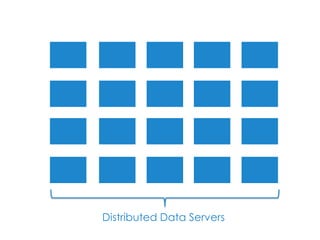
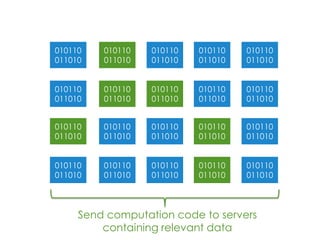
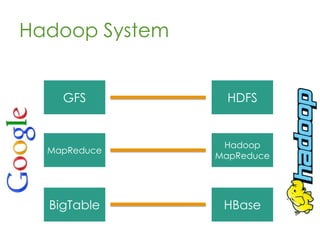
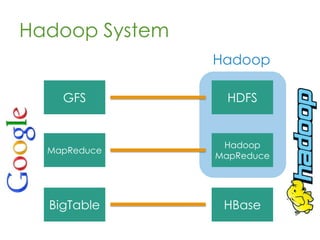
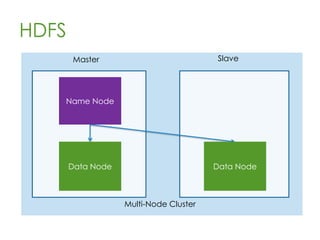
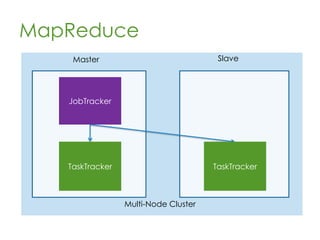
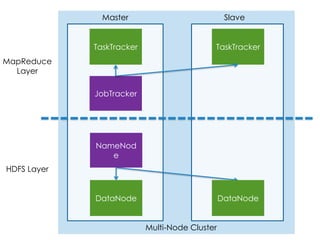
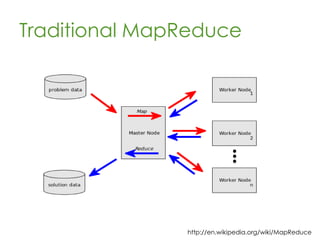
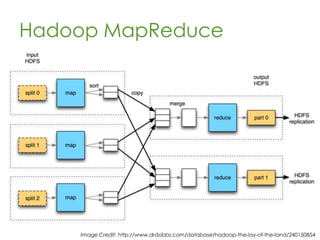
This document provides an overview of Apache Hadoop, a framework for distributed storage and processing of very large datasets across clusters of commodity hardware. It discusses how Hadoop addresses challenges of large-scale computation by distributing data across nodes and moving computation to the data. The key components of Hadoop are HDFS for distributed file storage, MapReduce for distributed processing, and HBase for distributed database access. Hadoop allows scaling to very large datasets using inexpensive, commodity hardware.











![The internet
IDC estimates[2] the internet contains at
least:
1 Zetabyte
or
1,000 Exabytes
or
1,000,000 Petabytes
2 http://www.emc.com/collateral/analyst-reports/expanding-digital-idc-white-paper.pdf (2007)](https://image.slidesharecdn.com/hadoop-130425152359-phpapp02/85/Hadoop-The-elephant-in-the-room-13-320.jpg)