Downloaded 231 times










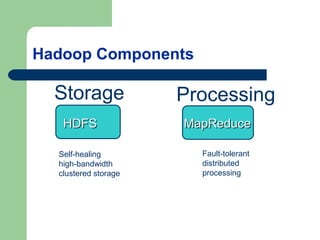
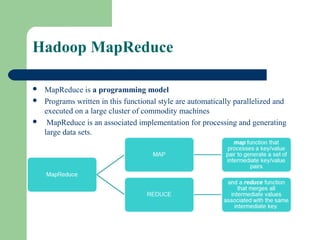
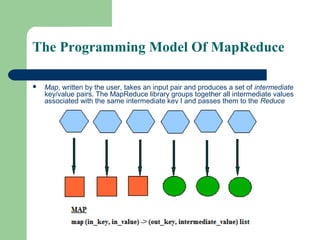




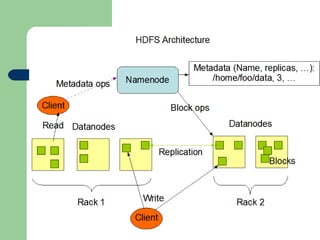





This document provides an overview of Big Data and Hadoop. It defines Big Data as large volumes of structured, semi-structured, and unstructured data that is too large to process using traditional databases and software. It provides examples of the large amounts of data generated daily by organizations. Hadoop is presented as a framework for distributed storage and processing of large datasets across clusters of commodity hardware. Key components of Hadoop including HDFS for distributed storage and fault tolerance, and MapReduce for distributed processing, are described at a high level. Common use cases for Hadoop by large companies are also mentioned.











































































