Download to read offline




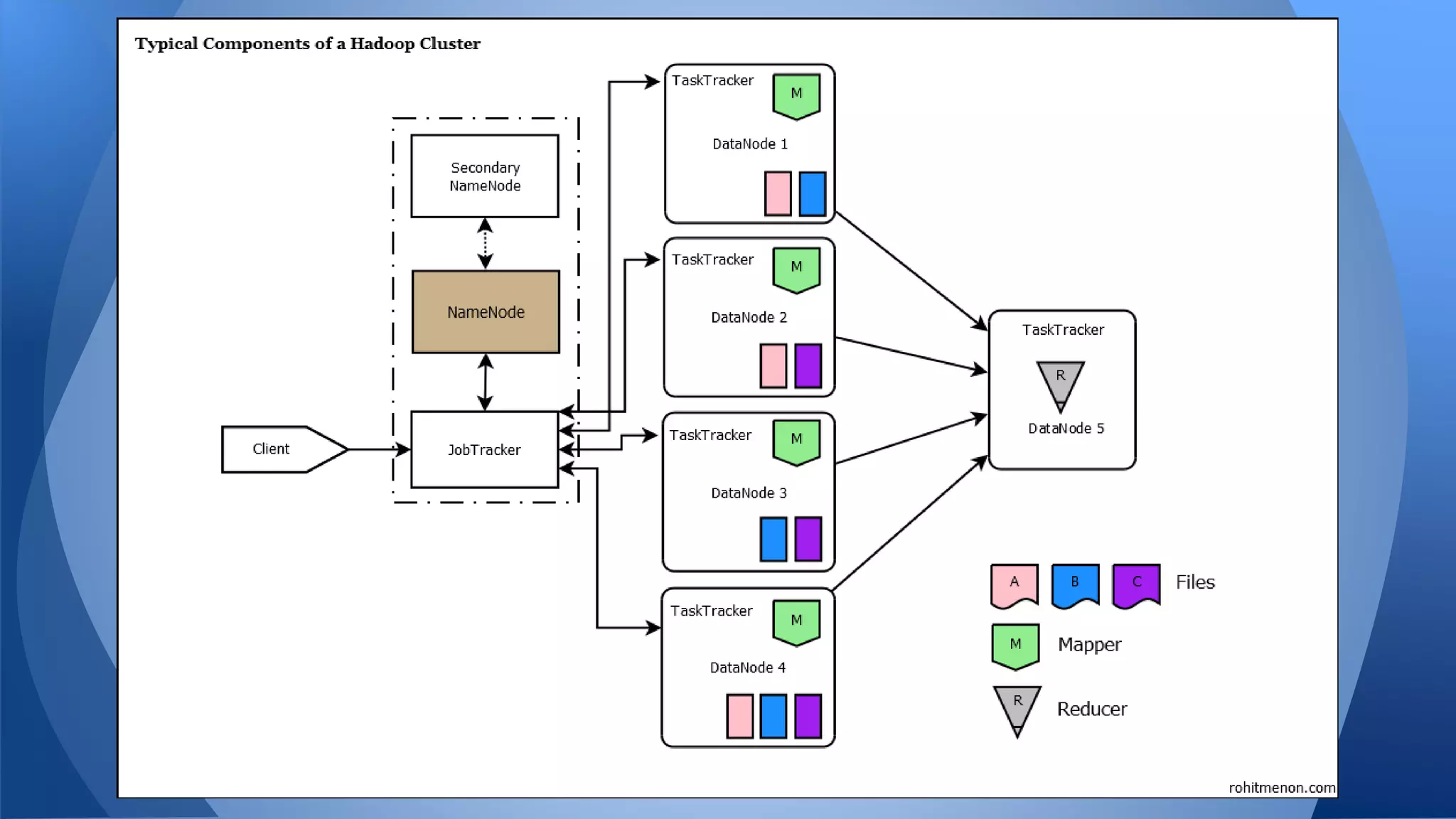









Hadoop is an open-source distributed processing framework created by Doug Cutting in 2005 at Yahoo. It allows for the distributed processing of large datasets across clusters of computers using simple programming models. Hadoop addresses problems of velocity, volume and variety of big data by distributing storage and processing across clusters of low-cost commodity hardware. It provides reliable storage and processing of large datasets through its Hadoop Distributed File System and MapReduce programming model.




















































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)













