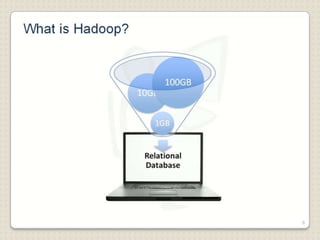
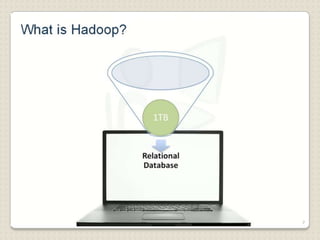
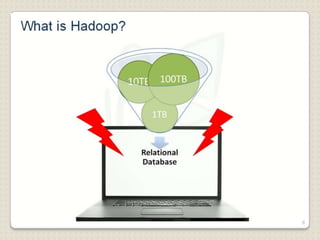
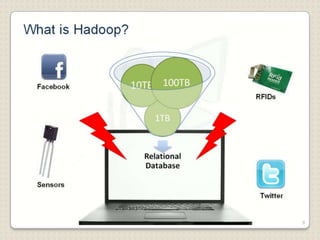
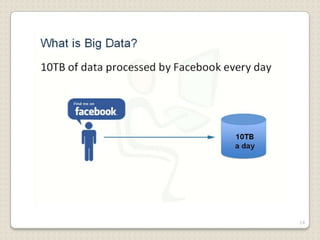
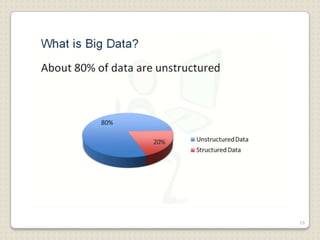
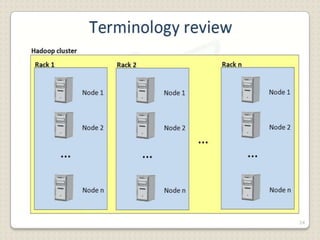
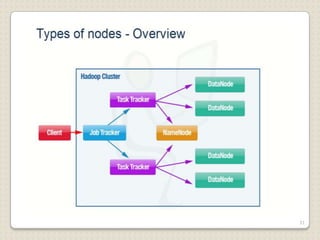
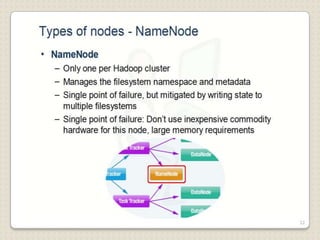
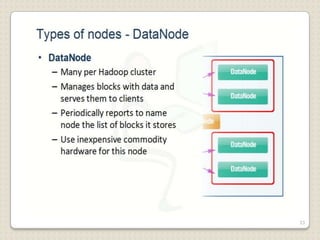
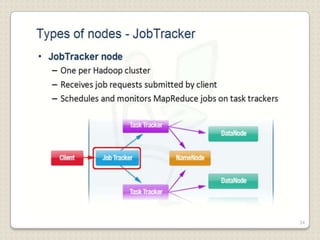
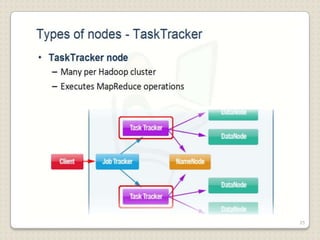
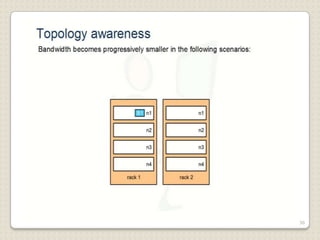
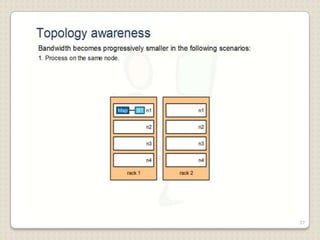
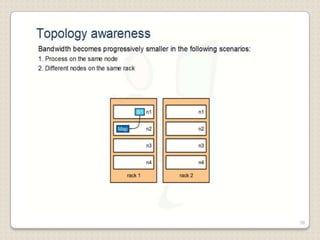
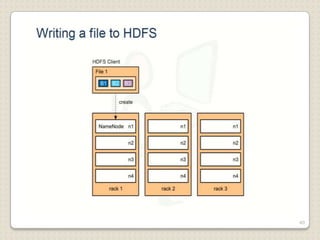
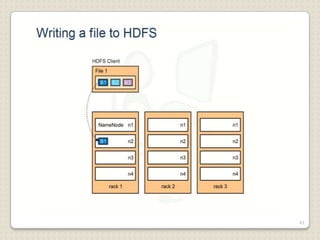
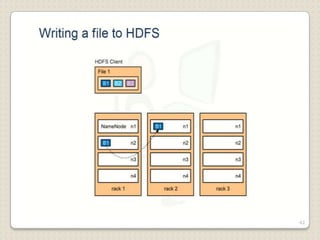
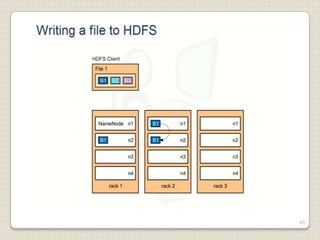
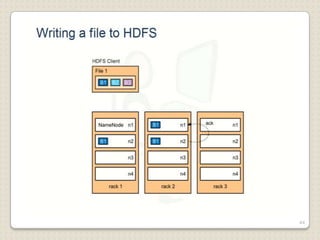
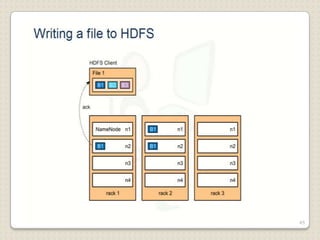
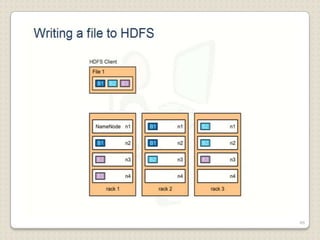
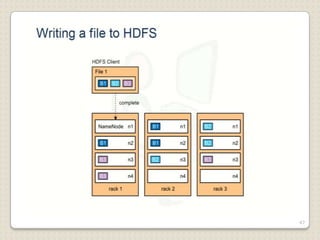
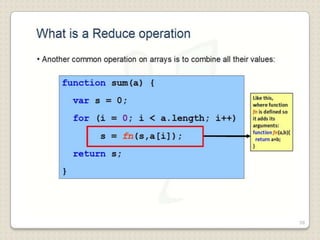
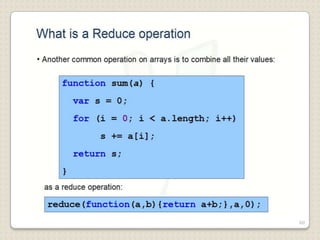
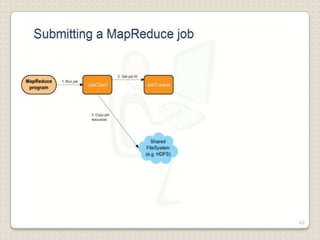
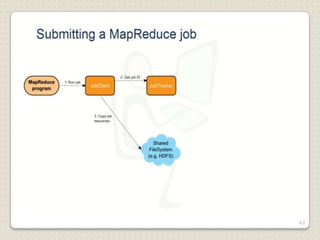
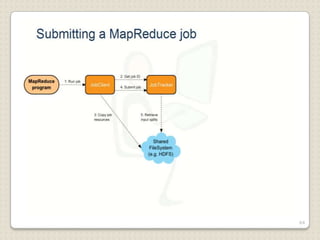
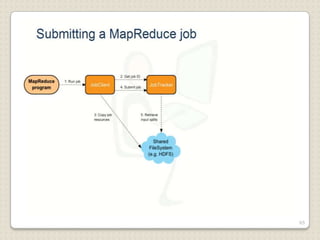
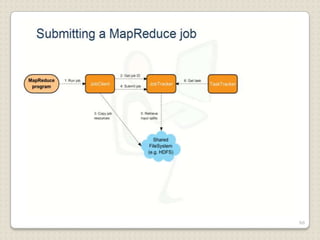
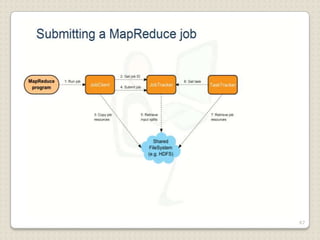
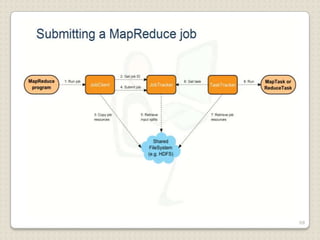
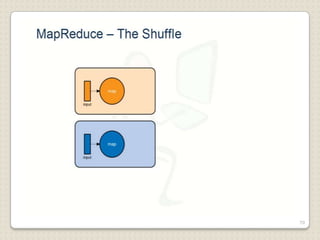
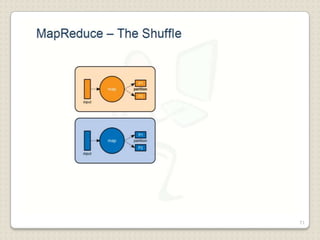
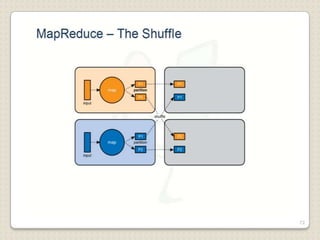
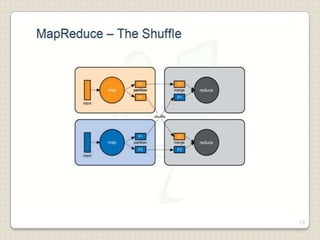
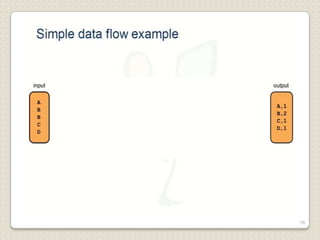
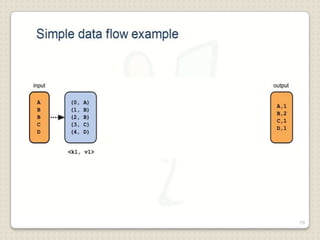
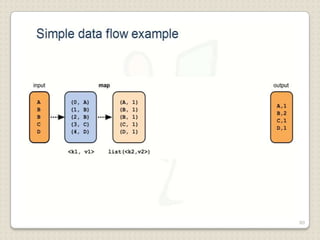
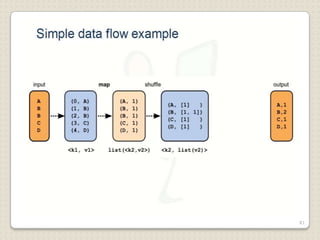
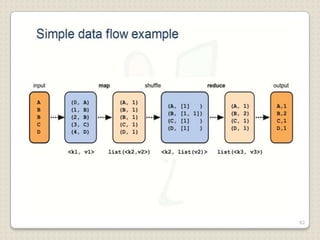
Hadoop is a framework designed for running applications on large clusters of commodity hardware, utilizing a computational model called map/reduce and a distributed file system (HDFS) for reliable data processing. It addresses the challenges posed by the explosive growth of digital data and the slower relative access speeds of storage devices by enabling parallel processing across multiple nodes. The combination of Hadoop and cloud computing facilitates the scalable and cost-effective management of data-intensive applications.