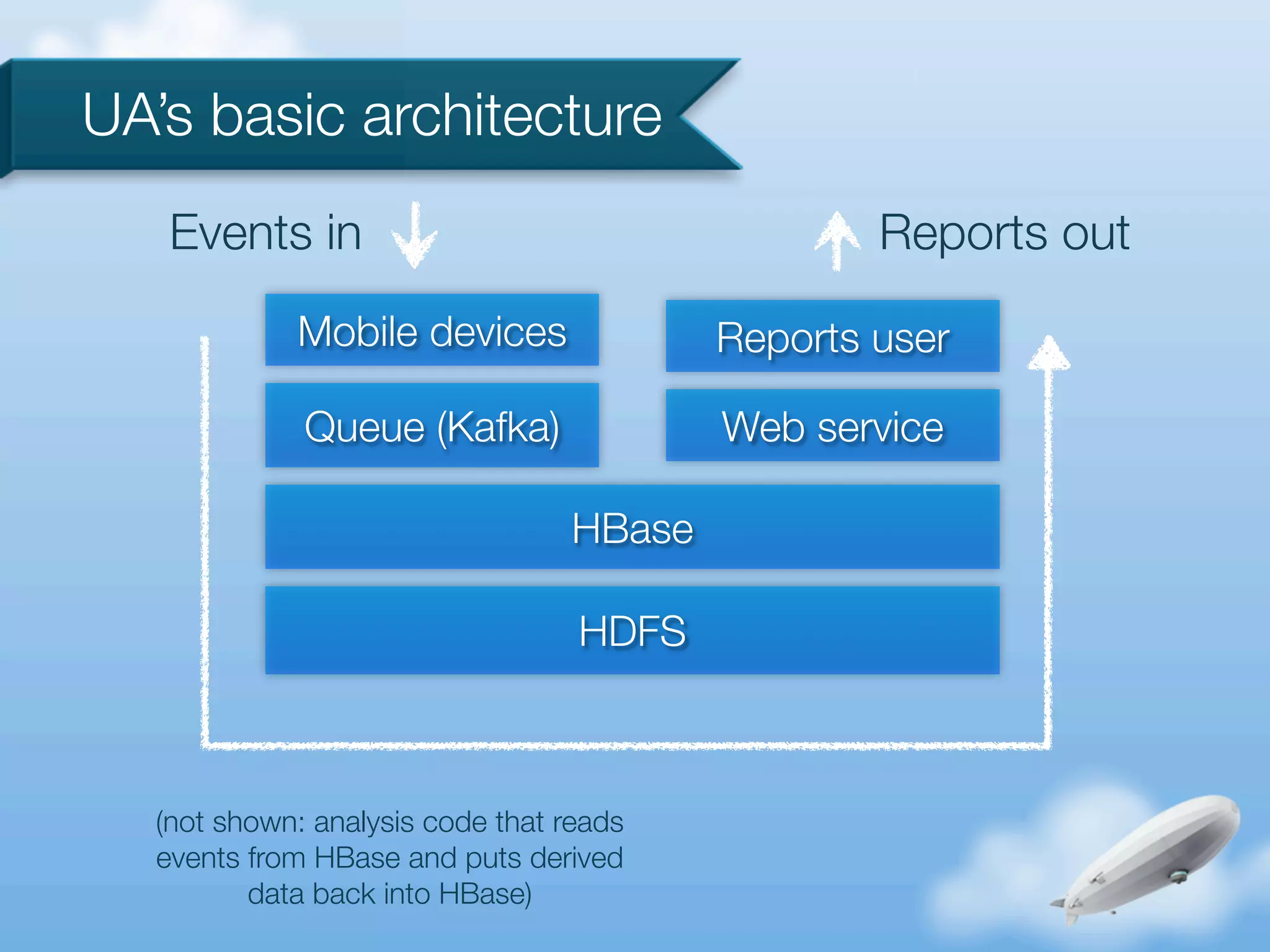
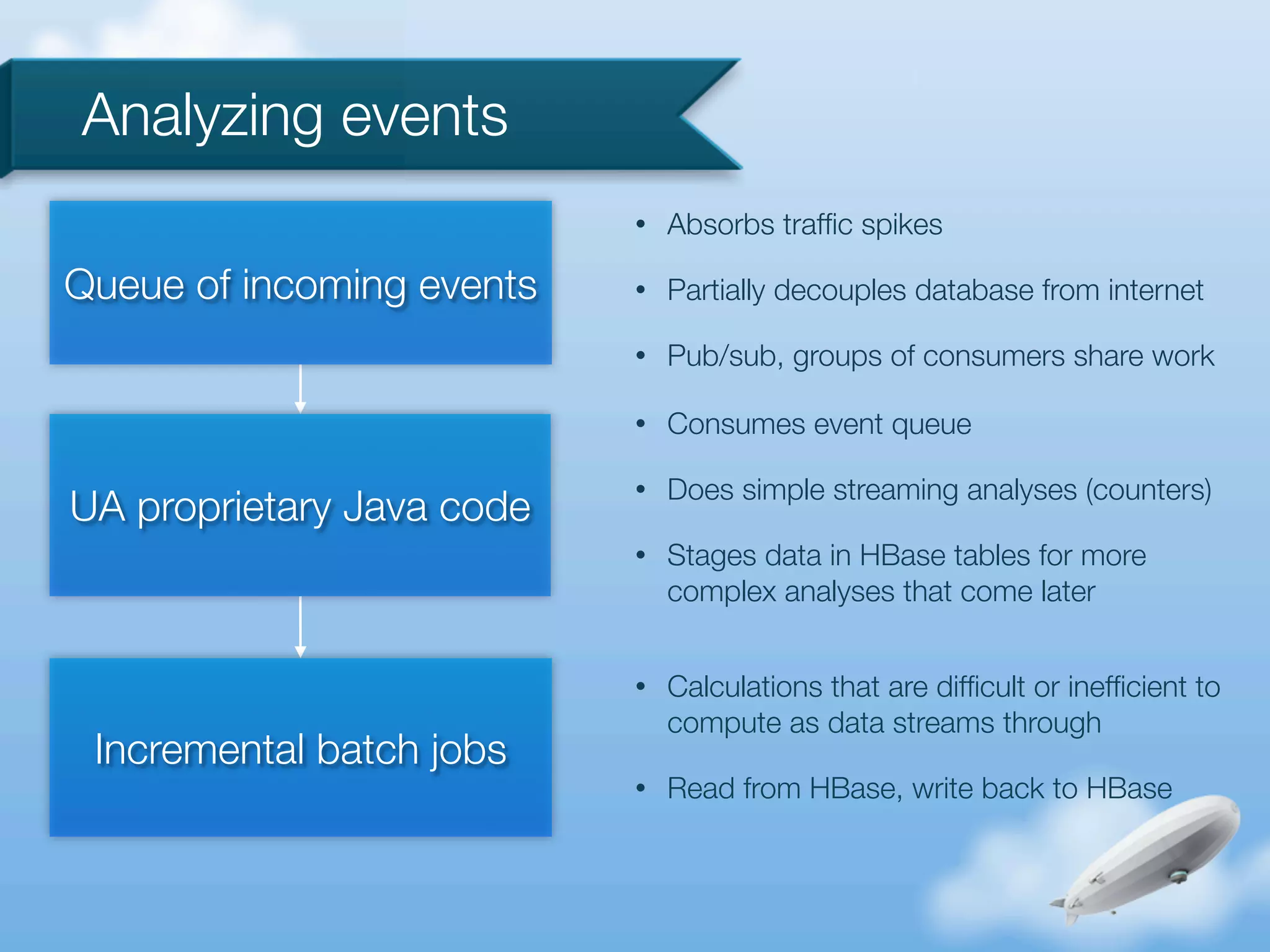
The document discusses the implementation of HBase and Hadoop at Urban Airship, focusing on their goals, architecture, and event analysis processes for near real-time reporting from mobile devices. It highlights the benefits of using HBase for querying Hadoop data and addresses common issues encountered with MapReduce. Additionally, it outlines strengths and weaknesses in Urban Airship's design and processing strategies.























![HBase API example
byte[] firstNameQualifier = “fname”.getBytes();
byte[] lastNameQualifier = “lname”.getBytes();
byte[] personalInfoColFam = “personalInfo”.getBytes();
HTable hTable = new HTable(“users”);
Put put = new Put(“dave”.getBytes());
put.add(personalInfoColFam, firstNameQualifier, “Dave”.getBytes());
put.add(personalInfoColFam, lastNameQualifier, “Revell”.getBytes());
hTable.put(put);](https://image.slidesharecdn.com/phdsslides-120425233007-phpapp02/75/HBase-and-Hadoop-at-Urban-Airship-26-2048.jpg)





























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
