Downloaded 25 times






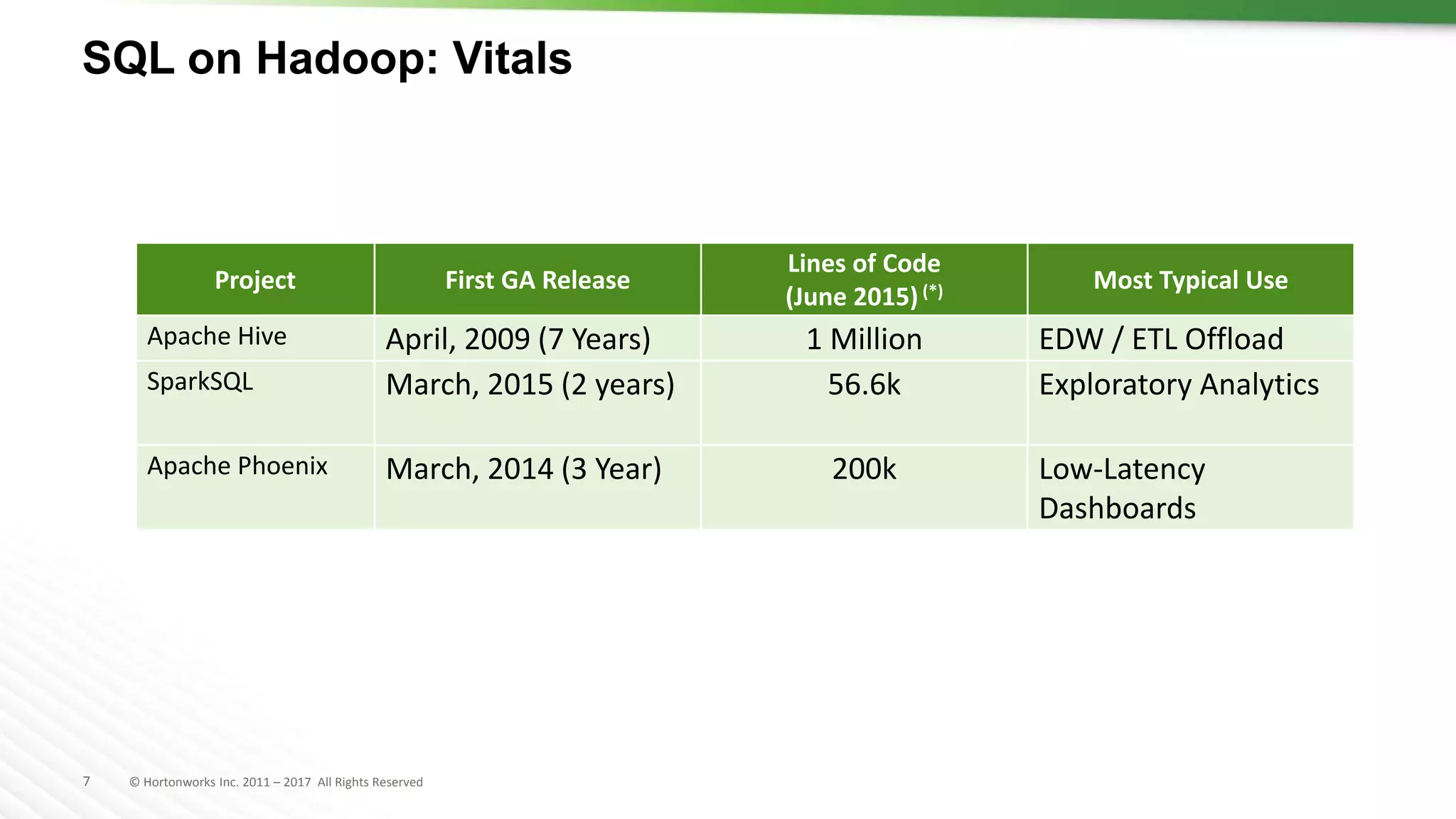








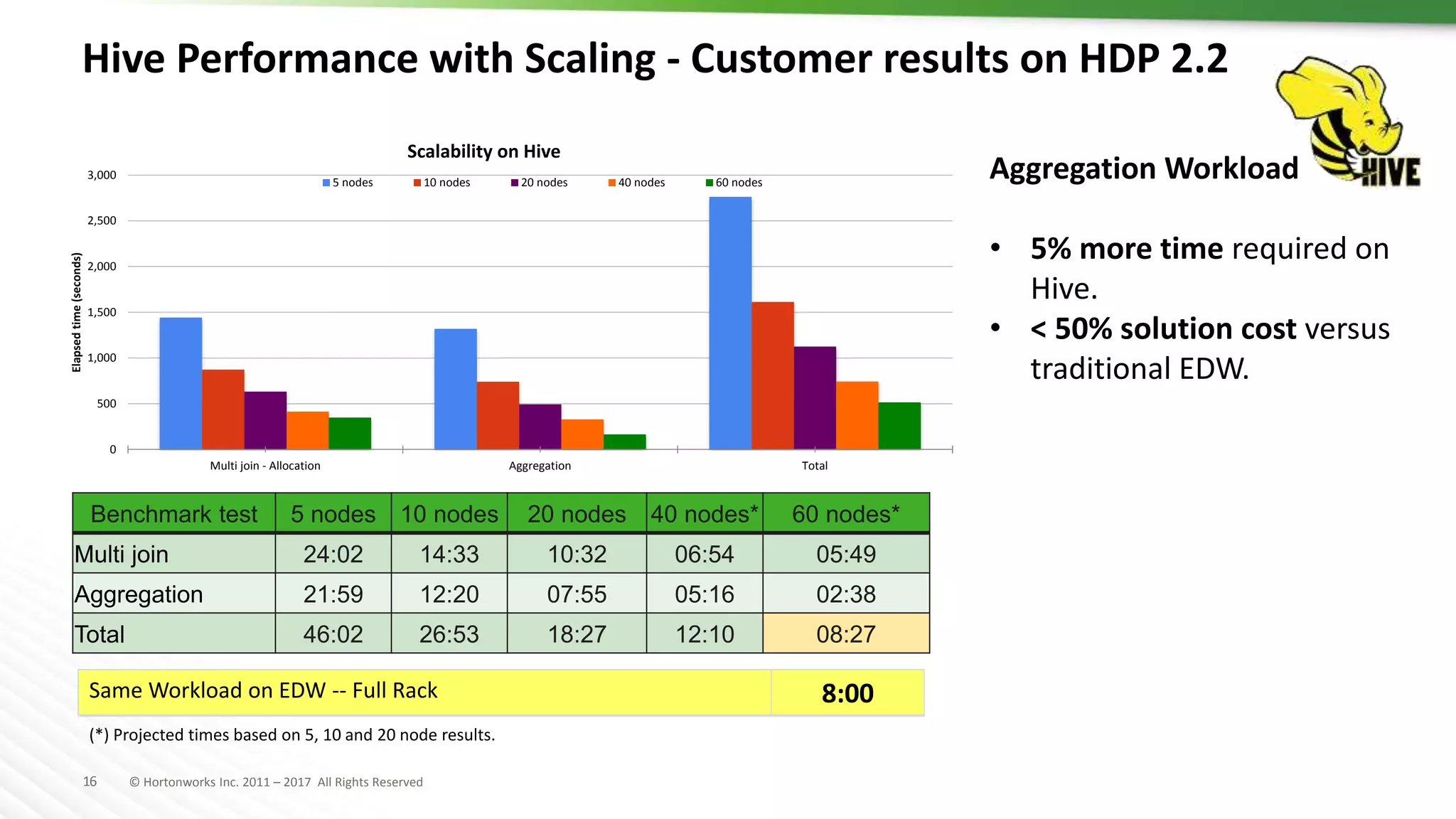
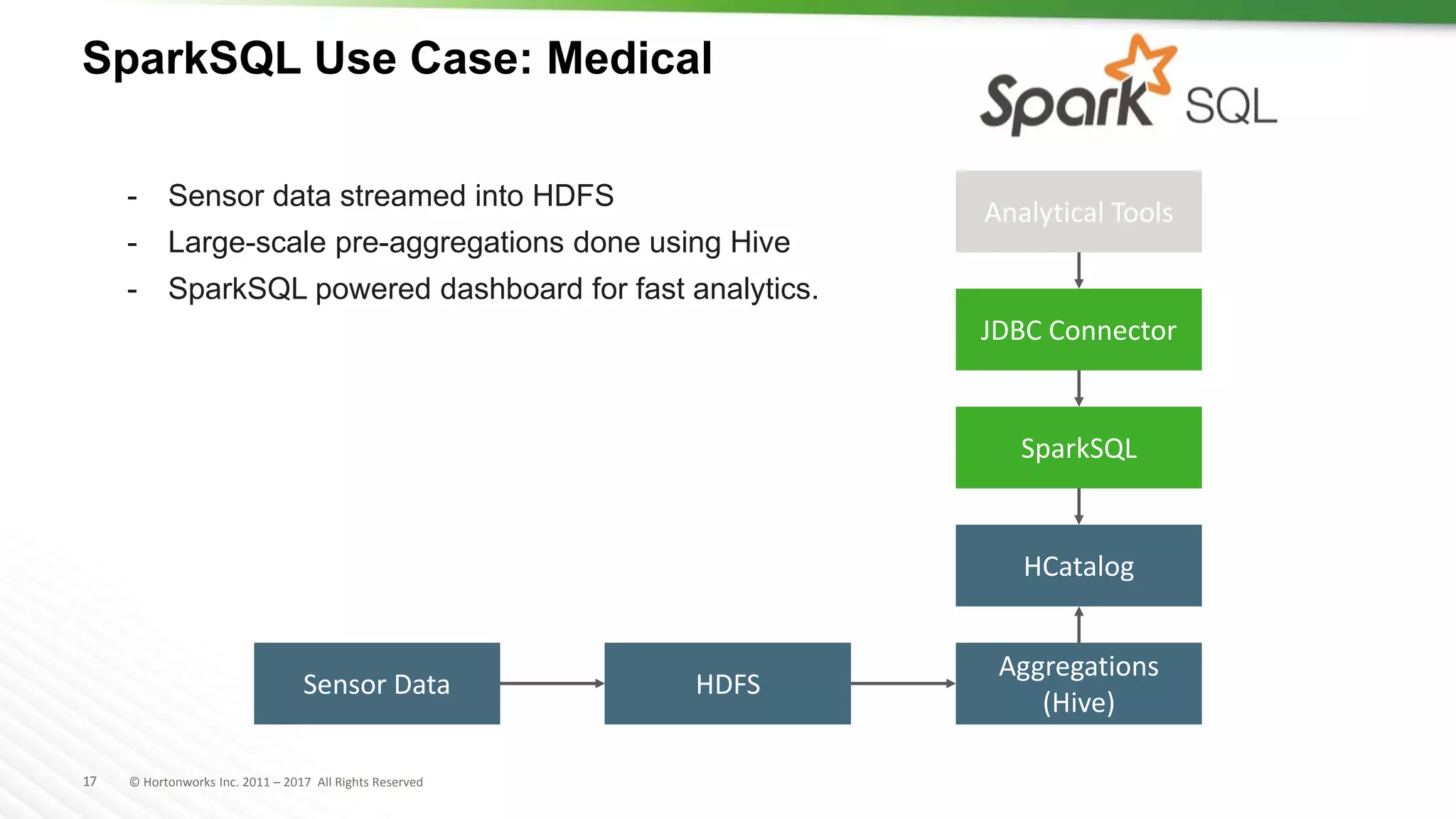



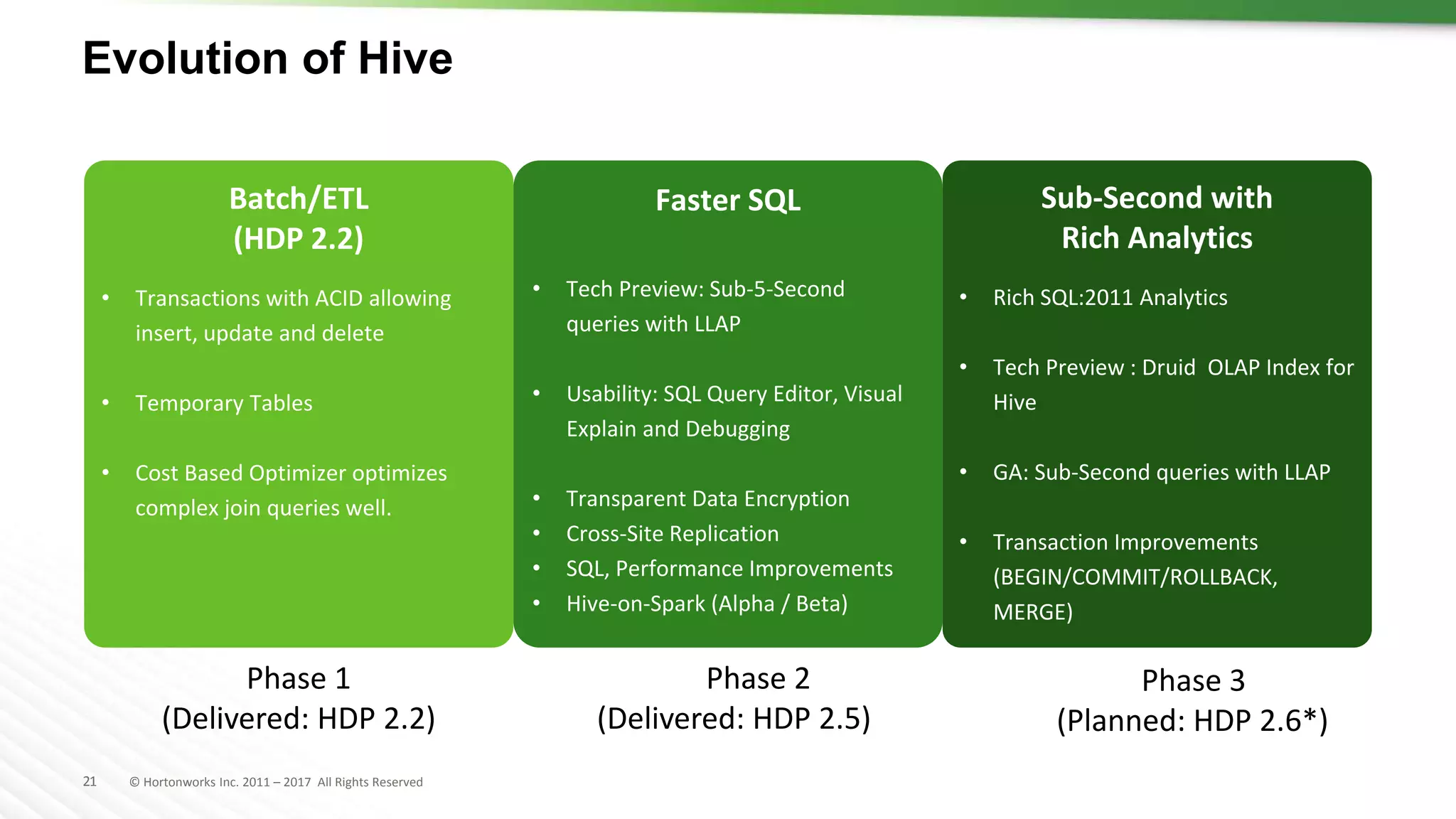
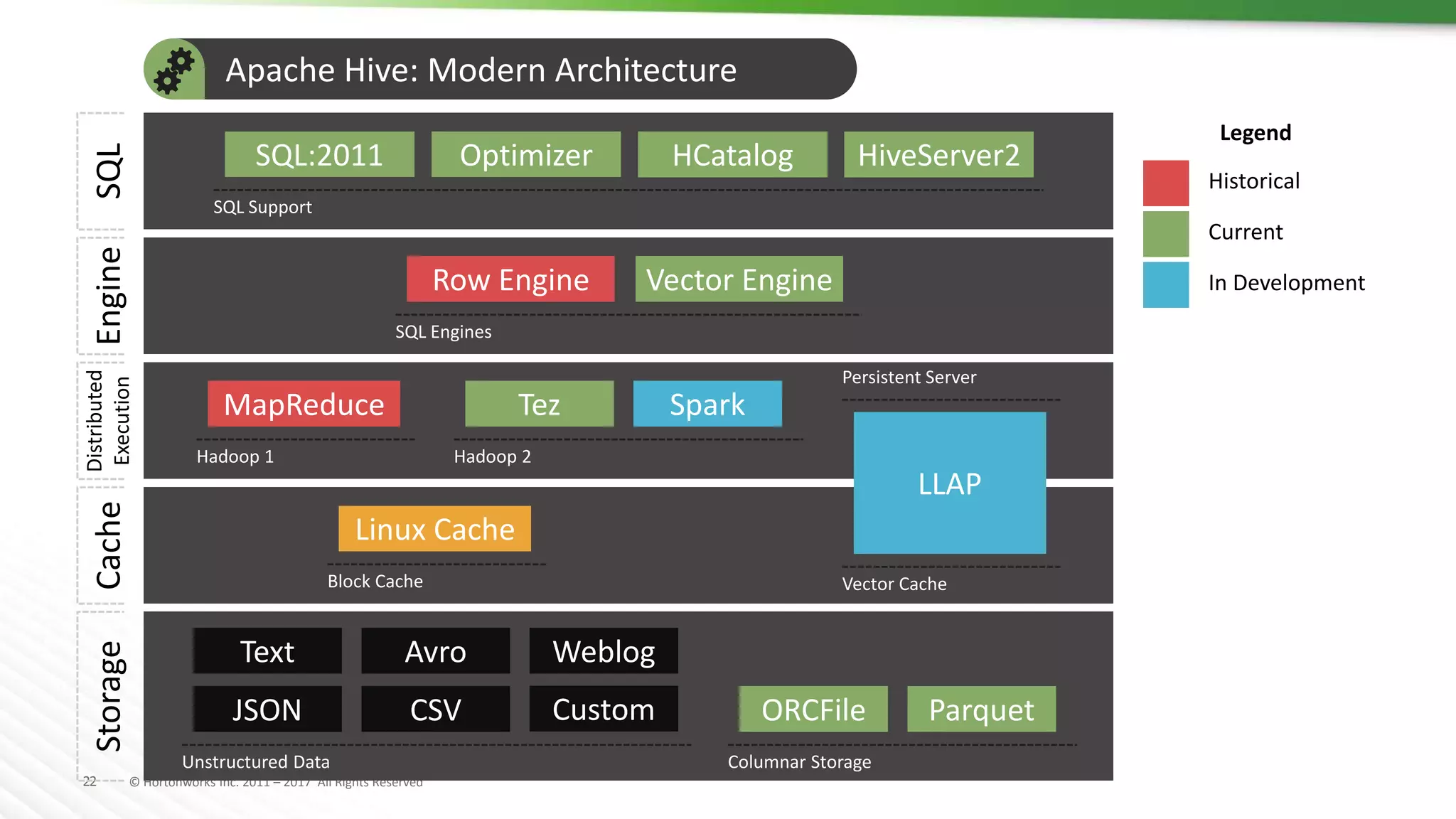

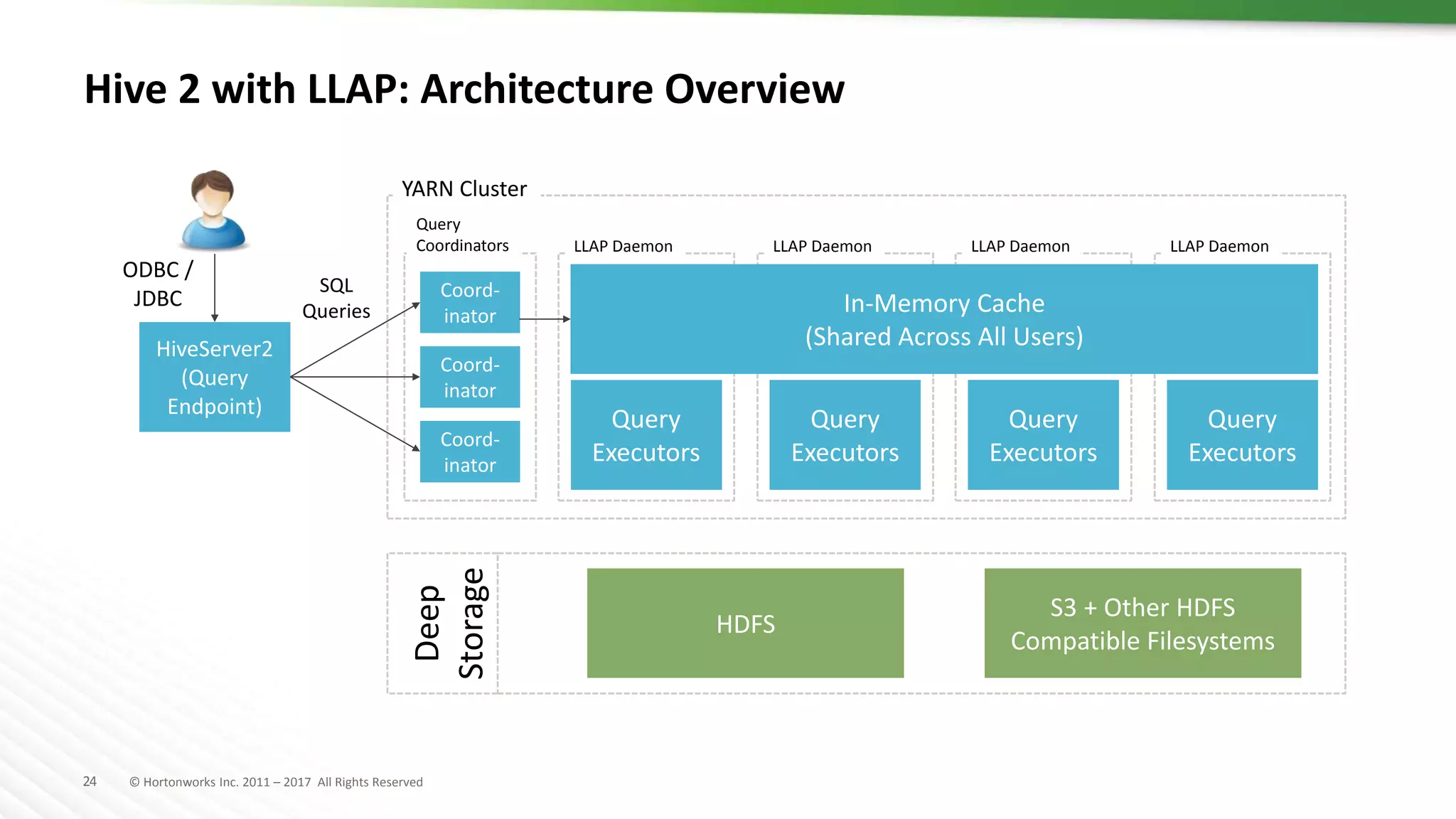
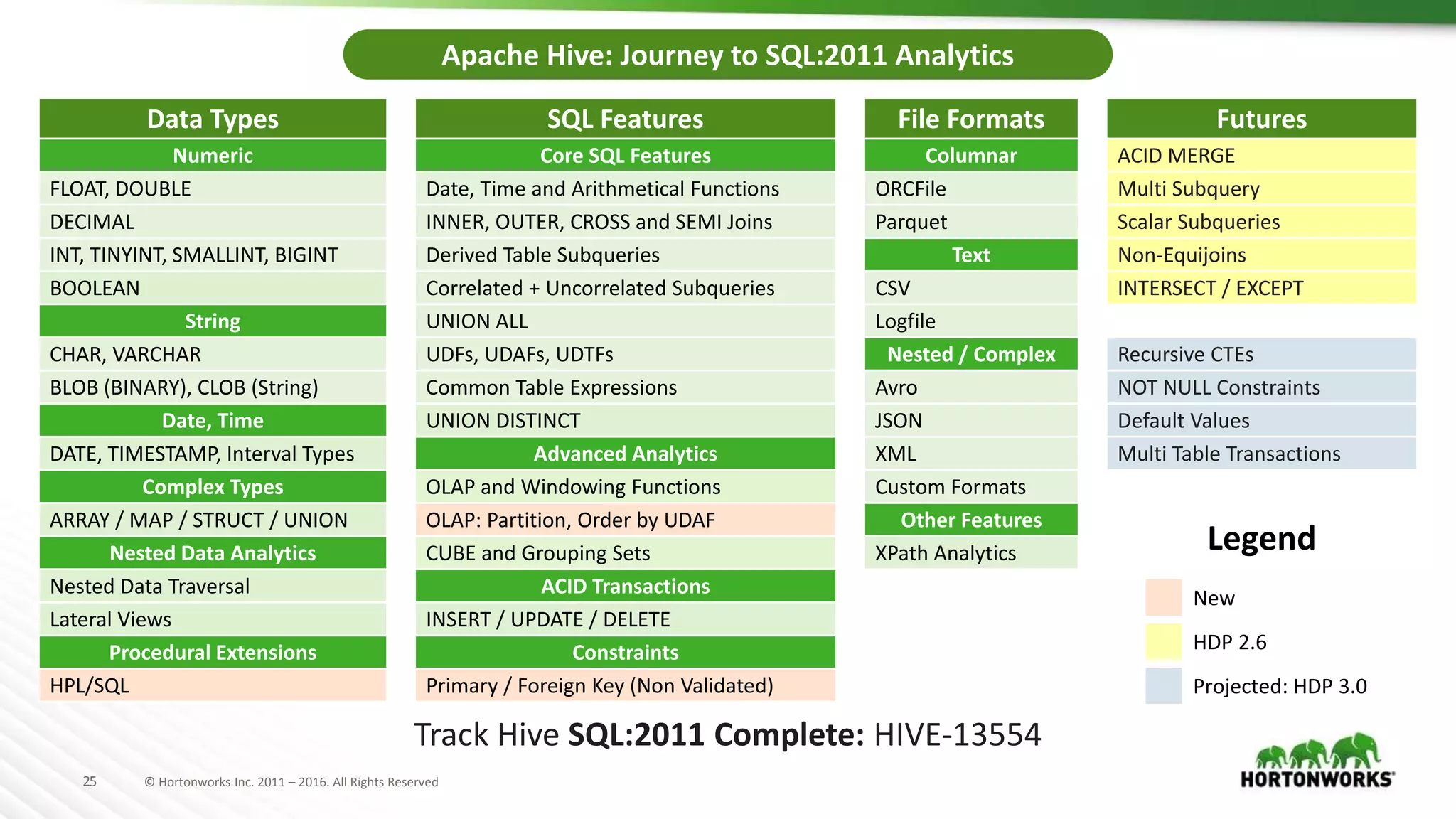
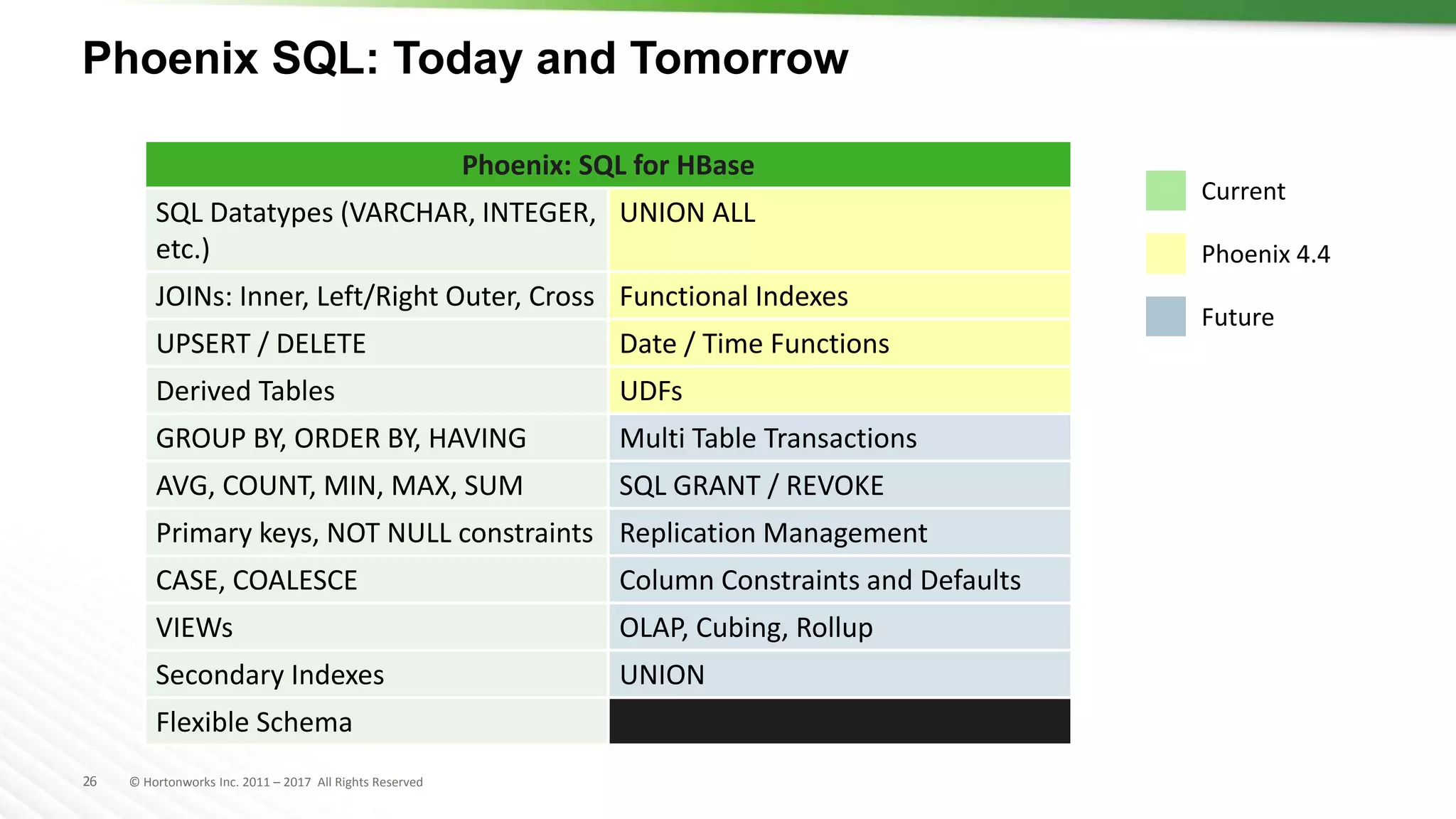

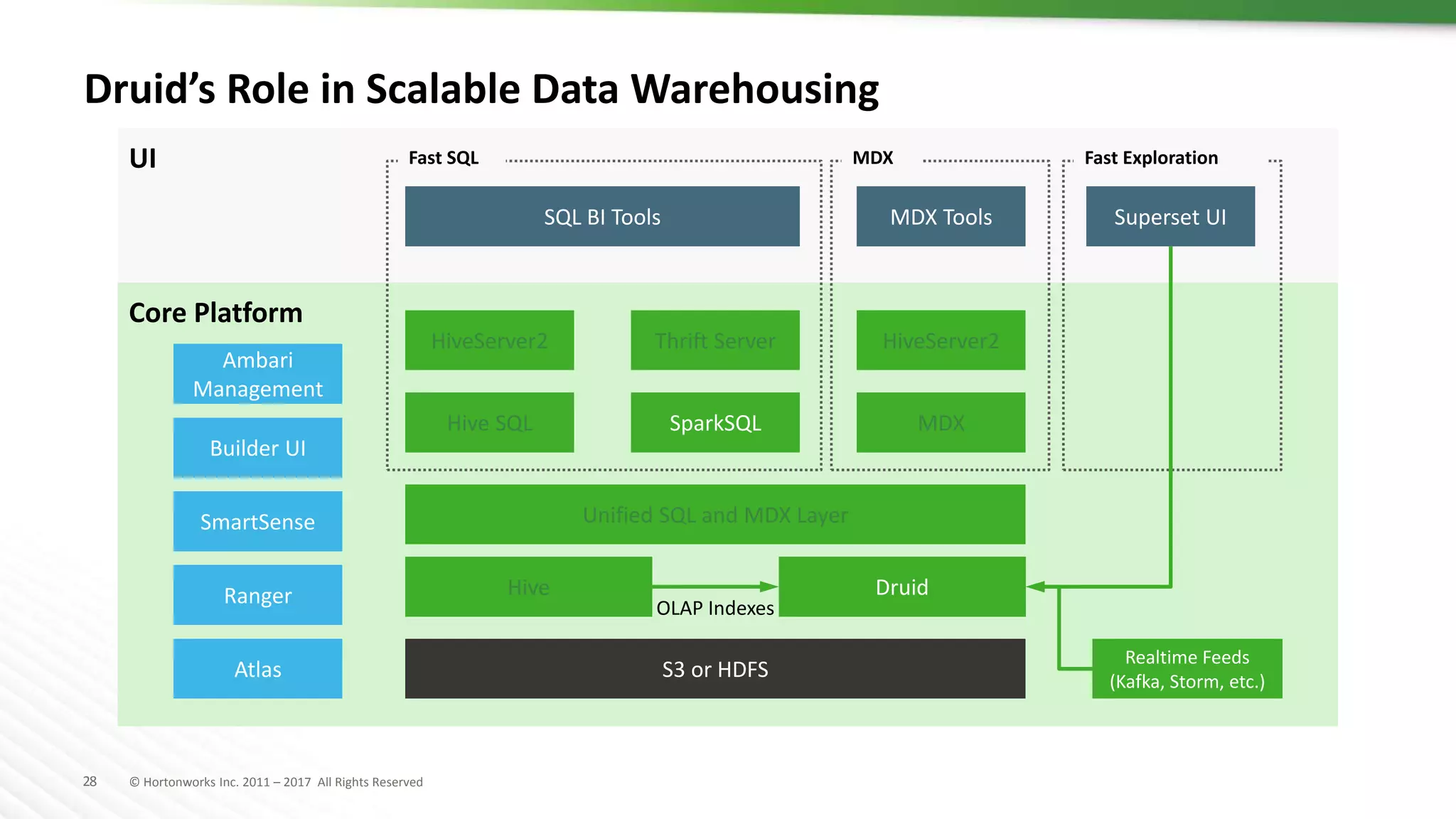

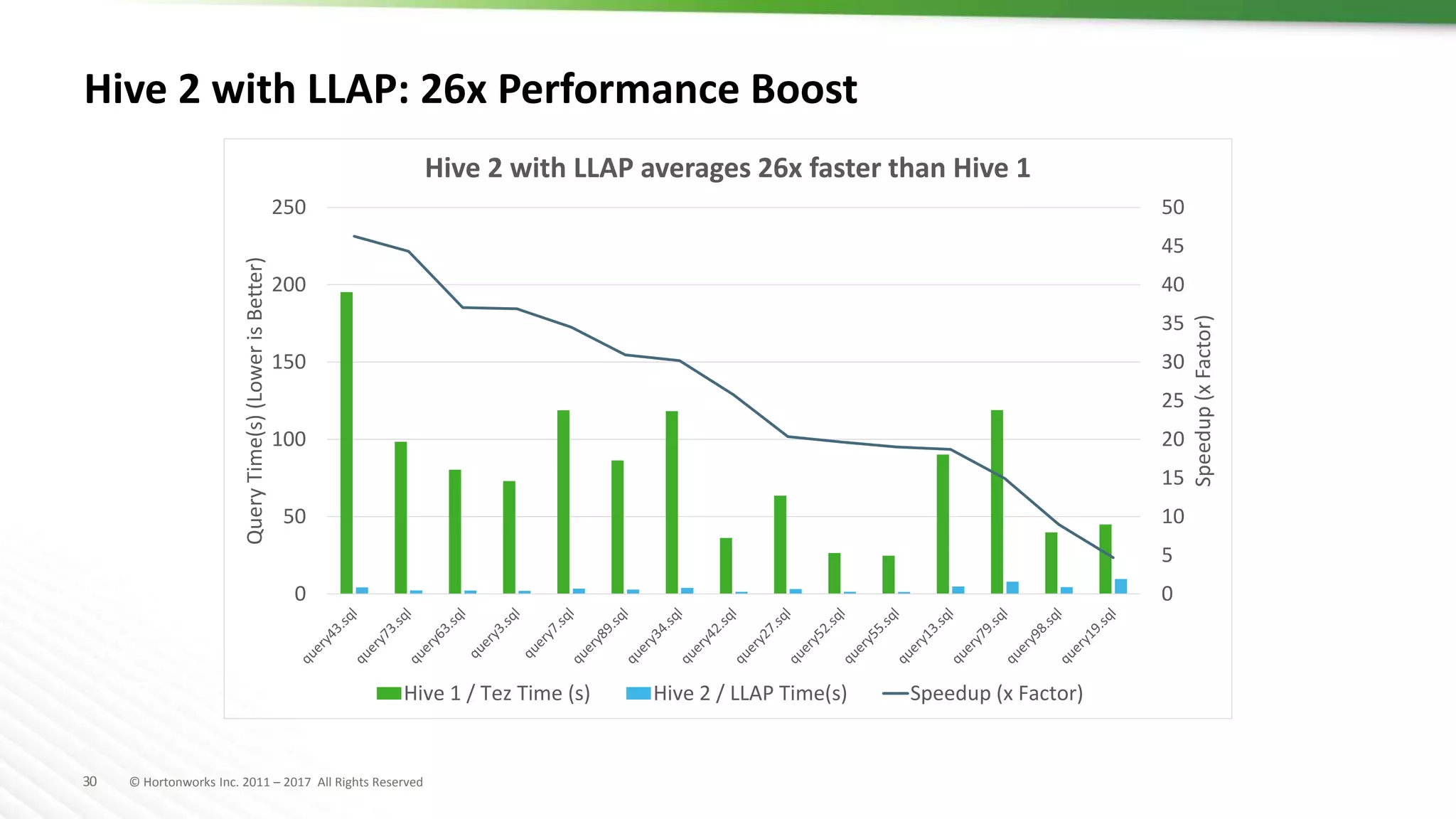

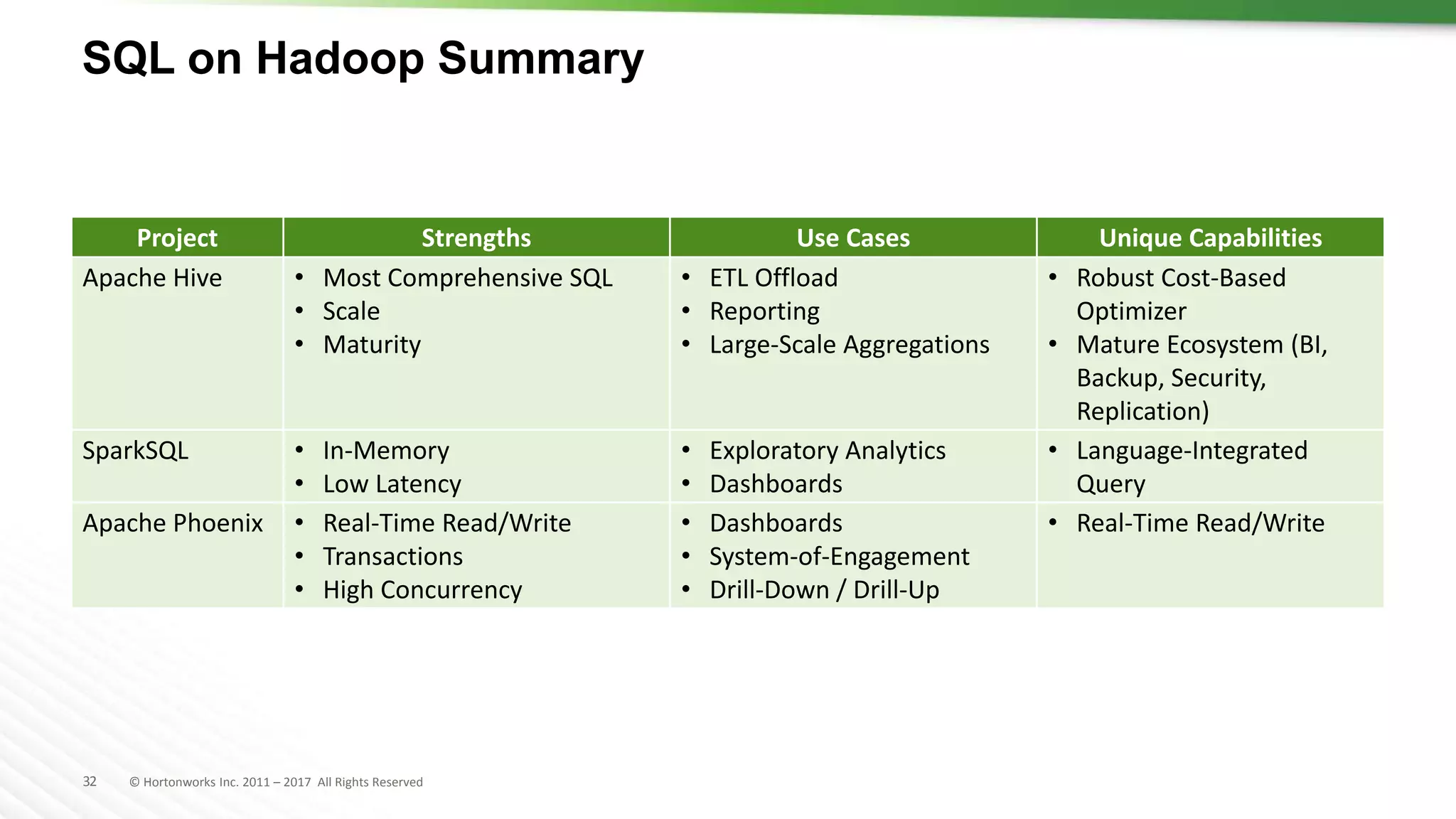
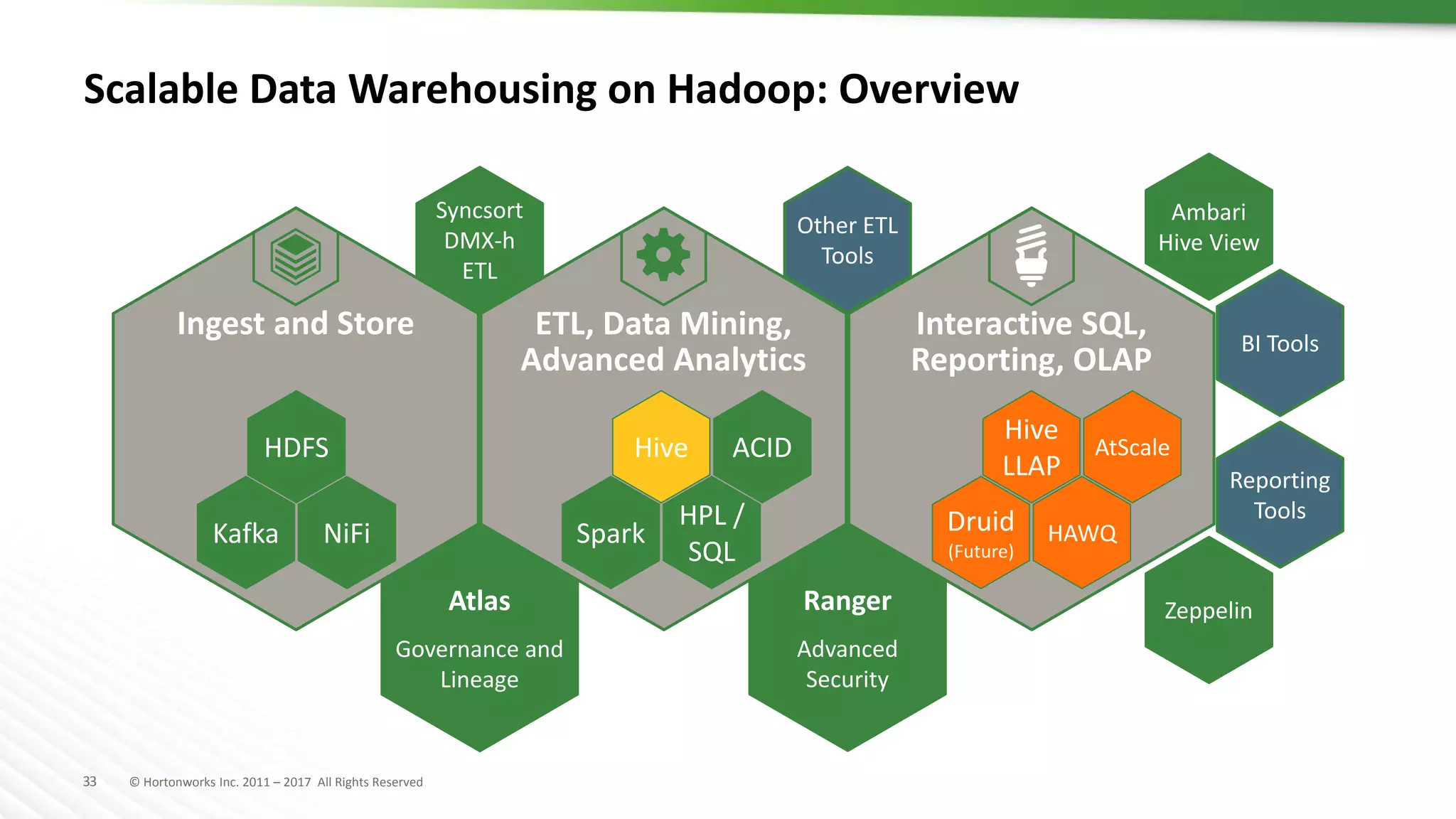


The document discusses SQL on Hadoop, highlighting the capabilities of various technologies like Apache Hive, SparkSQL, and Apache Phoenix for handling large-scale data analytics and real-time processing. It emphasizes the importance of understanding use cases, query patterns, and performance criteria when implementing SQL solutions in Hadoop environments. The presentation also covers innovations, strengths, and potential challenges associated with these technologies.





































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)

















