Downloaded 24 times





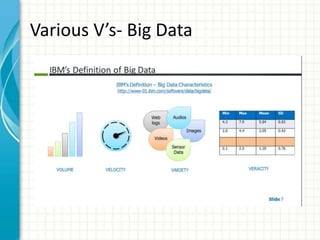




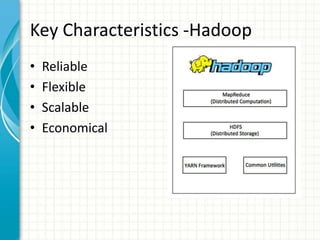

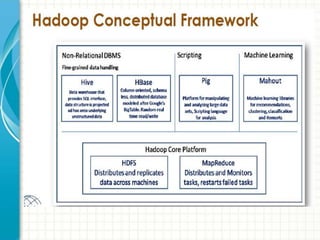
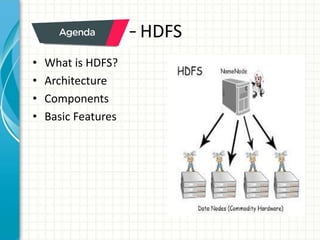





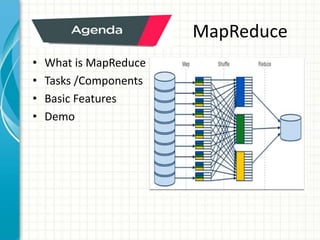





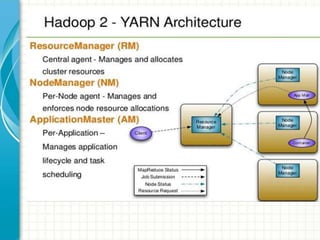
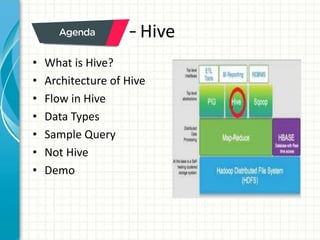



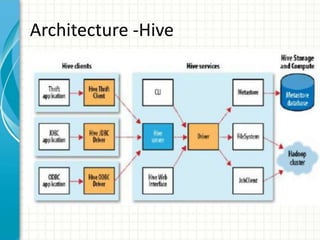














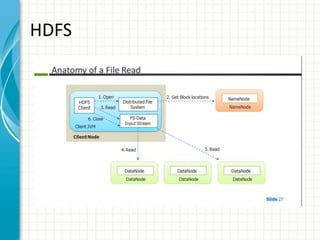








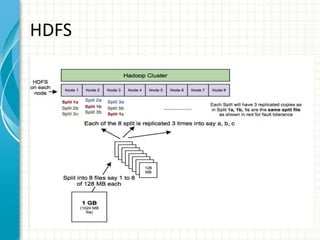


















The document provides an overview of big data and Hadoop fundamentals. It discusses what big data is, the characteristics of big data, and how it differs from traditional data processing approaches. It then describes the key components of Hadoop including HDFS for distributed storage, MapReduce for distributed processing, and YARN for resource management. HDFS architecture and features are explained in more detail. MapReduce tasks, stages, and an example word count job are also covered. The document concludes with a discussion of Hive, including its use as a data warehouse infrastructure on Hadoop and its query language HiveQL.














































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







