Downloaded 5,461 times































The document provides an overview of big data architectures and the data lake concept. It discusses why organizations are adopting data lakes to handle increasing data volumes and varieties. The key aspects covered include: - Defining top-down and bottom-up approaches to data management - Explaining what a data lake is and how Hadoop can function as the data lake - Describing how a modern data warehouse combines features of a traditional data warehouse and data lake - Discussing how federated querying allows data to be accessed across multiple sources - Highlighting benefits of implementing big data solutions in the cloud - Comparing shared-nothing, massively parallel processing (MPP) architectures to symmetric multi-processing (
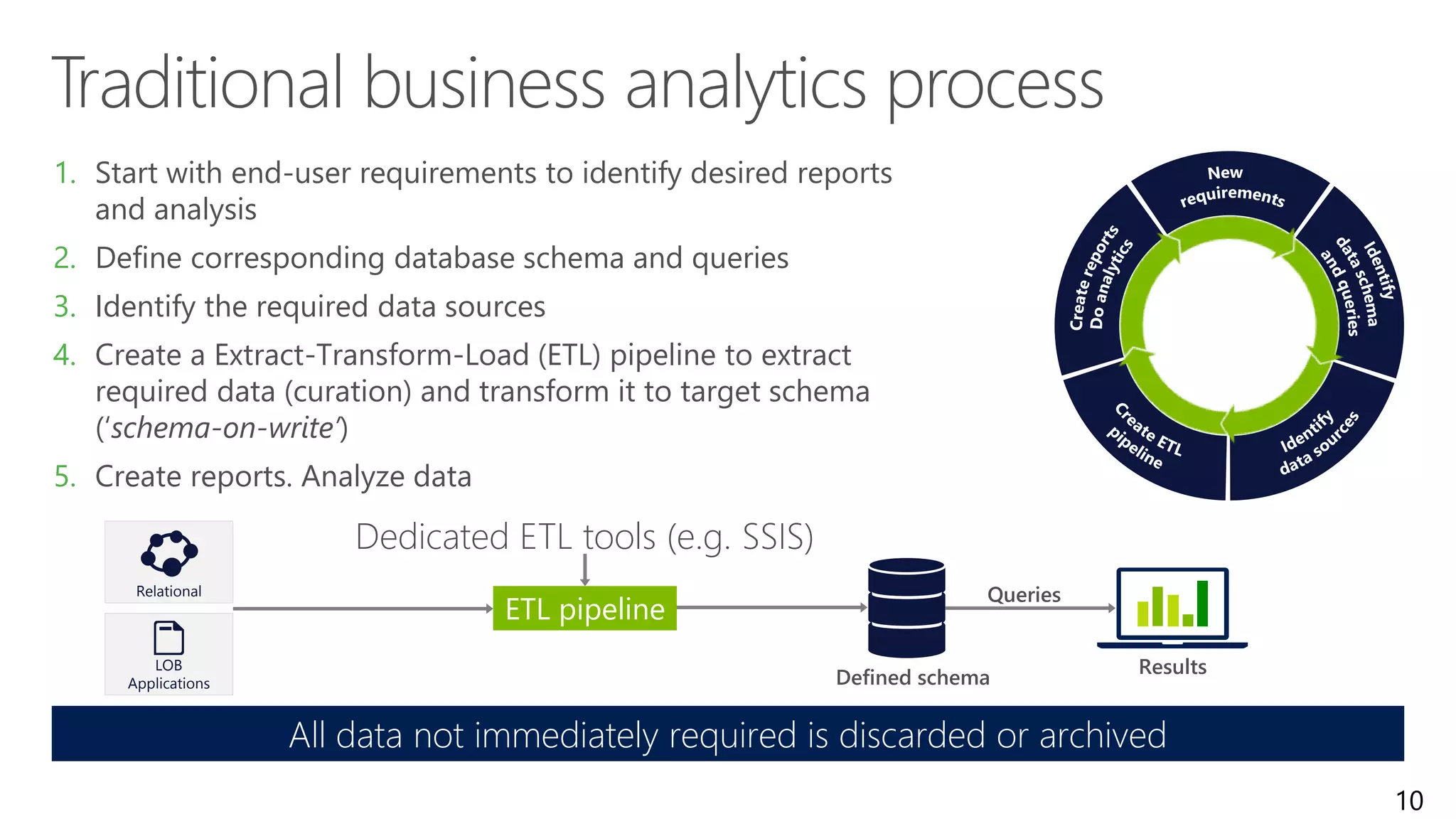
Introduces big data architectures, data lakes, and key topics to be covered, including the evolution of data warehouses.
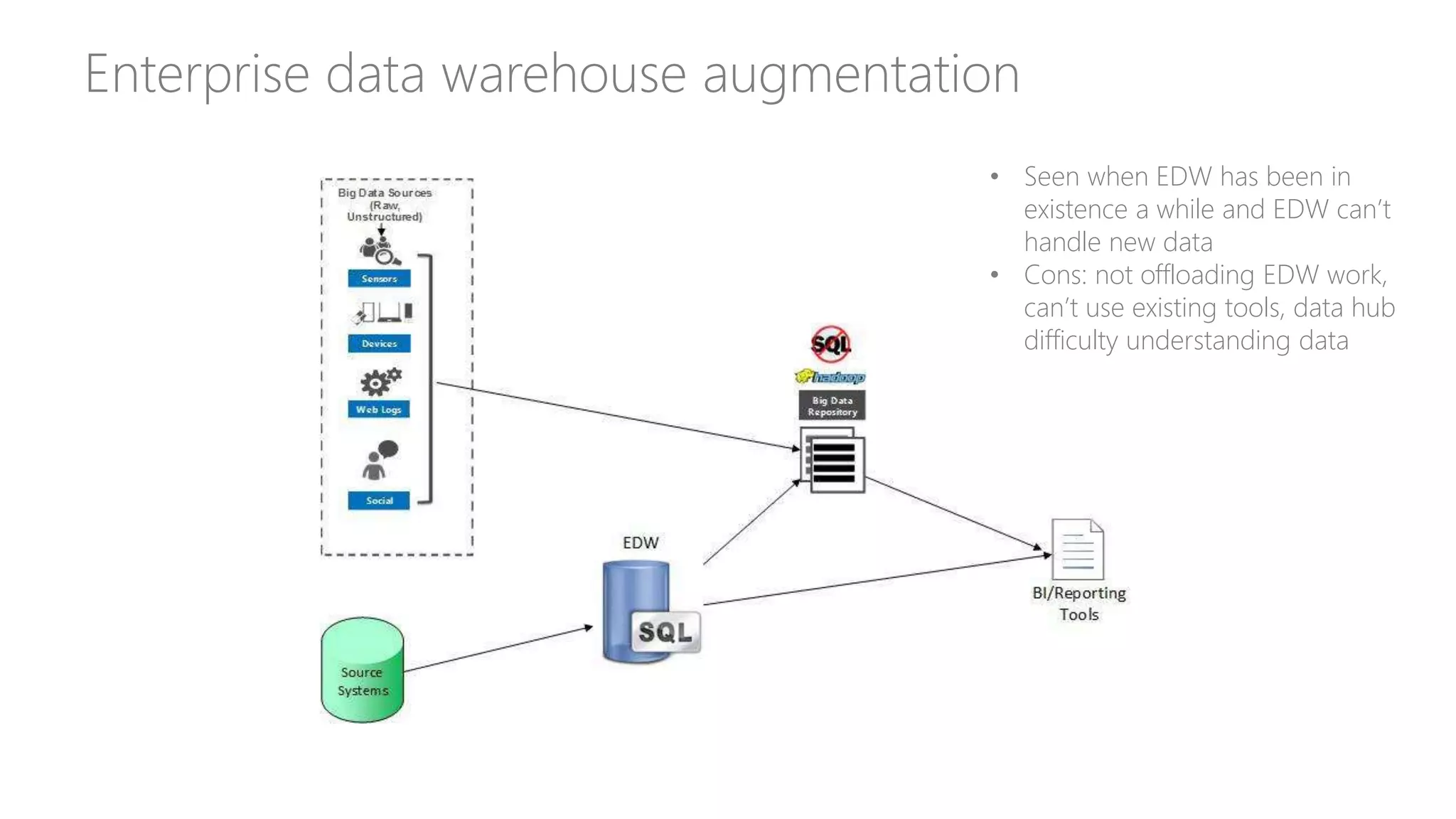
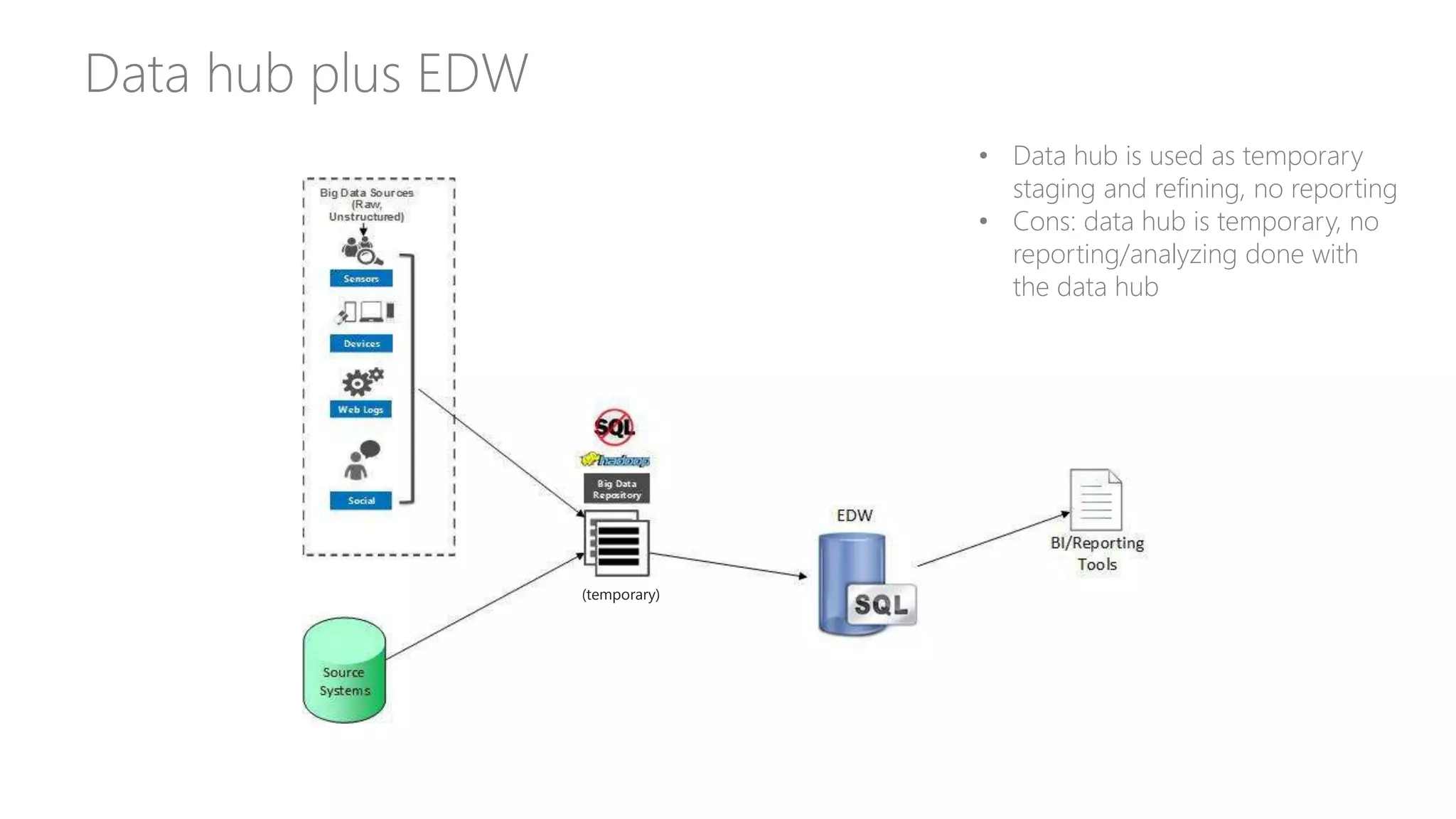
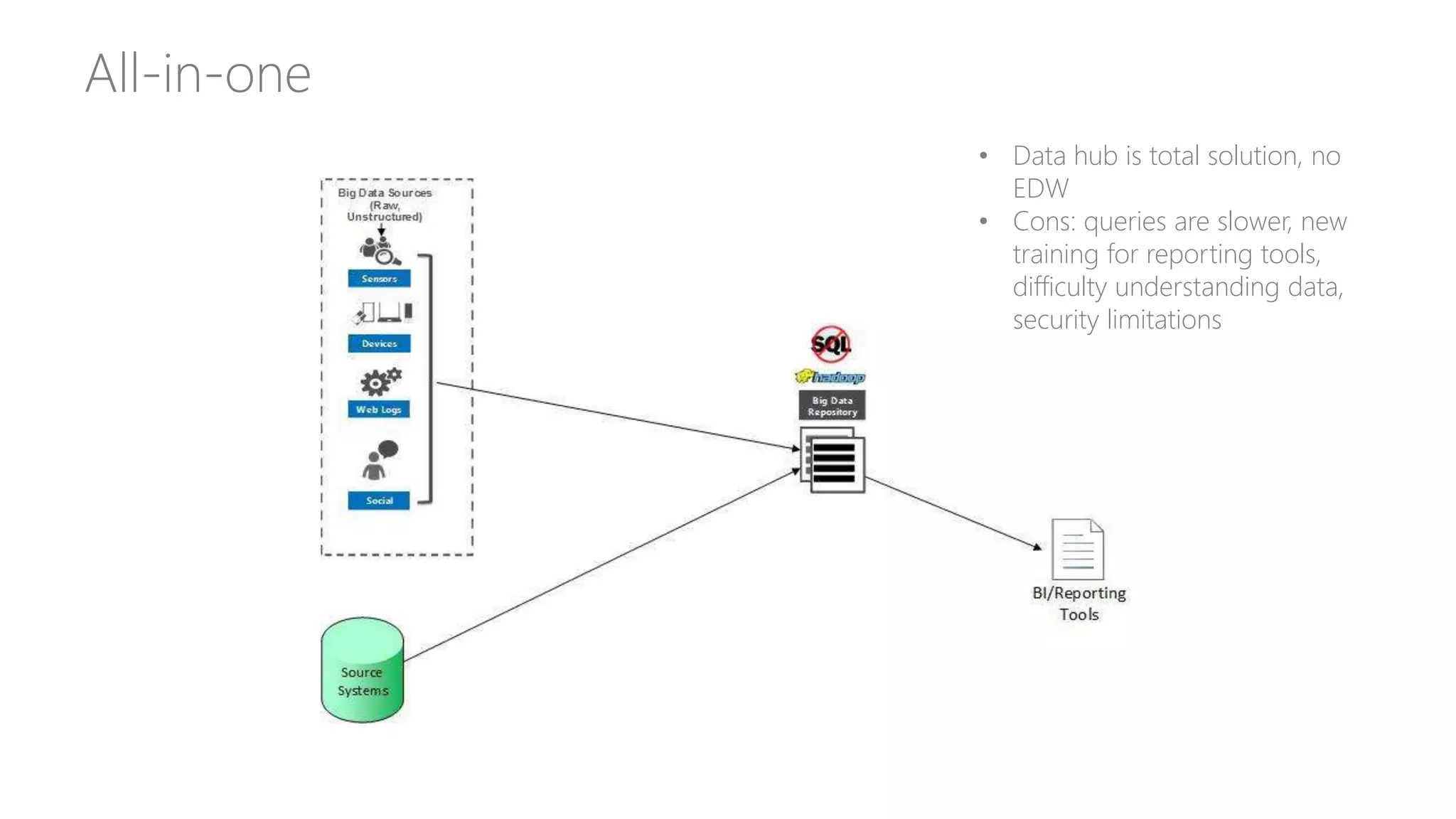
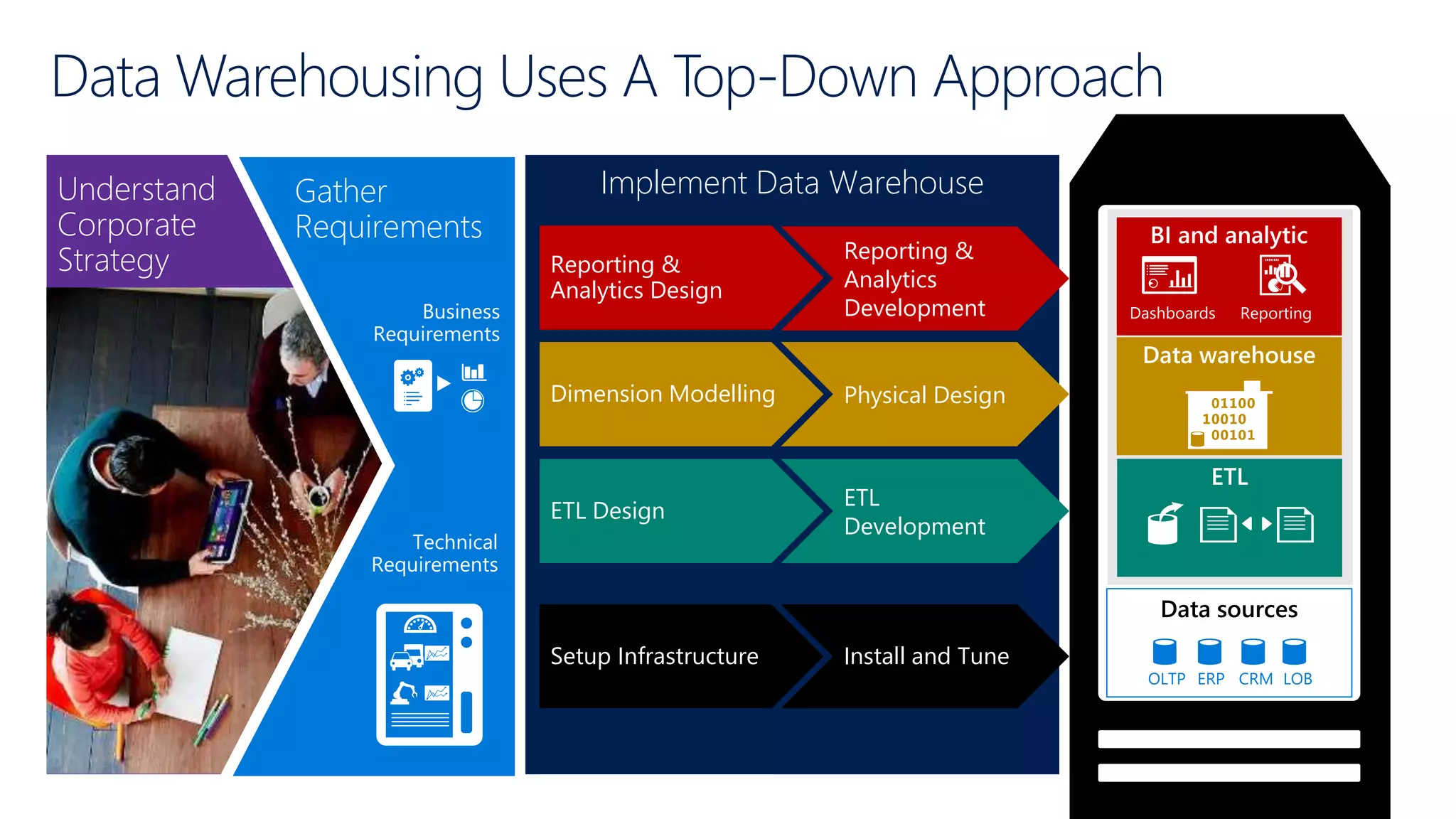
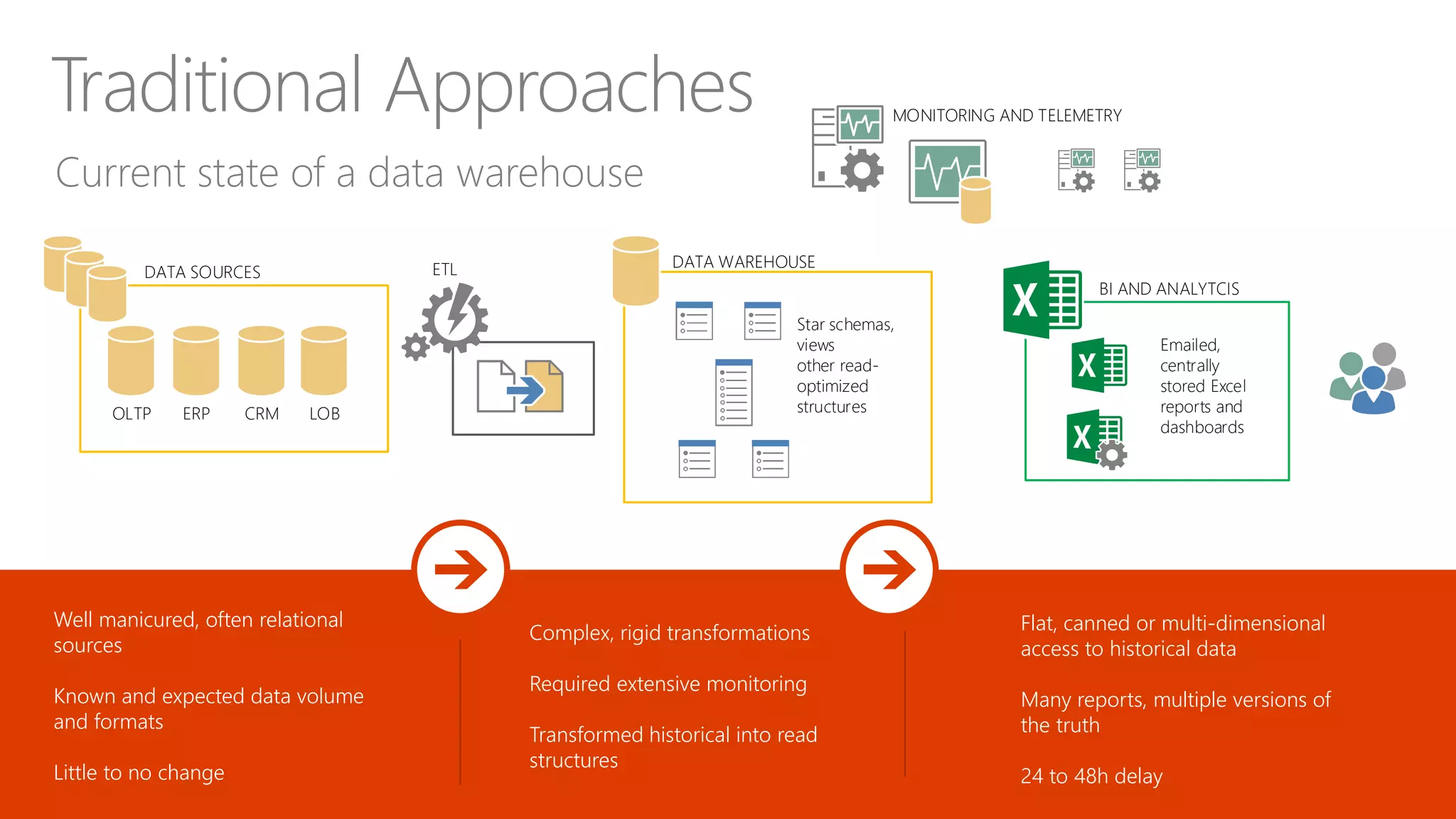
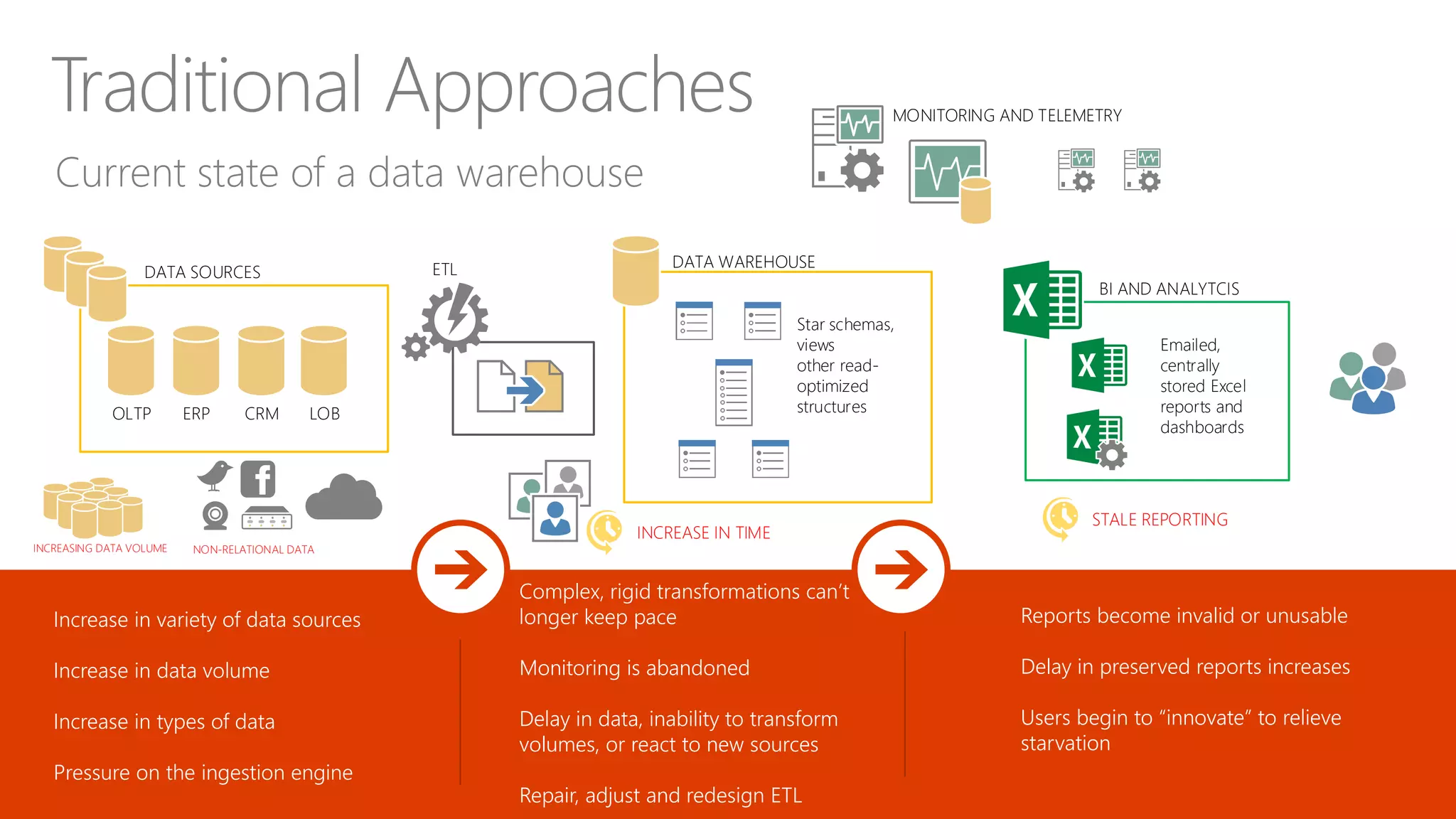
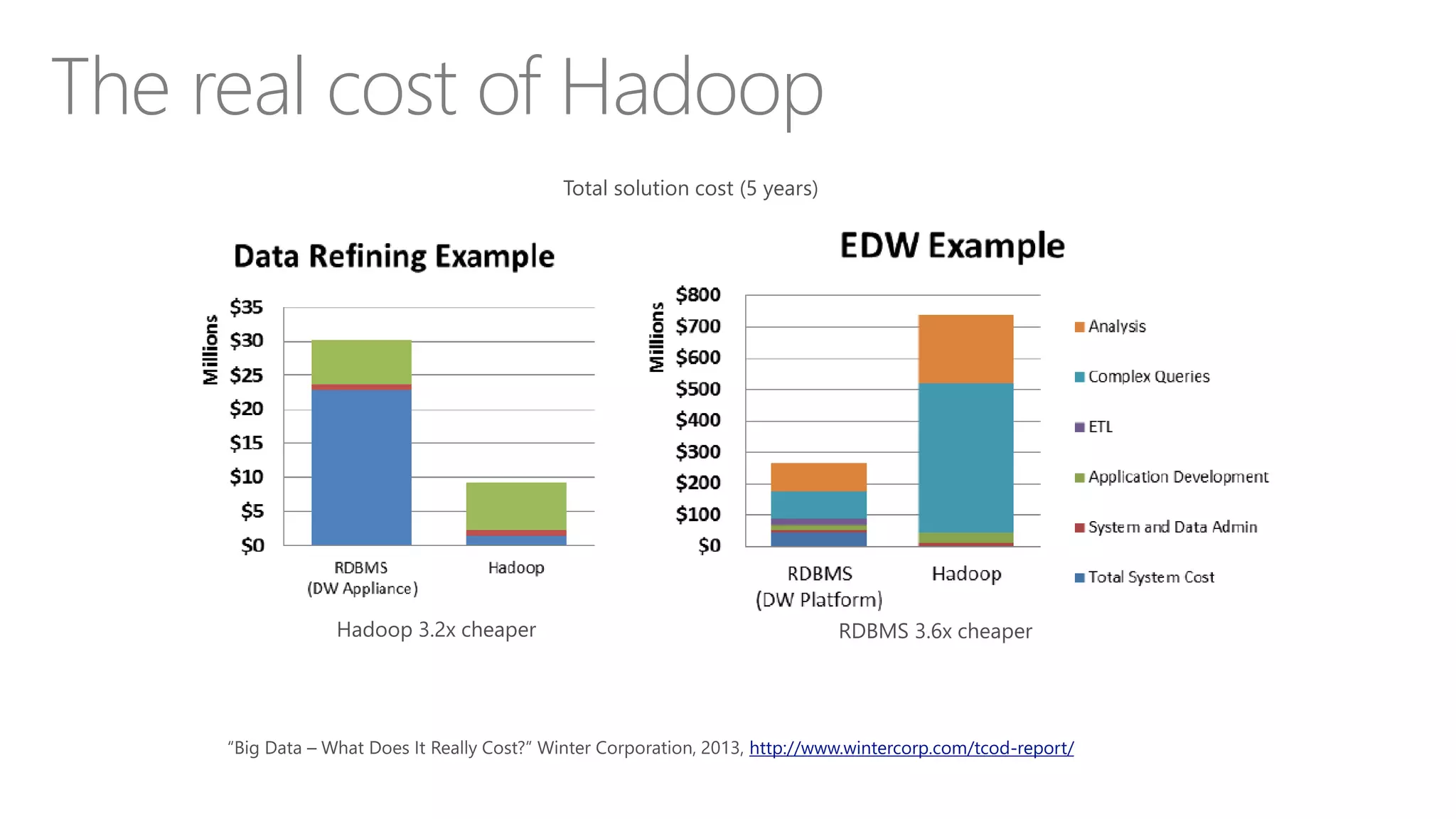
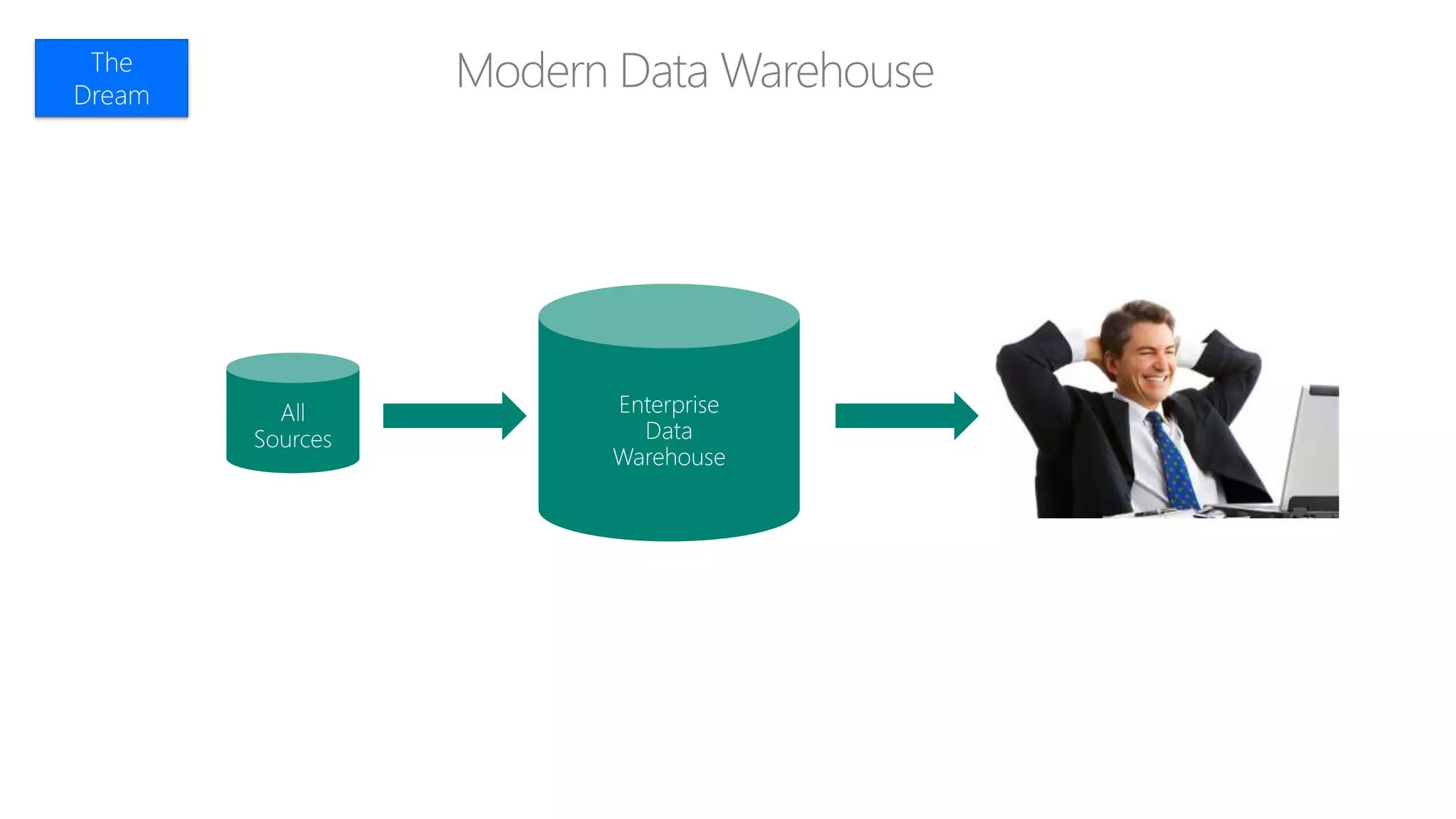
Explores how enterprise data warehouses (EDW) are augmented and presents different scenarios, emphasizing data integration.
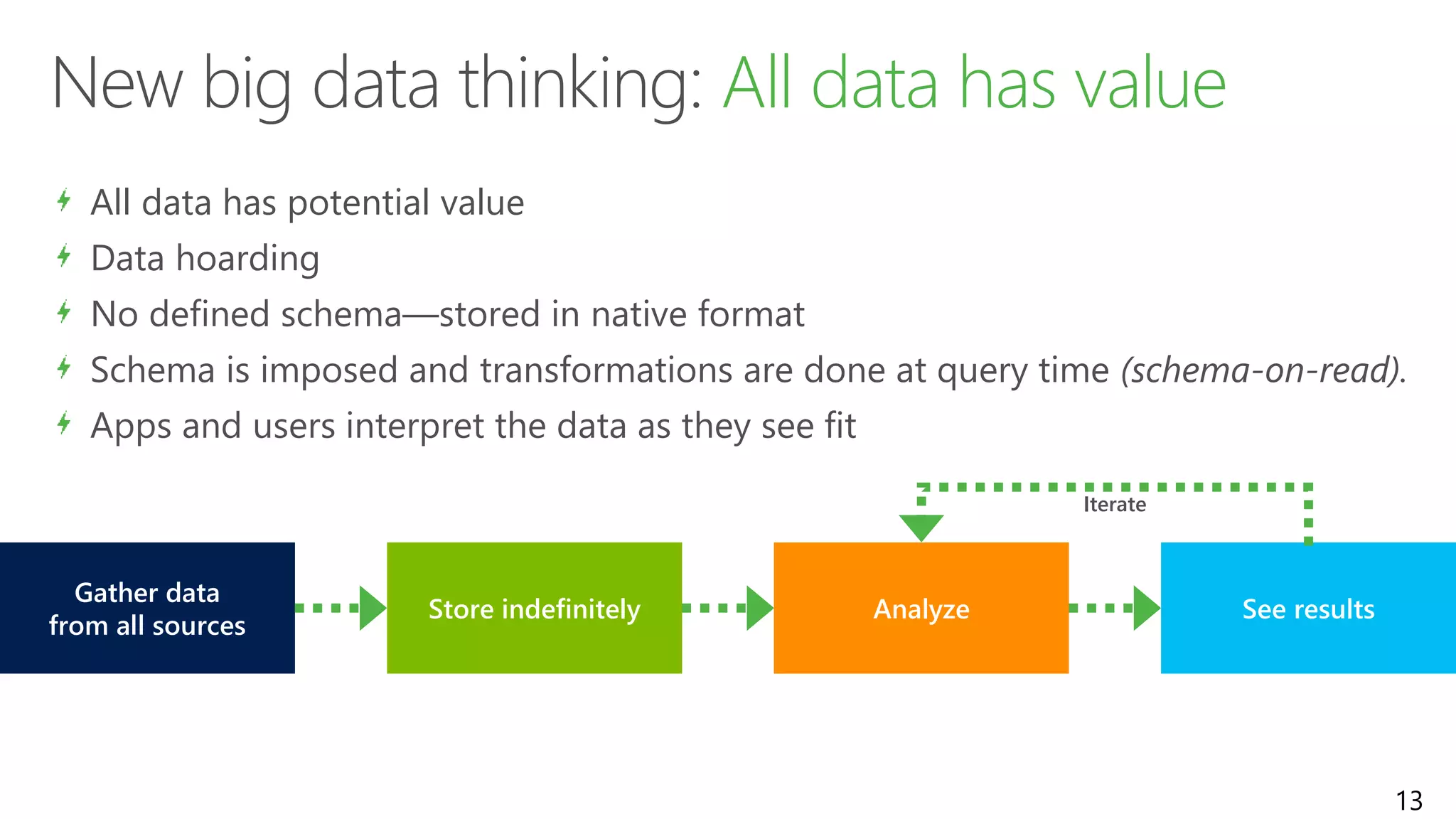
Discusses why data lakes are essential for handling diverse data types and effective analytics management.
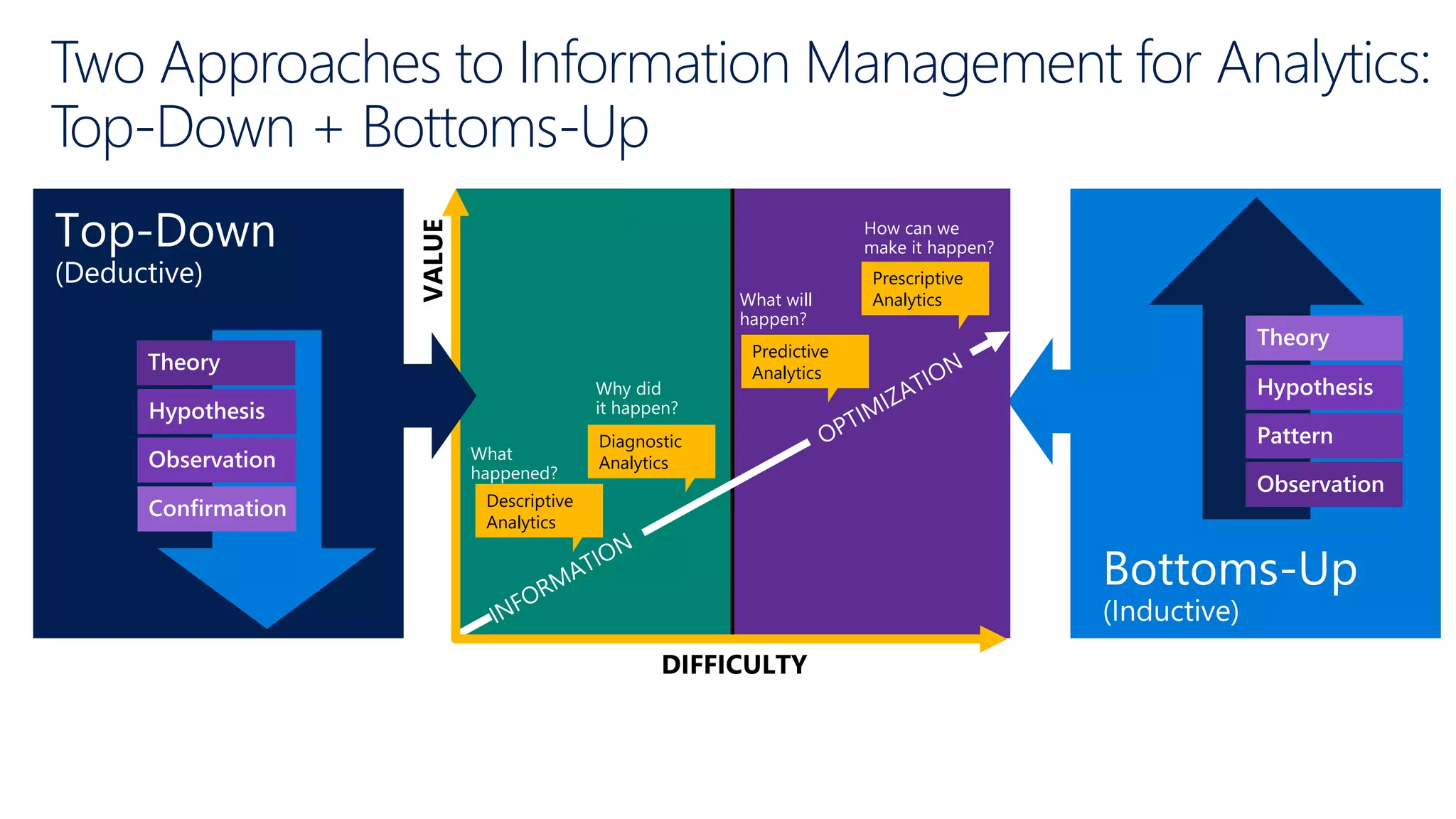
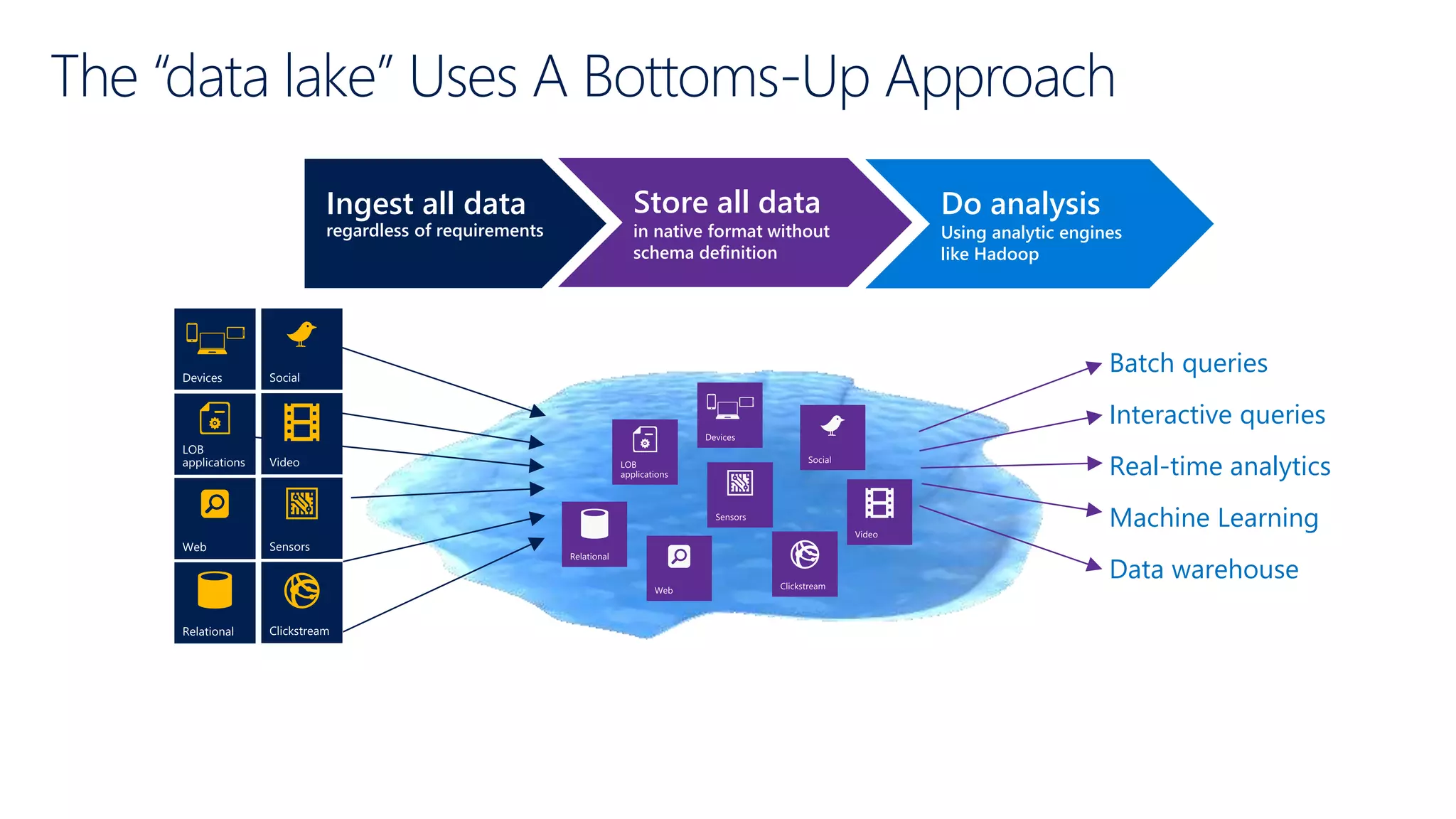
Contrasts top-down versus bottom-up approaches for data management, with a focus on data lake integration.
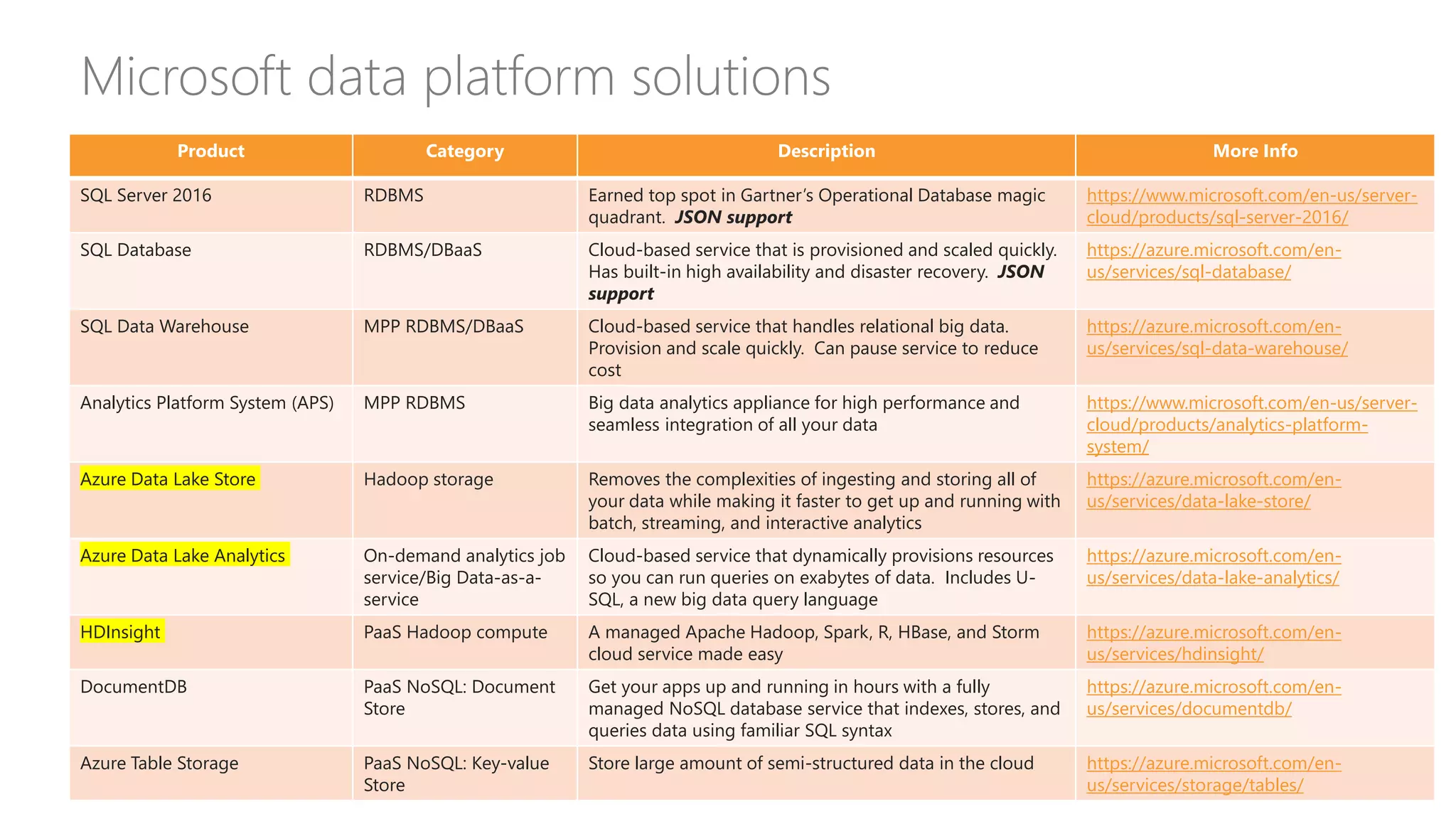
Defines data lakes, their storage capabilities, and contrasts current data warehouse limitations versus potential.
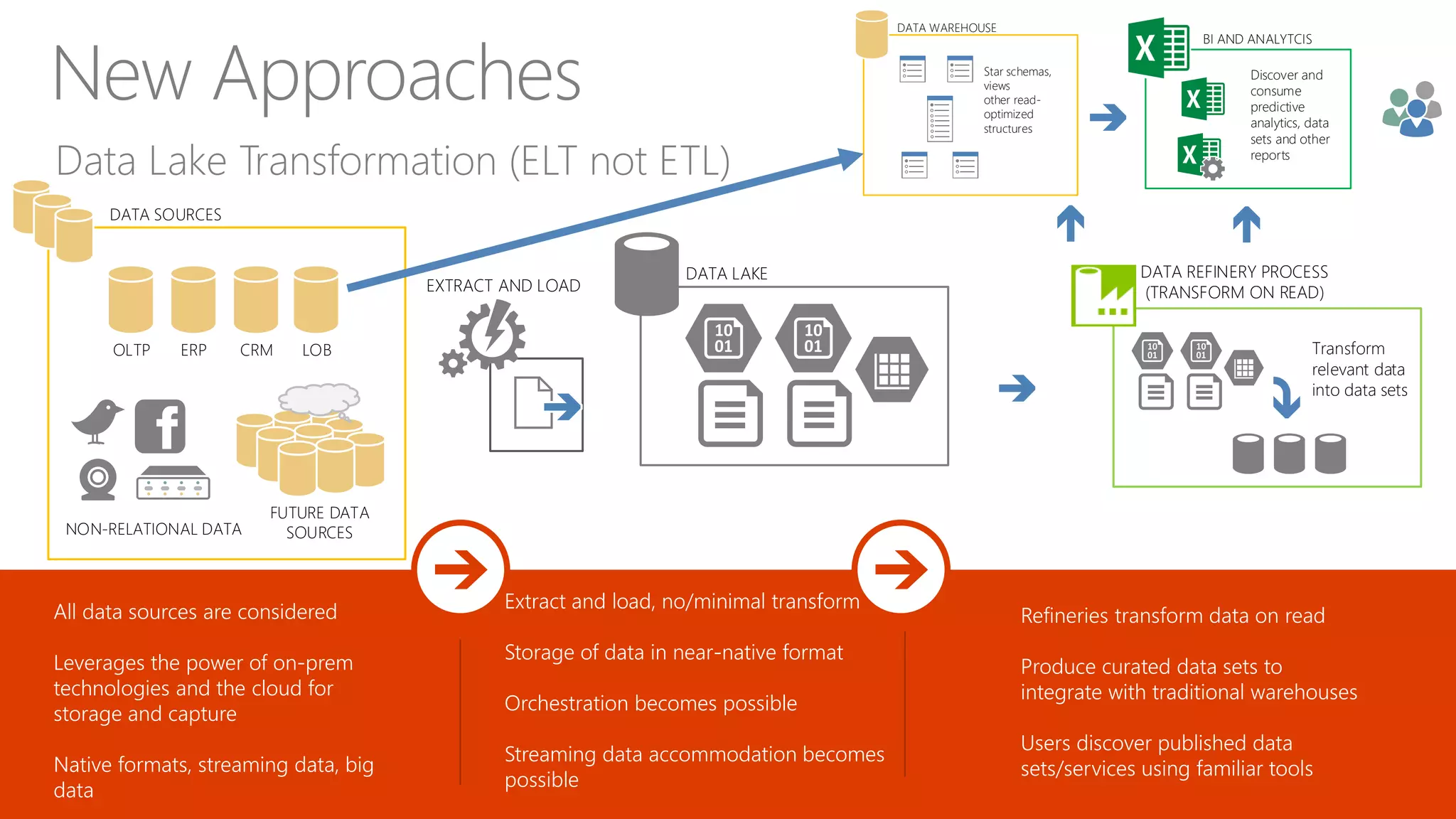
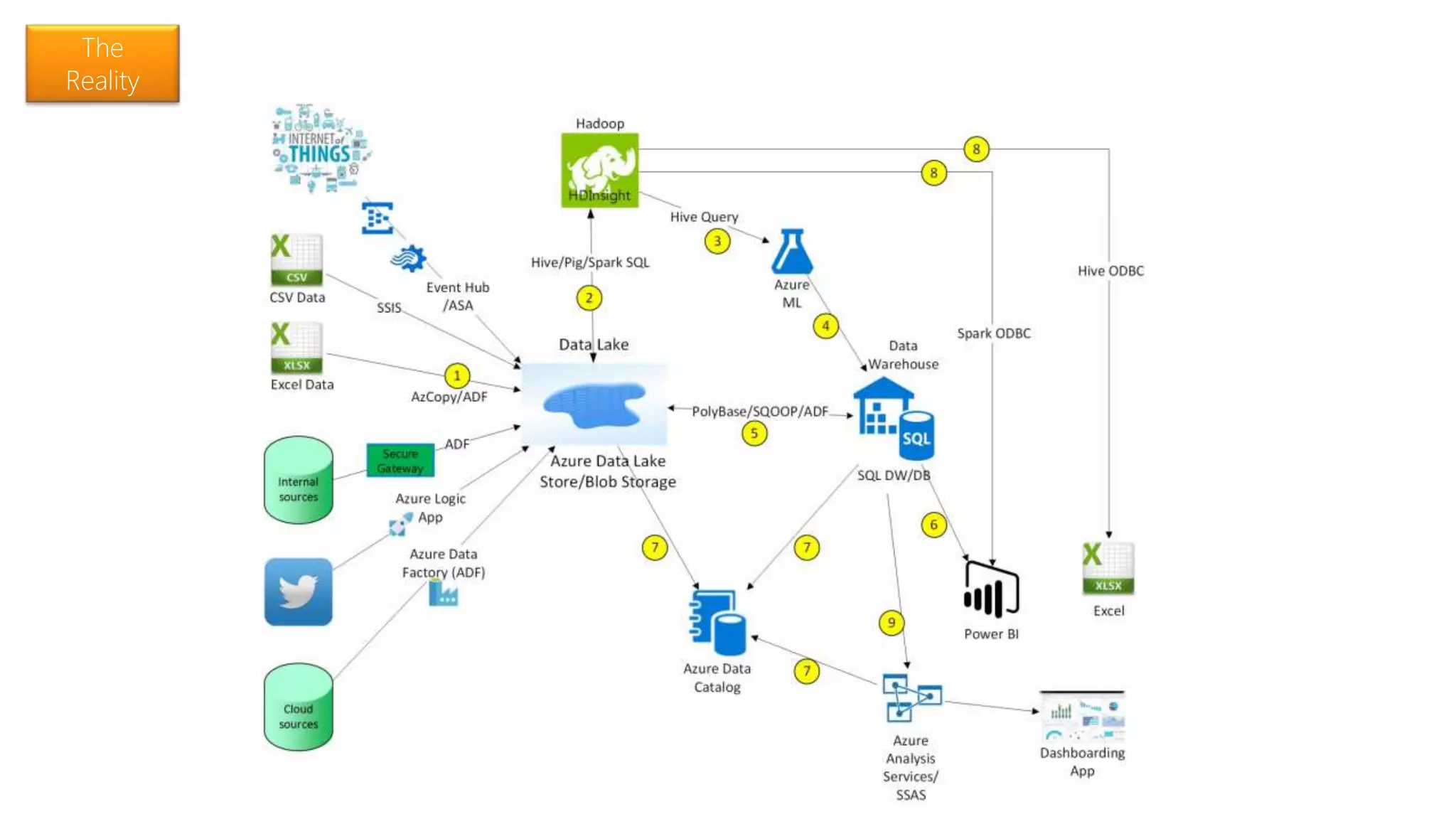
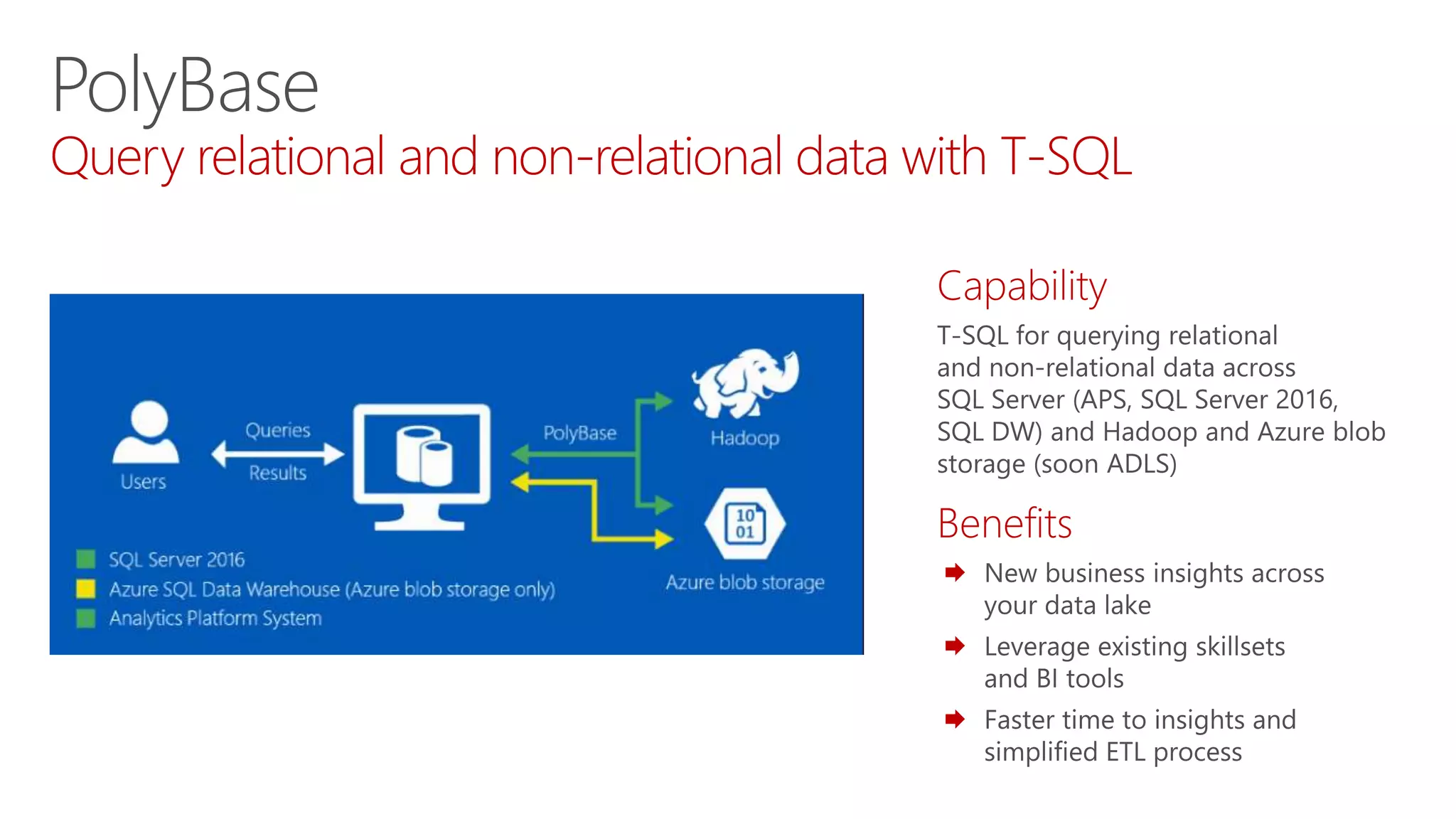
Highlights the transition from ETL to ELT processes, discusses data lake architecture, and emphasizes flexible data usage.
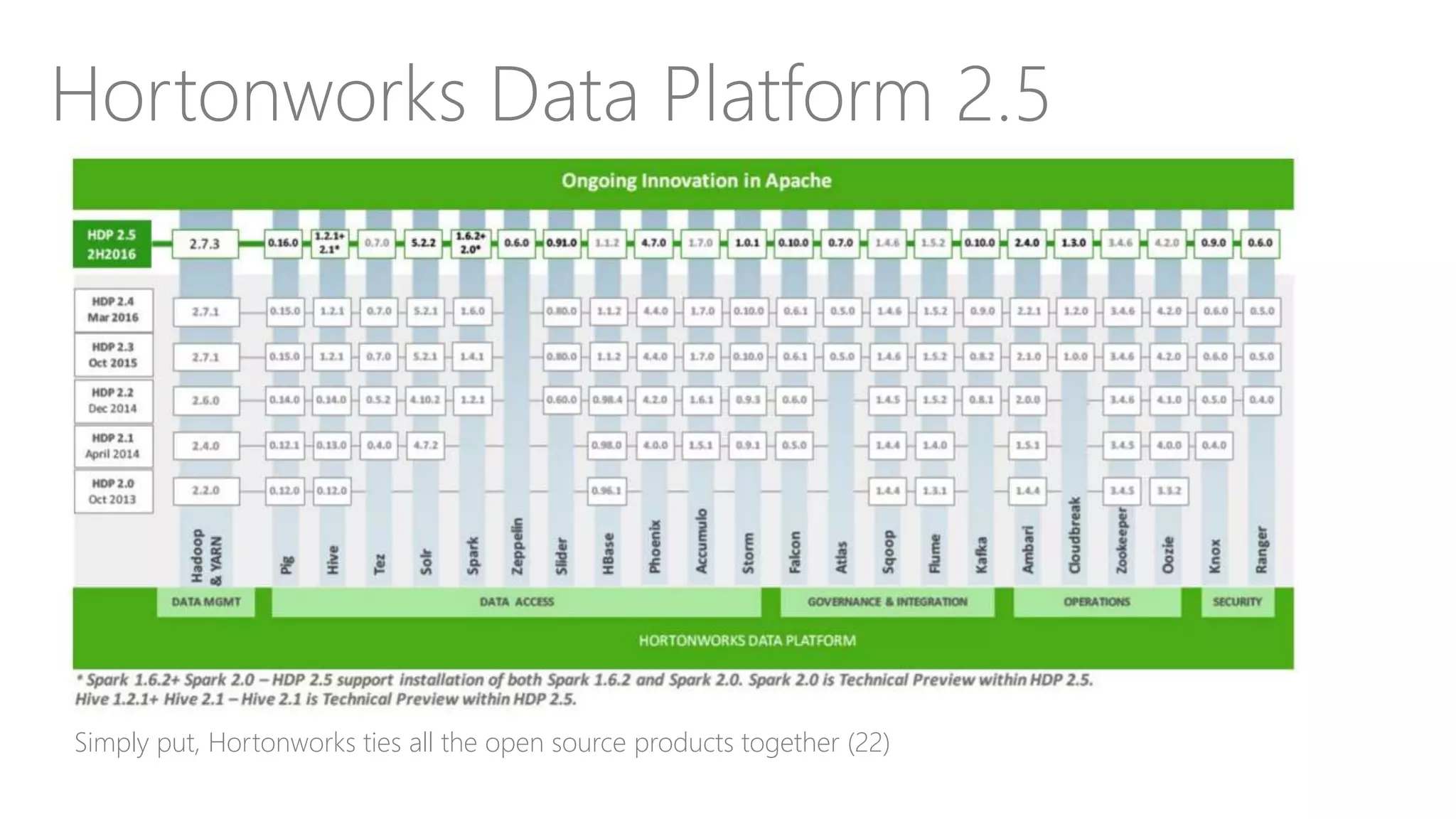
Introduces Hadoop as a preferred technology for data lakes, detailing its components and addressing performance considerations.
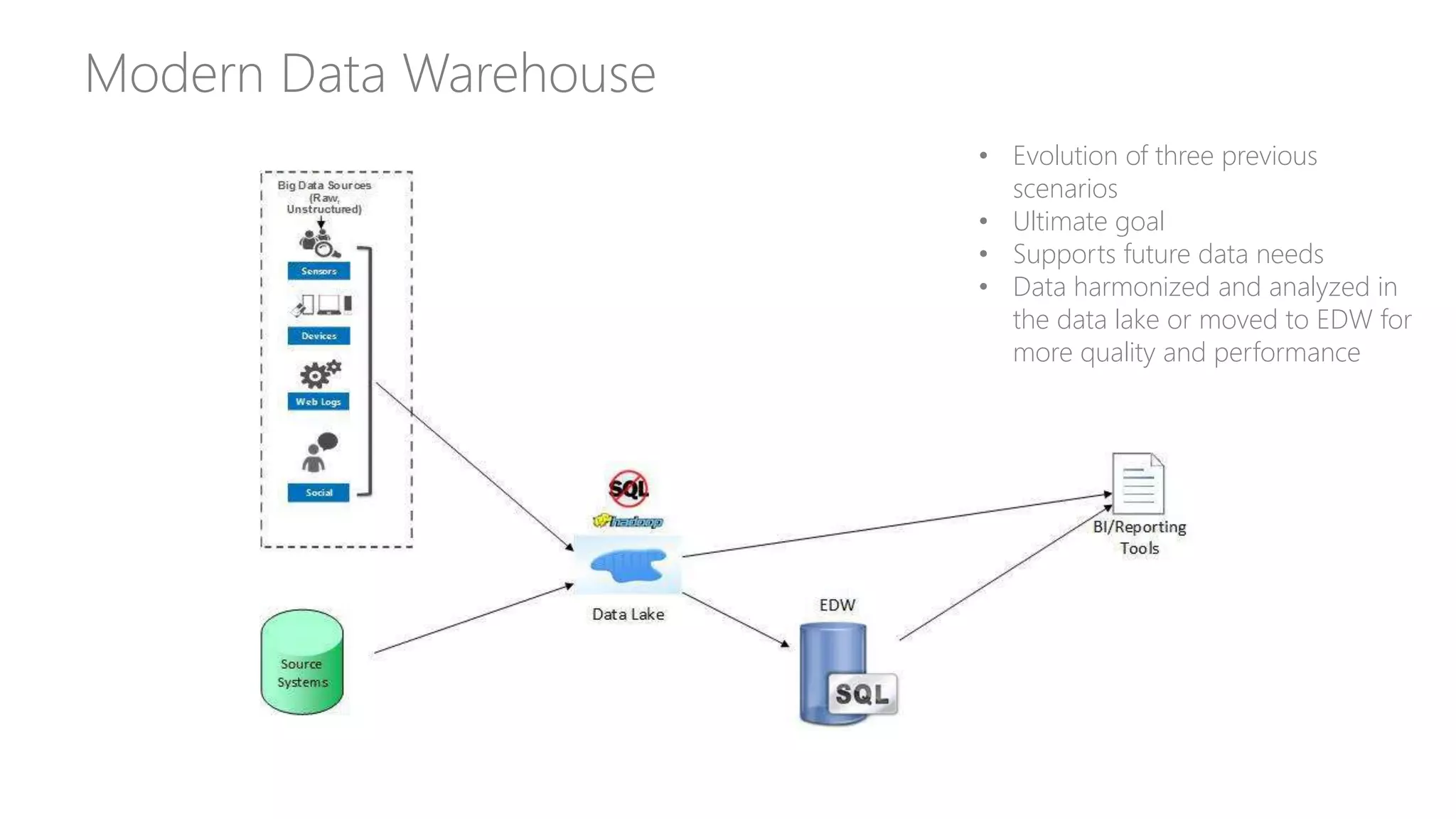
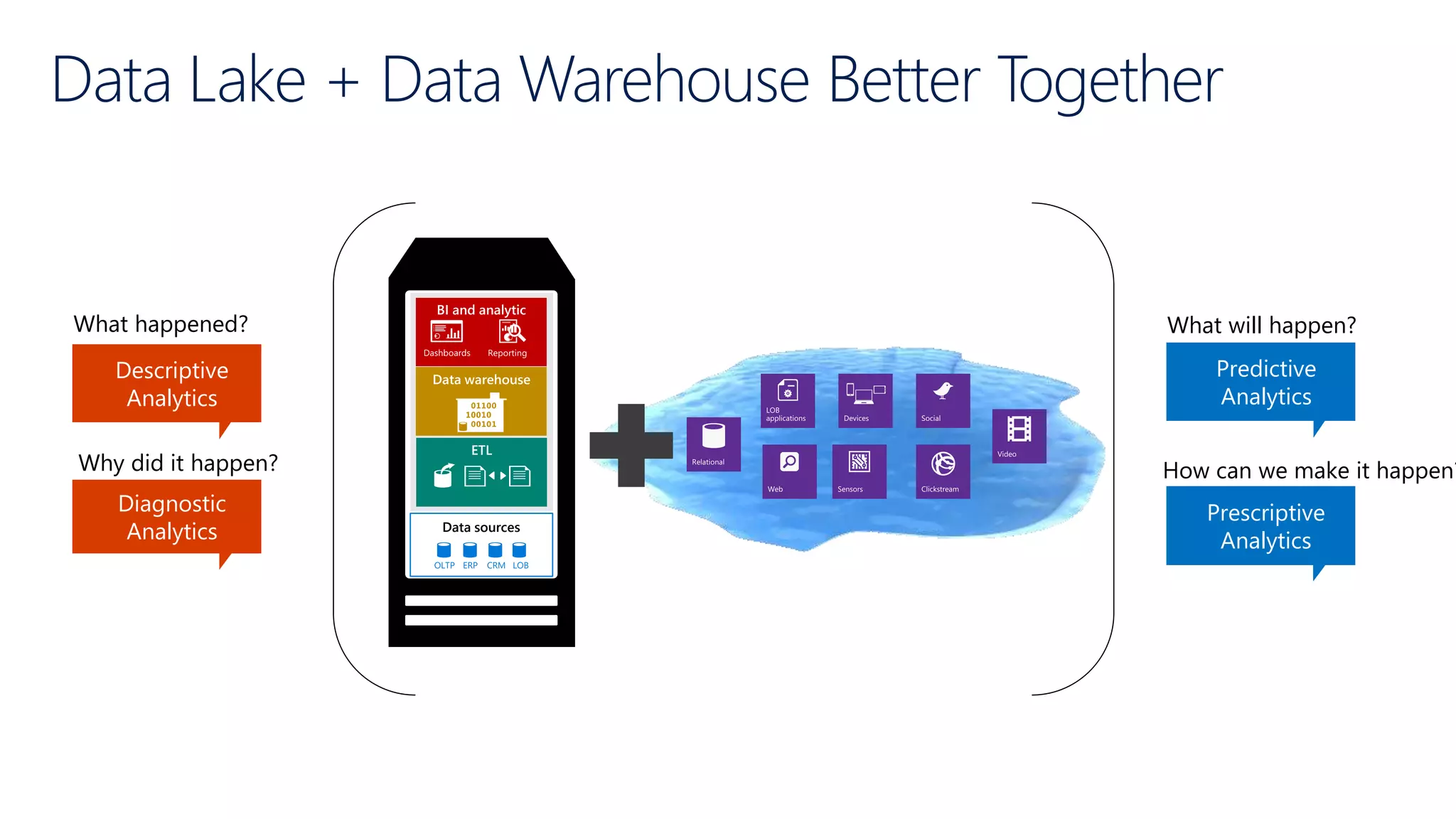
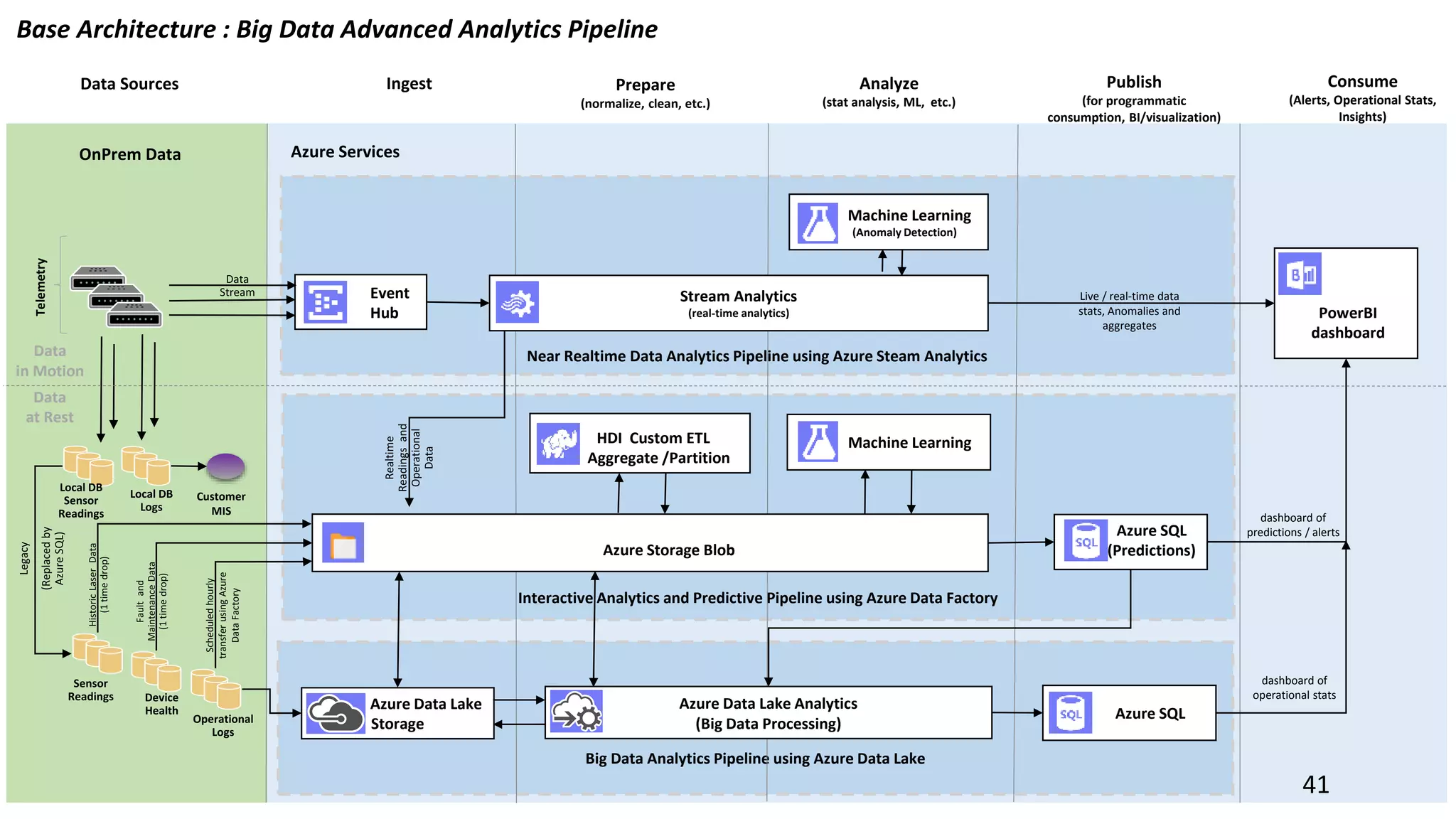
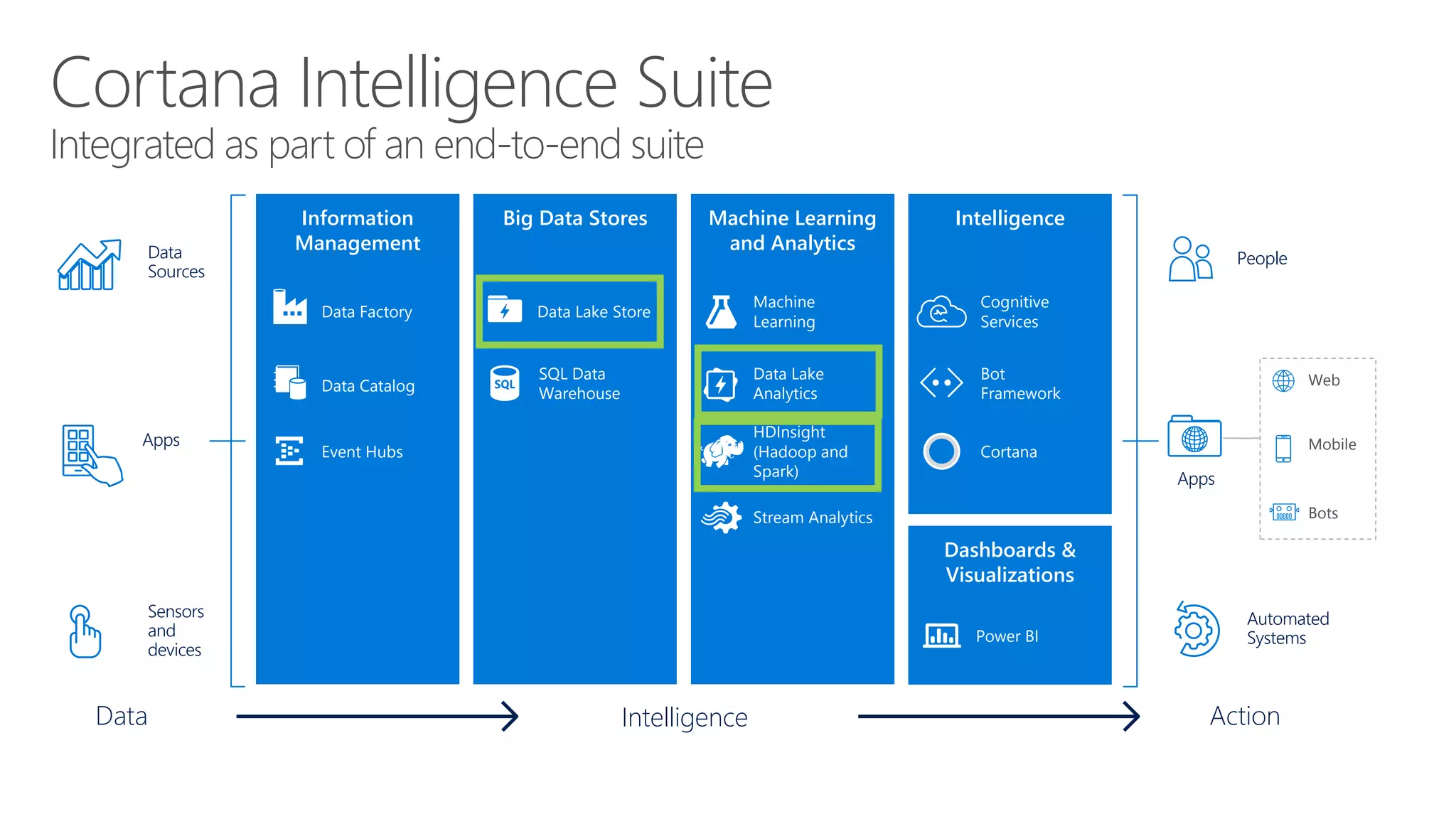
Illustrates use cases for integrating Hadoop with data warehousing and outlines the future needs of modern data solutions.
Outlines the roles of data lakes and data warehouses in analytics, emphasizing efficient reporting and operational efficiency.
Discuss cloud benefits, considerations for on-premise versus cloud solutions, and strategies for managing data efficiently.
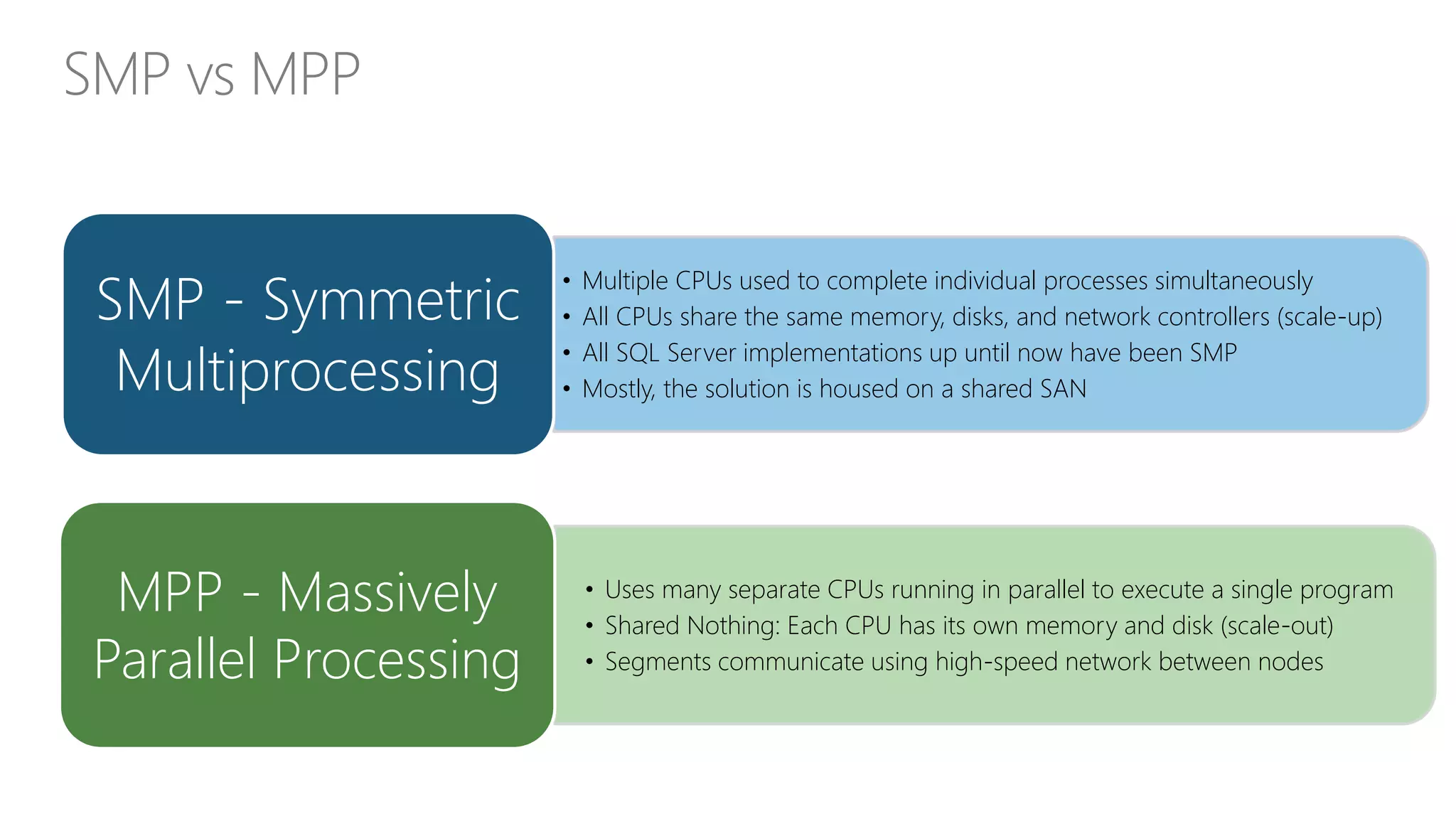
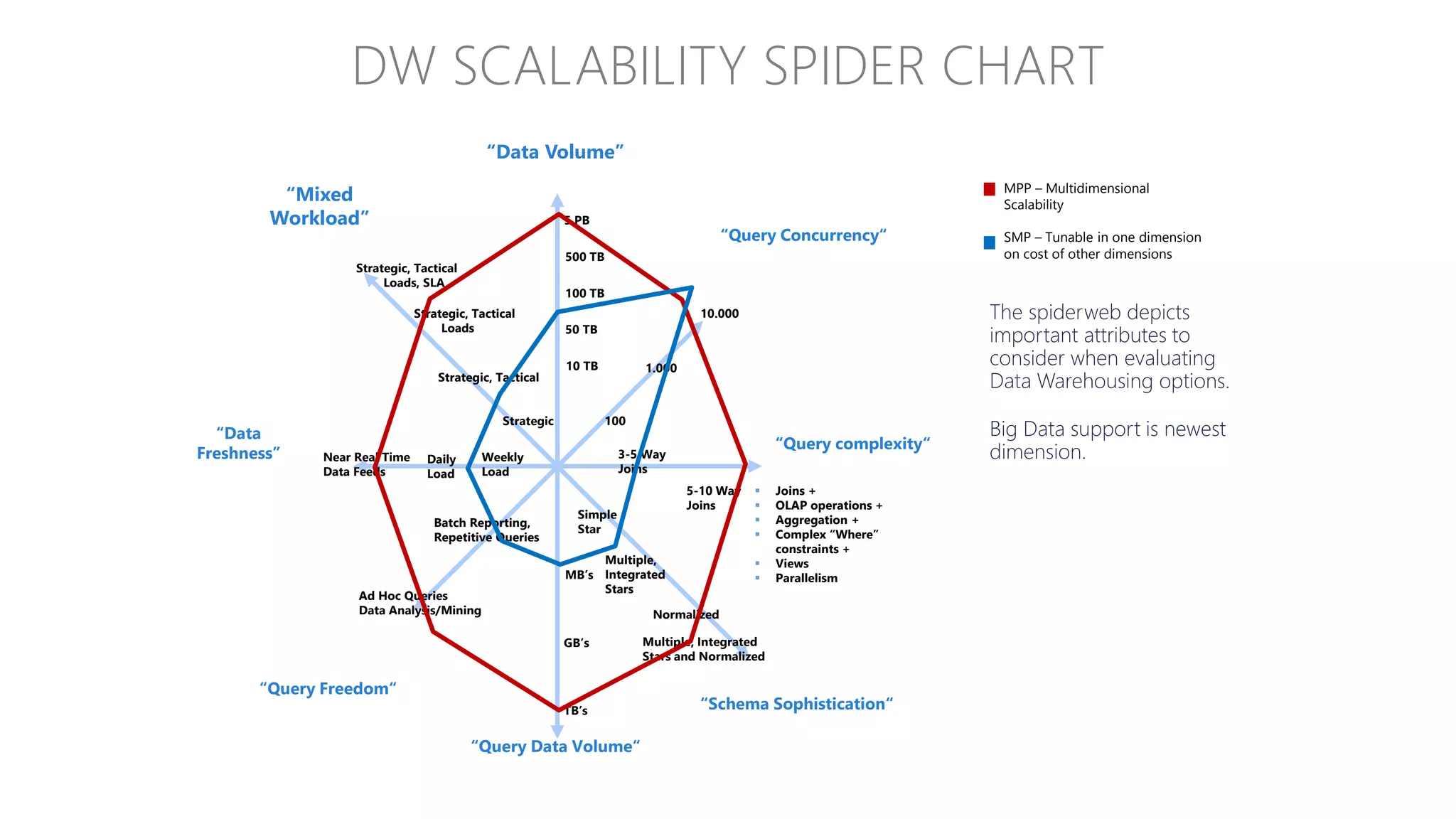
Explains the differences between symmetric and massively parallel processing, focusing on performance and scalability.
Summarizes the presentation's key points on the significance of data in business opportunities and ends with resources for further learning.























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












