Download as PDF, PPTX


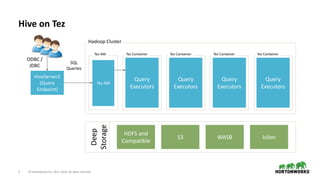
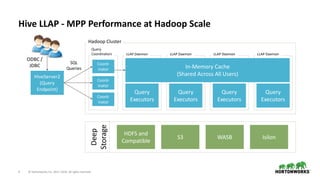
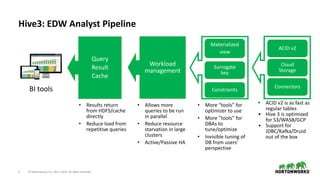









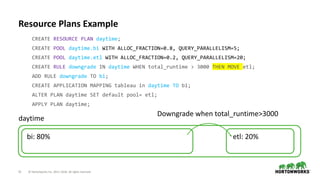

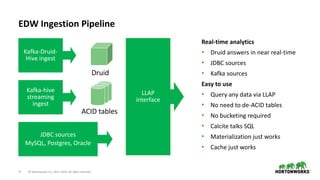
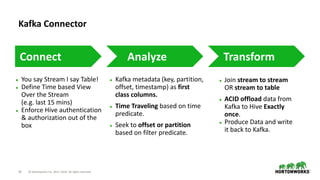
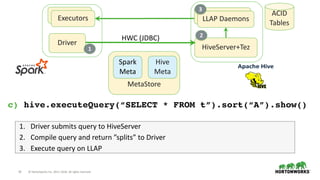
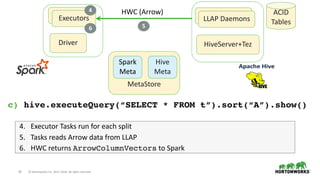


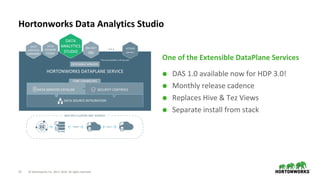
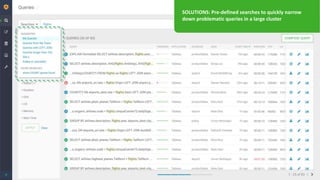
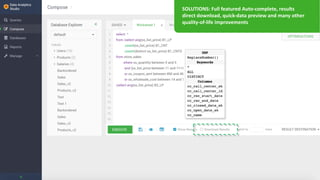
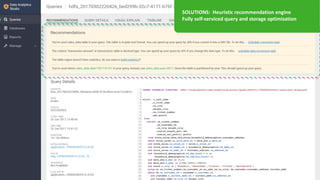
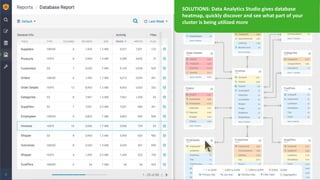
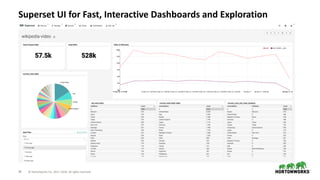

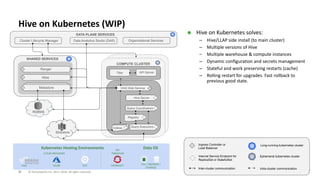



The document outlines the features and enhancements introduced in Apache Hive 3.0, including support for transactions, ACID operations, and new SQL capabilities designed for big data environments. It details improvements in workload management, data replication, and the integration of Hive with various data sources, along with performance optimizations for handling large-scale analytics. Additionally, it discusses the functionality of the Hive Data Analytics Studio and mentions plans for Hive on Kubernetes.






















































































