Download to read offline















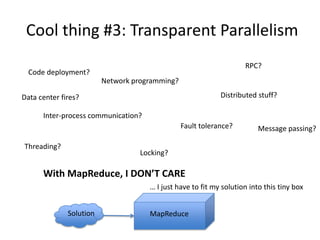






Hadoop is an open source distributed processing platform for large data sets across clusters of commodity hardware. It allows for the distributed processing of large data sets across clusters of computers using simple programming models. Hadoop features include a distributed file system (HDFS), a MapReduce programming model for large scale data processing, and an ecosystem of projects including HBase, Pig, Hive, and ZooKeeper. Hadoop is well suited for batch processing large amounts of structured and unstructured data, providing scalability and fault tolerance. However, it is not as suitable for low latency queries or updating existing data.











































































