








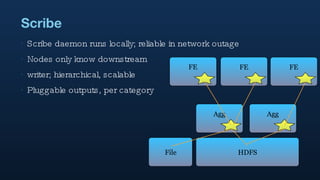



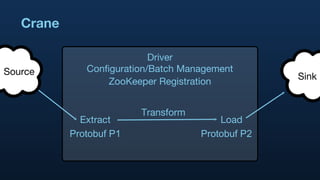





















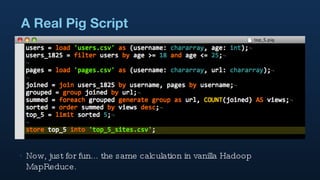












1. Hadoop is used extensively at Twitter to handle large volumes of data from logs and other sources totaling 7TB per day. Tools like Scribe and Crane are used to input data and Elephant Bird and HBase for storage. 2. Pig is used for data analysis on these large datasets to perform tasks like counting, correlating, and researching trends in users and tweets. 3. The results of these analyses are used to power various internal and external Twitter products and keep the business agile through ad-hoc analyses.








































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)
