g e t = new Get ( Bytes . t o B y t e s ( ”row1” ) ) ;
Result r = htable . get ( get ) ;
b y t e [ ] b = r . g e t V a l u e ( Bytes . t o B y t e s ( ” c f ” ) , Bytes . t o B y t e s ( ” a t t r ” ) )
; // r e t u r n s c u r r e n t v e r s i o n o f v a l u e
¥
2. 含有版本的 Get 例子
§
Get g e t = new Get ( Bytes . t o B y t e s ( ”row1” ) ) ;
g e t . s e t M a x V e r s i o n s ( 3 ) ; // w i l l r e t u r n l a s t 3 v e r s i o n s o f row
Result r = htable . get ( get ) ;
b y t e [ ] b = r . g e t V a l u e ( Bytes . t o B y t e s ( ” c f ” ) , Bytes . t o B y t e s ( ” a t t r ” ) )
; // r e t u r n s c u r r e n t v e r s i o n o f v a l u e
L i s t KeyValue kv = r . getColumn ( Bytes . t o B y t e s ( ” c f ” ) , Bytes .
t o B y t e s ( ” a t t r ” ) ) ; // r e t u r n s a l l v e r s i o n s o f t h i s column
¥
. . . . . .
Joseph Pan, Zeyin Lin (SCNU) HBase 杂谈 2012-4-23 65 / 74](https://image.slidesharecdn.com/hbase-120423062727-phpapp02/75/HBase-66-2048.jpg)









![[译]No sql生态系统](https://cdn.slidesharecdn.com/ss_thumbnails/nosql-110624114358-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)











































![内存数据库[1]](https://cdn.slidesharecdn.com/ss_thumbnails/1-120520044455-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


