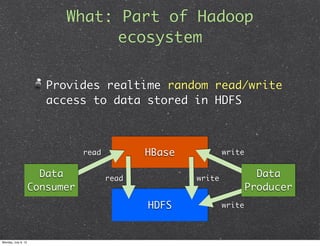
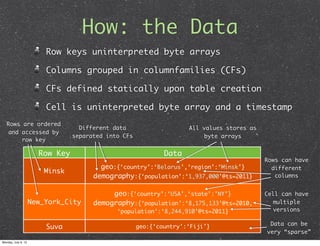
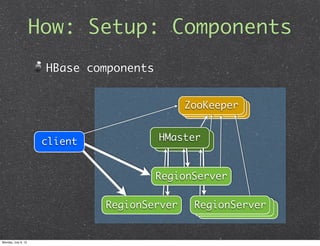
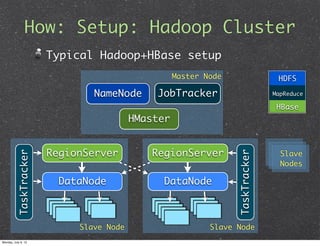
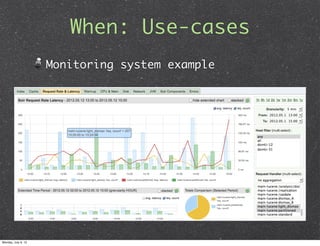
This document introduces HBase, an open-source, non-relational, distributed database modeled after Google's BigTable. It describes what HBase is, how it can be used, and when it is applicable. Key points include that HBase stores data in columns and rows accessed by row keys, integrates with Hadoop for MapReduce jobs, and is well-suited for large datasets, fast random access, and write-heavy applications. Common use cases involve log analytics, real-time analytics, and messages-centered systems.





















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



