Download as PDF, PPTX

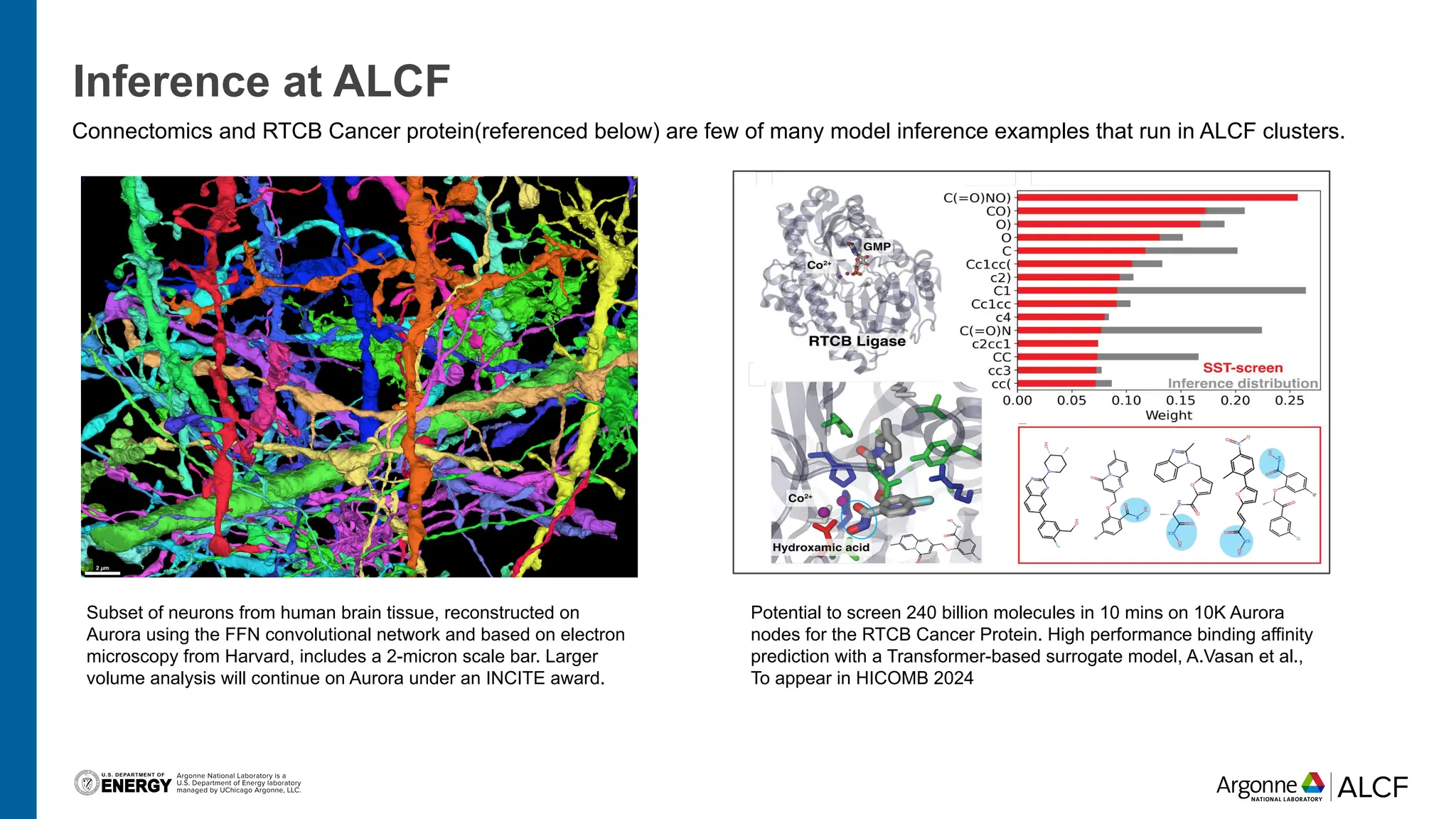
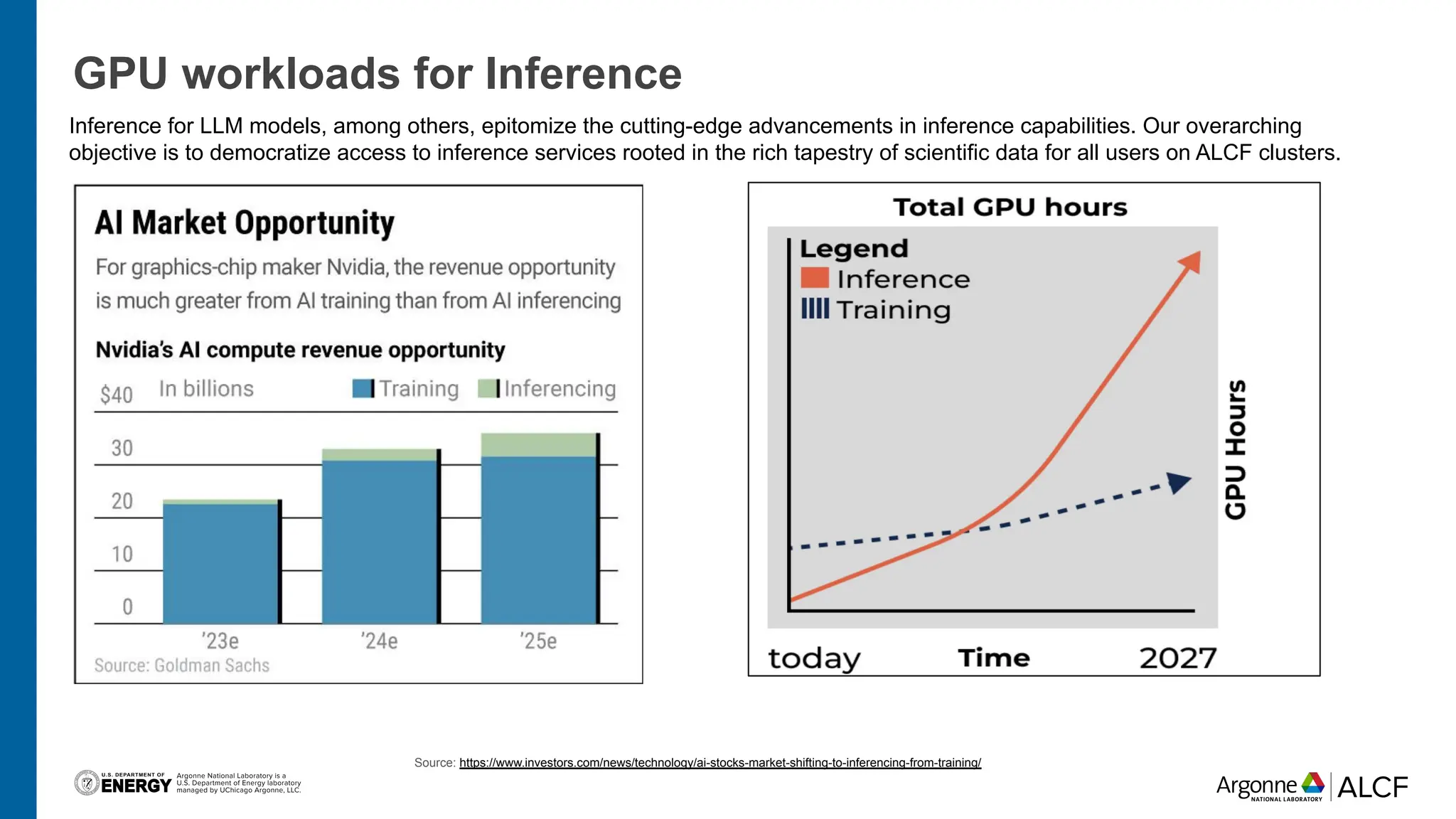

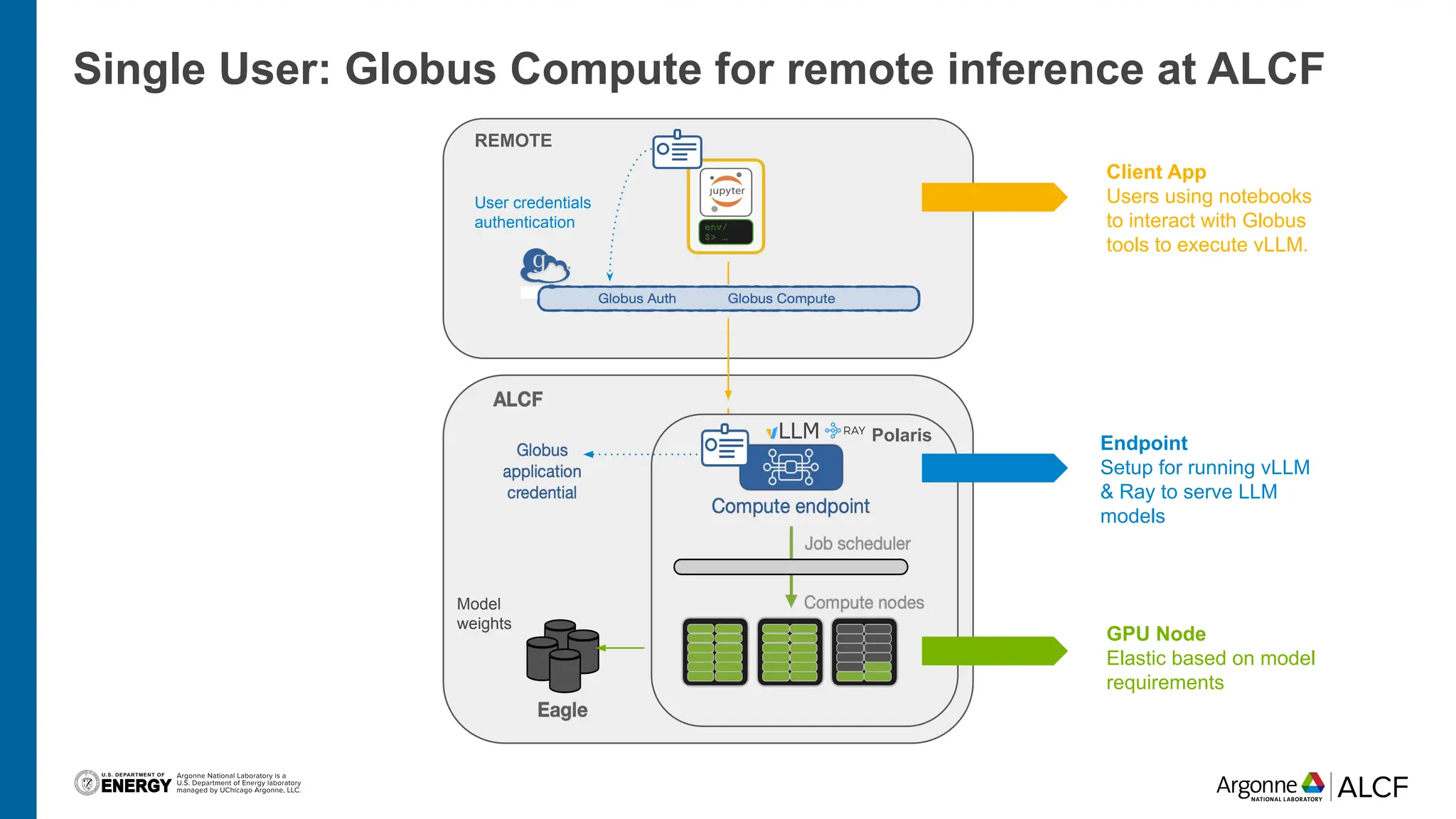
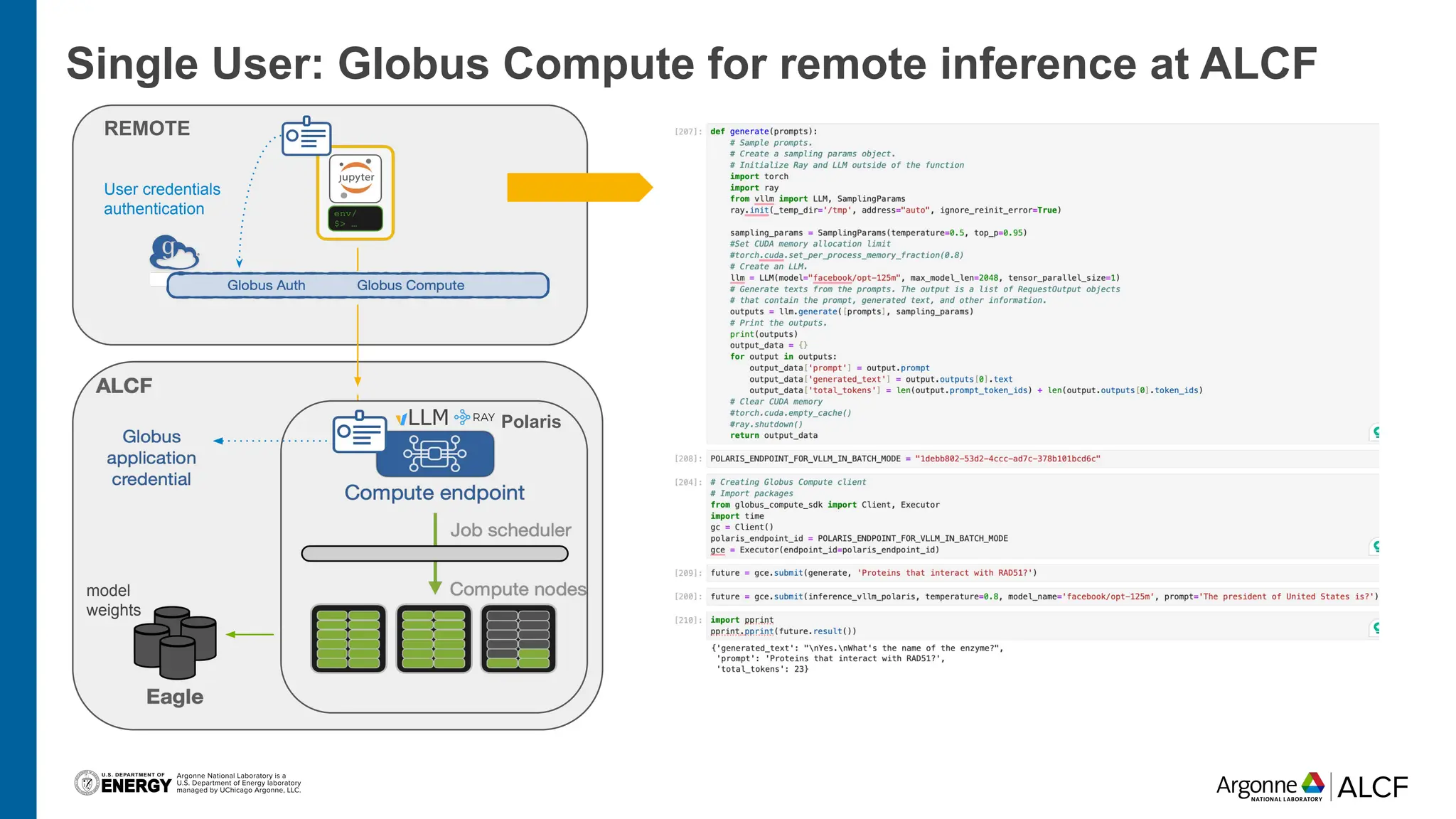
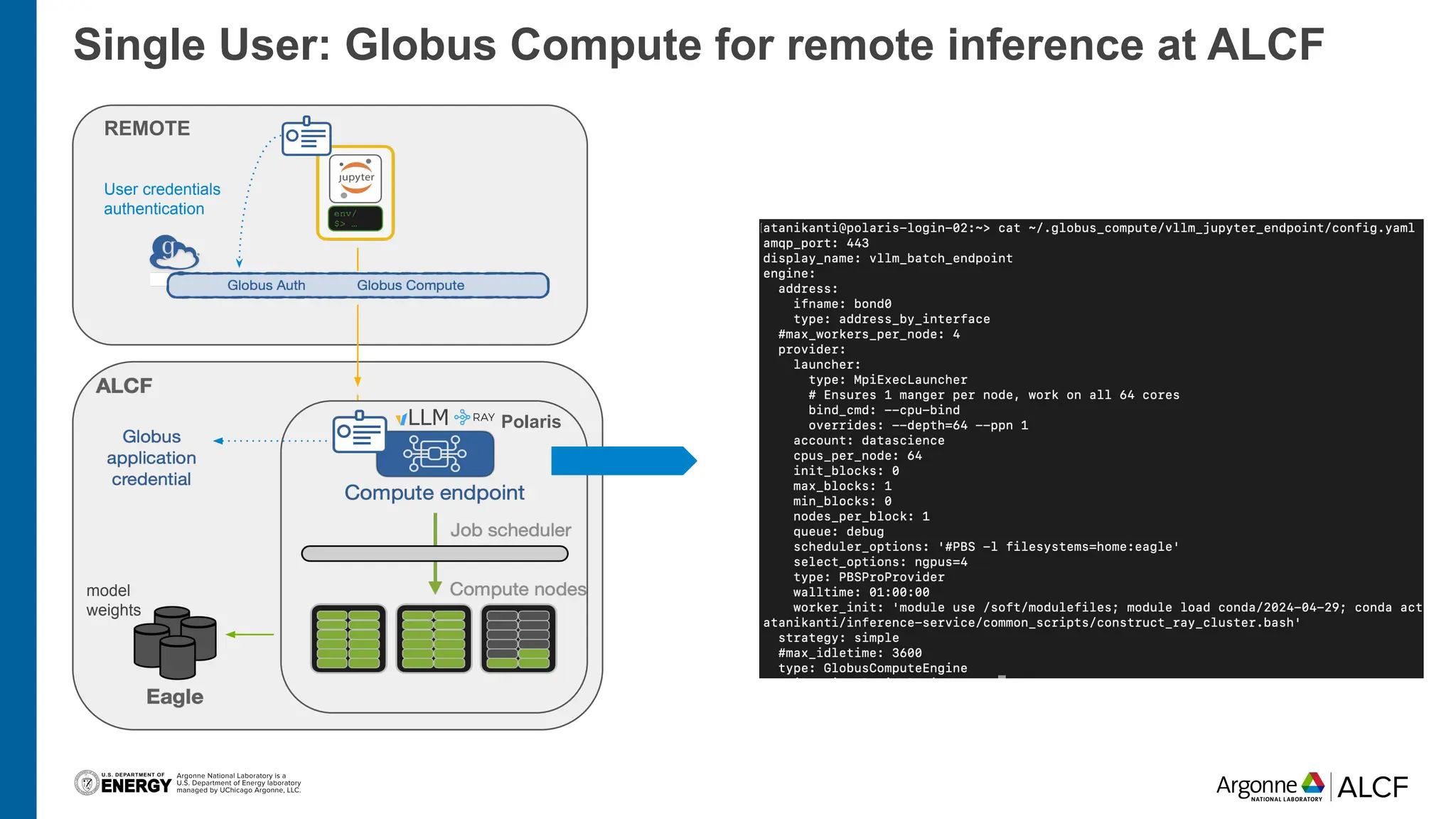
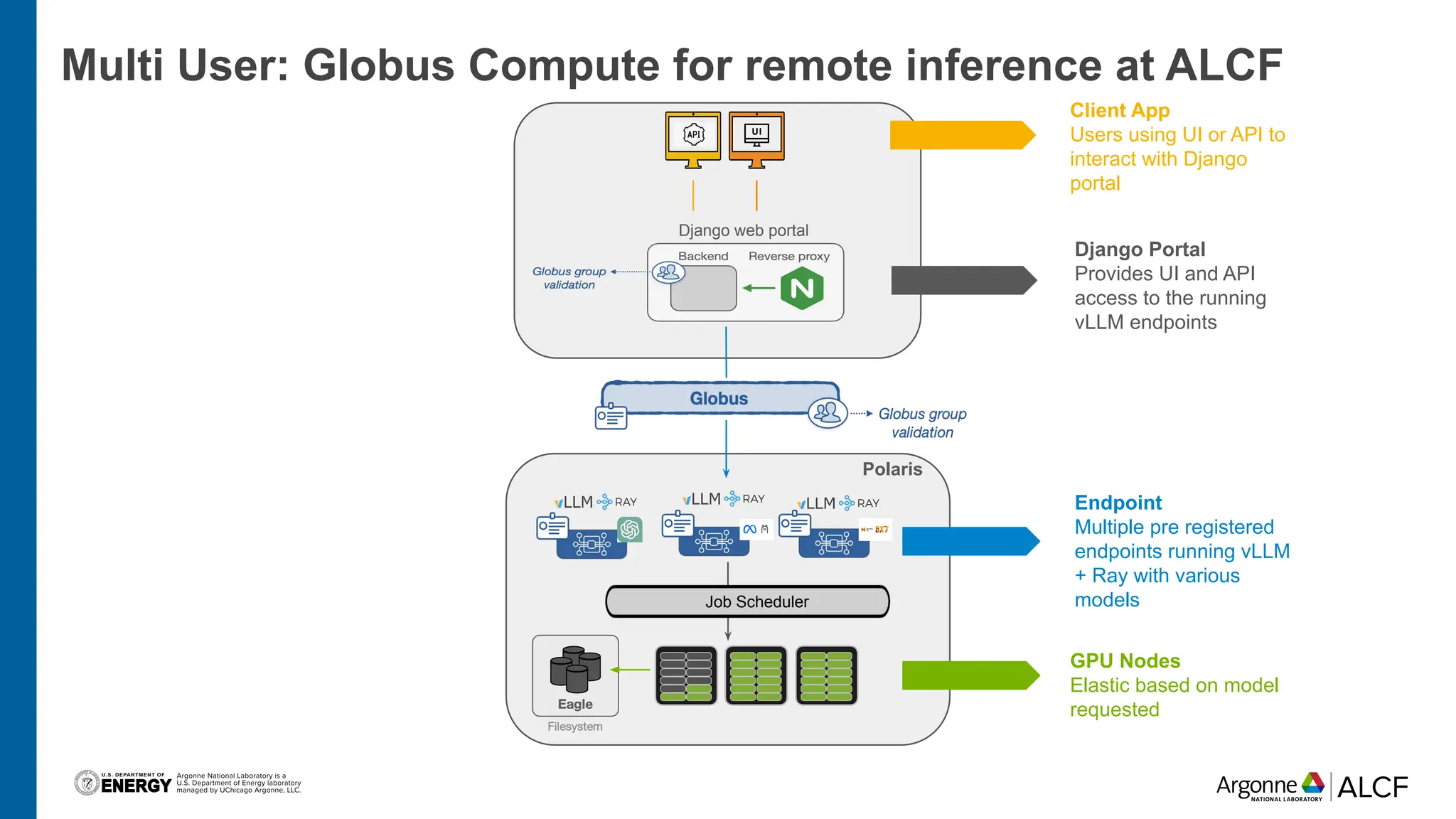

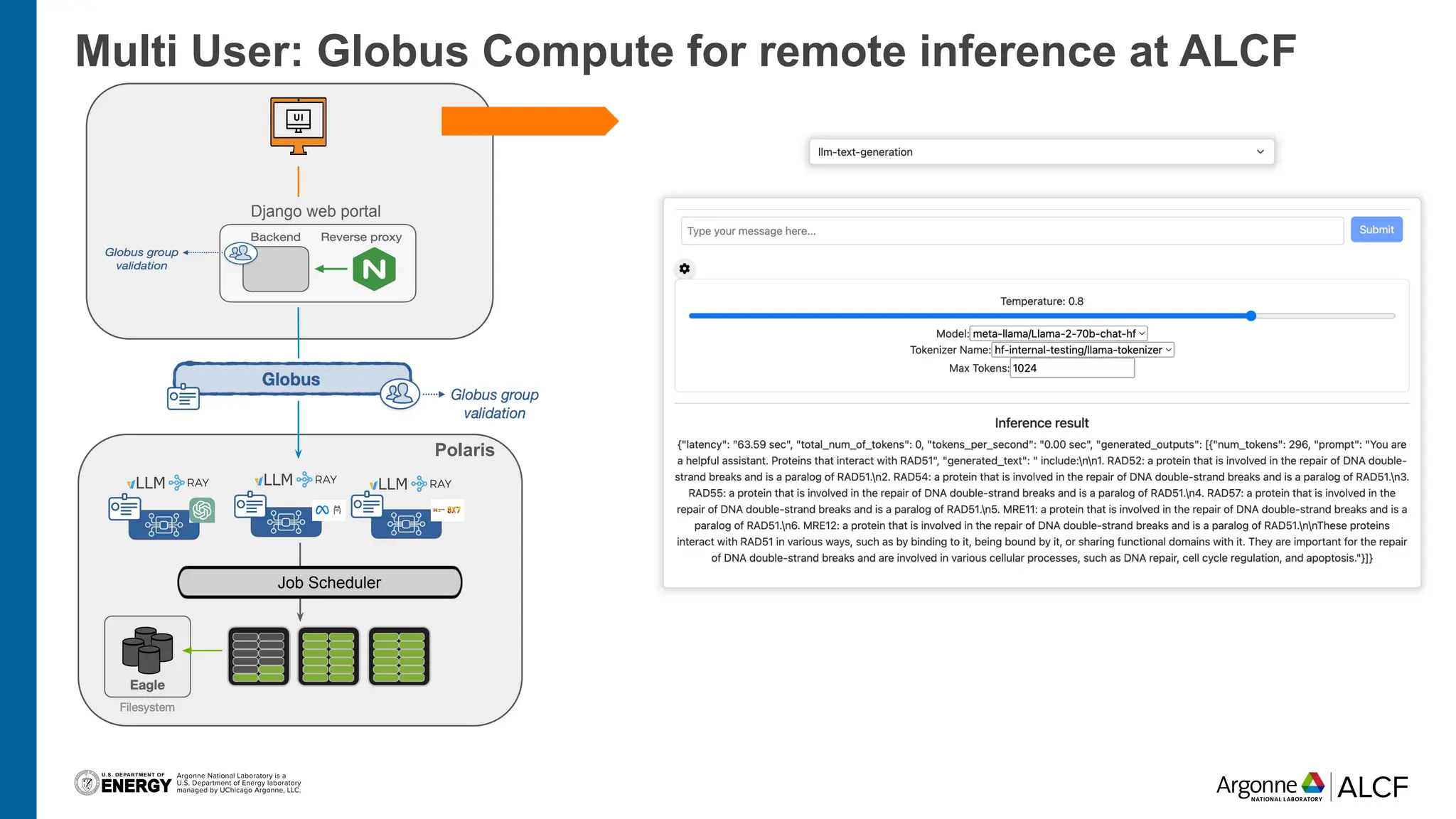


The document discusses advancements in large language model (LLM) inference using HPC clusters and Globus Compute, highlighting the potential for rapid molecular screening and high-performance predictions. It details the deployment of models via the VLLM library and various user approaches for accessing inference services on ALCF clusters. Ongoing efforts aim to enhance computational endpoints to facilitate model deployment from the Aurora AI testbed and inference clusters.



































































