Downloaded 500 times




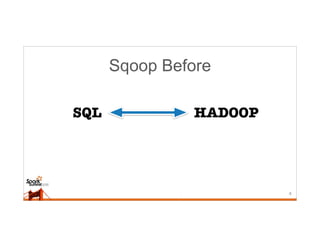

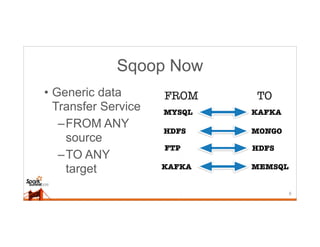
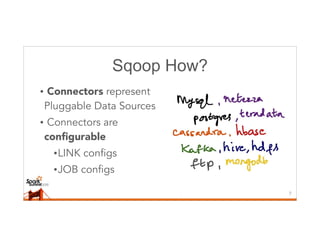
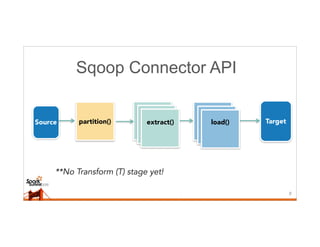










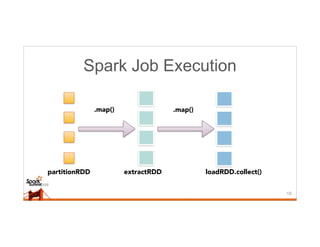

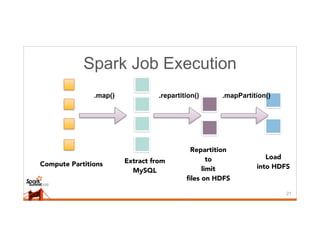
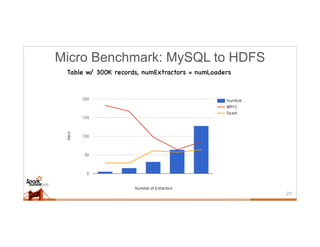
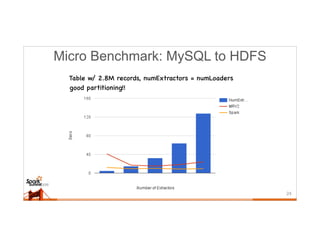



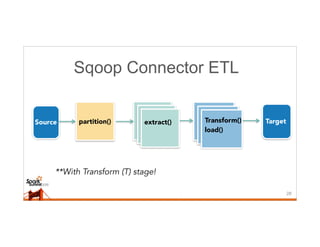

This document discusses running Sqoop jobs on Apache Spark for faster data ingestion into Hadoop. The authors describe how Sqoop jobs can be executed as Spark jobs by leveraging Spark's faster execution engine compared to MapReduce. They demonstrate running a Sqoop job to ingest data from MySQL to HDFS using Spark and show it is faster than using MapReduce. Some challenges encountered are managing dependencies and job submission, but overall it allows leveraging Sqoop's connectors within Spark's distributed processing framework. Next steps include exploring alternative job submission methods in Spark and adding transformation capabilities to Sqoop connectors.






![[Ndc11 박민근] deferred shading](https://cdn.slidesharecdn.com/ss_thumbnails/ndc11deferredshading-110602220043-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

![[GitOps] Argo CD on GKE (v0.9.2).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/gitopsargocdongkev0-230424043339-b312ca19-thumbnail.jpg?width=640&height=640&fit=bounds)




![[오픈소스컨설팅]Docker기초 실습 교육 20181113_v3](https://cdn.slidesharecdn.com/ss_thumbnails/oscdockereducation20181113hanv3-181113075418-thumbnail.jpg?width=640&height=640&fit=bounds)



![[오픈소스컨설팅]Scouter 설치 및 사용가이드(JBoss)](https://cdn.slidesharecdn.com/ss_thumbnails/scouterjboss-160310001021-thumbnail.jpg?width=640&height=640&fit=bounds)





























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)





