Downloaded 11 times




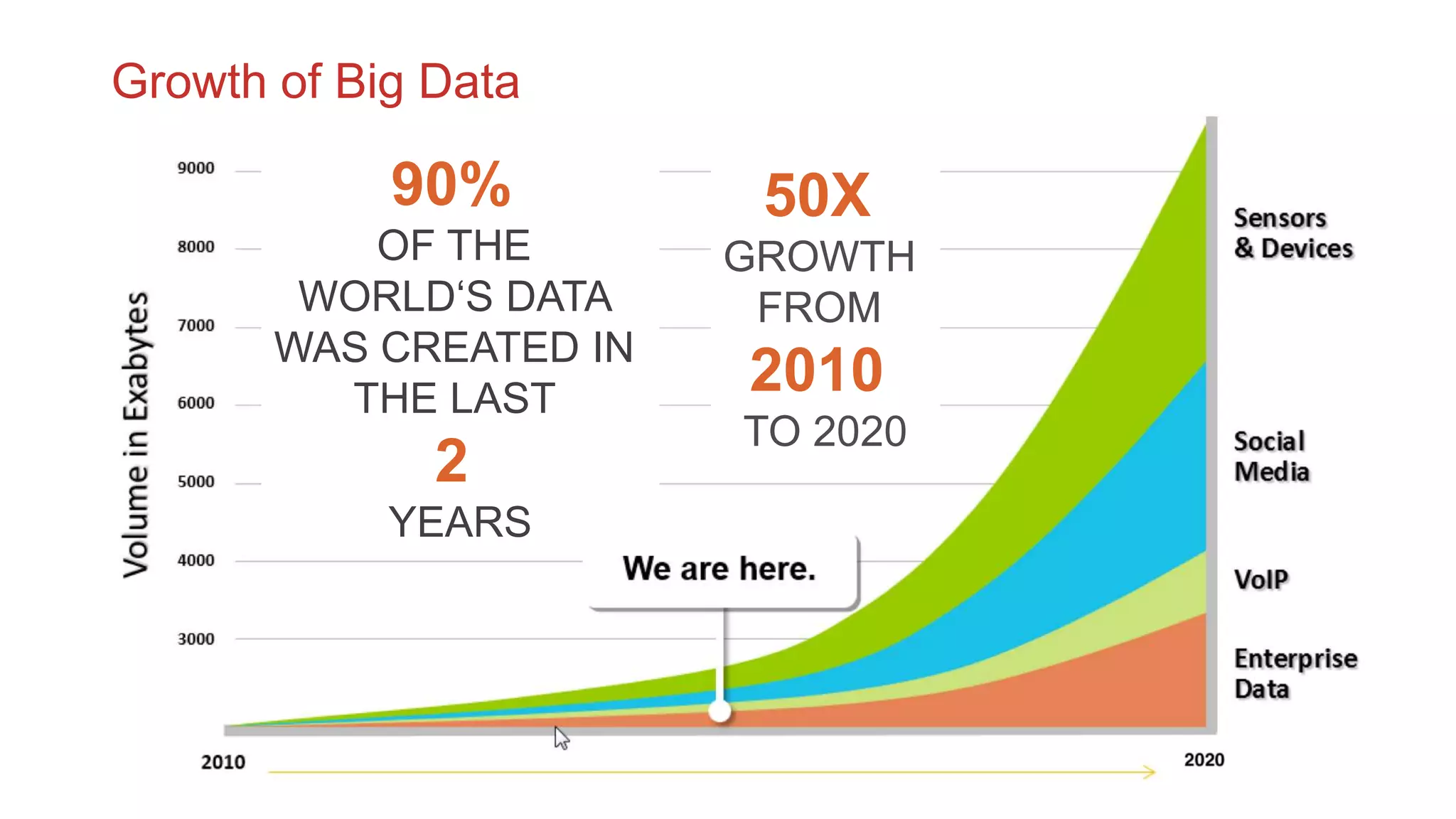

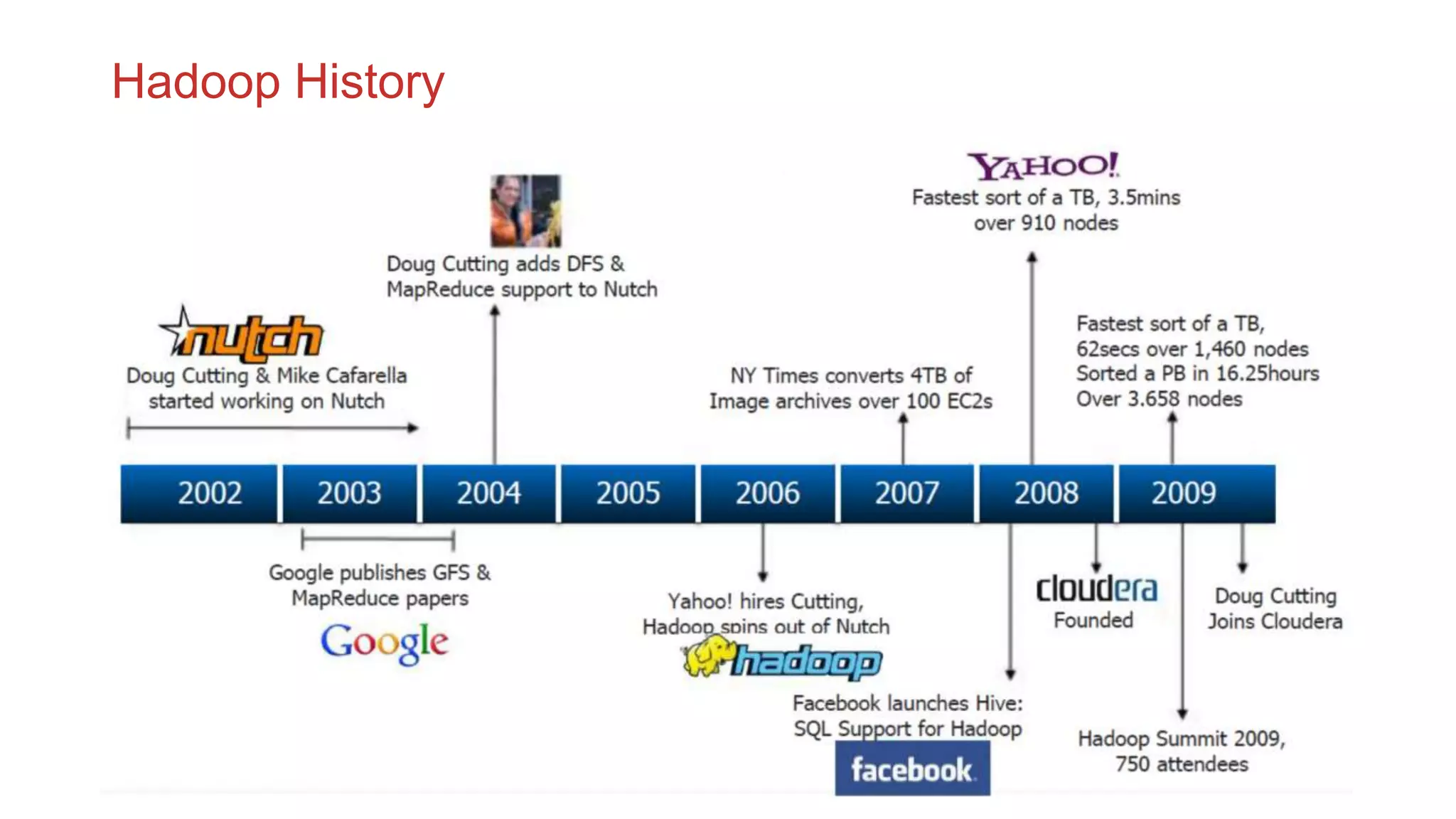


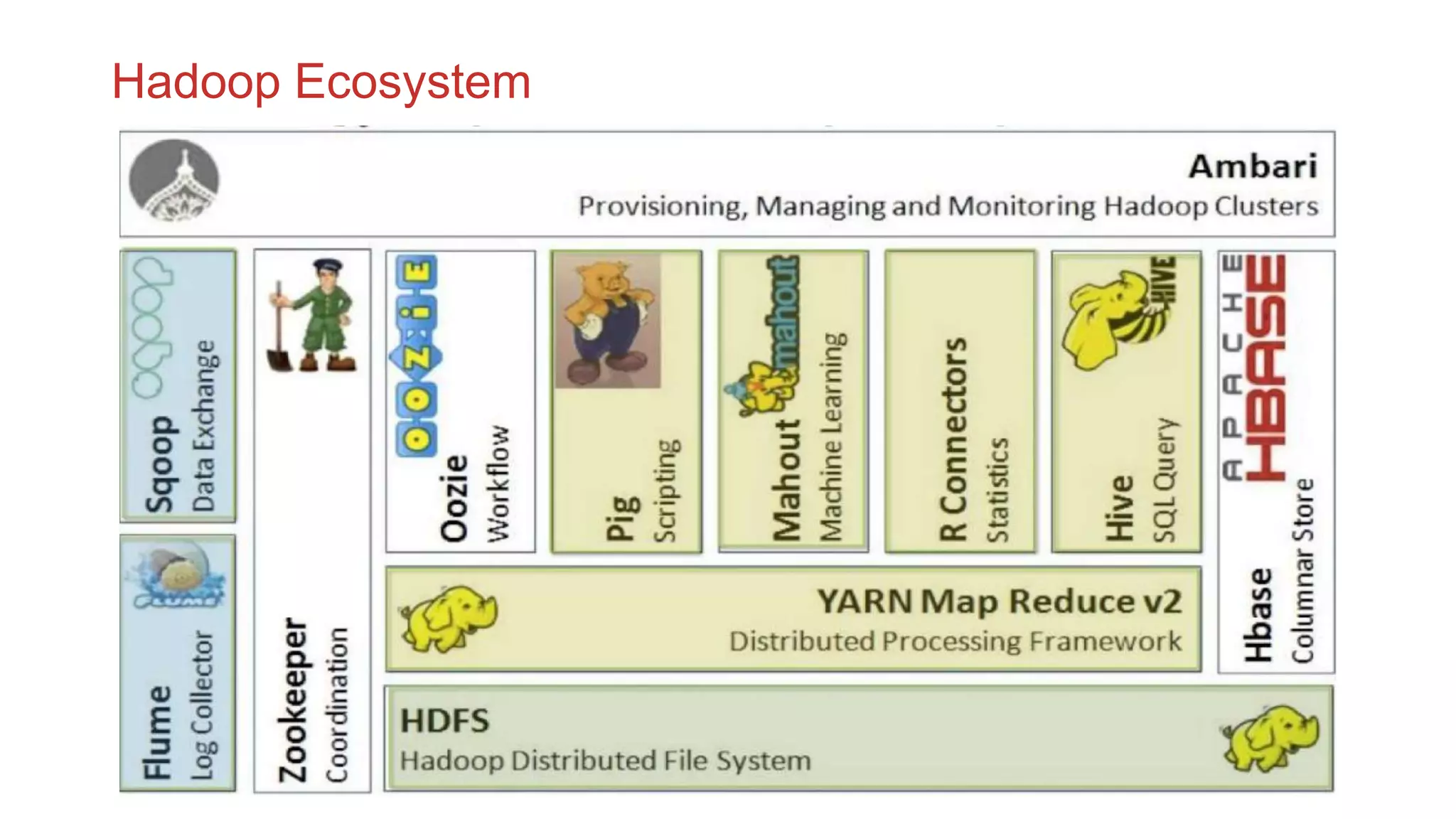




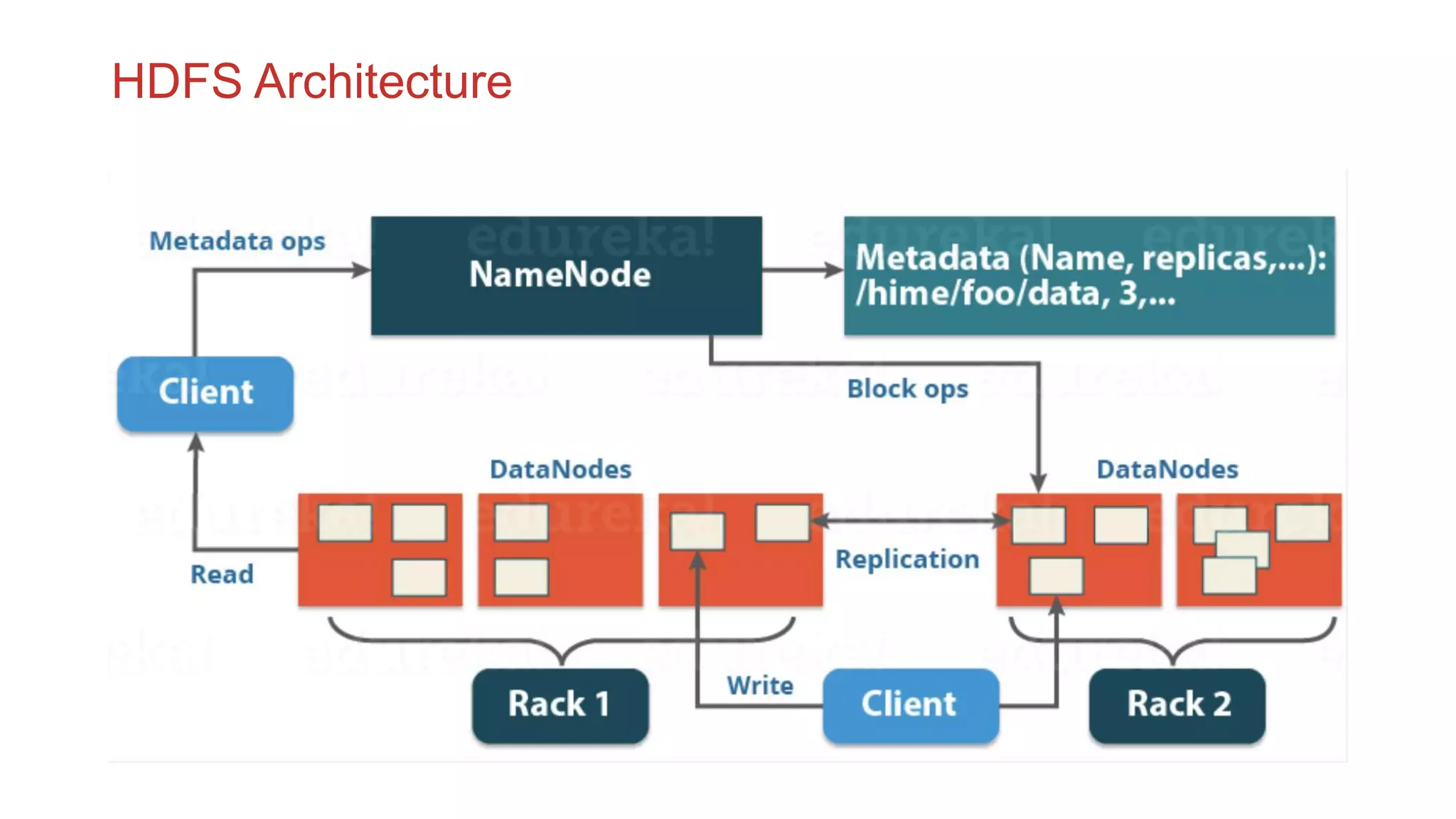
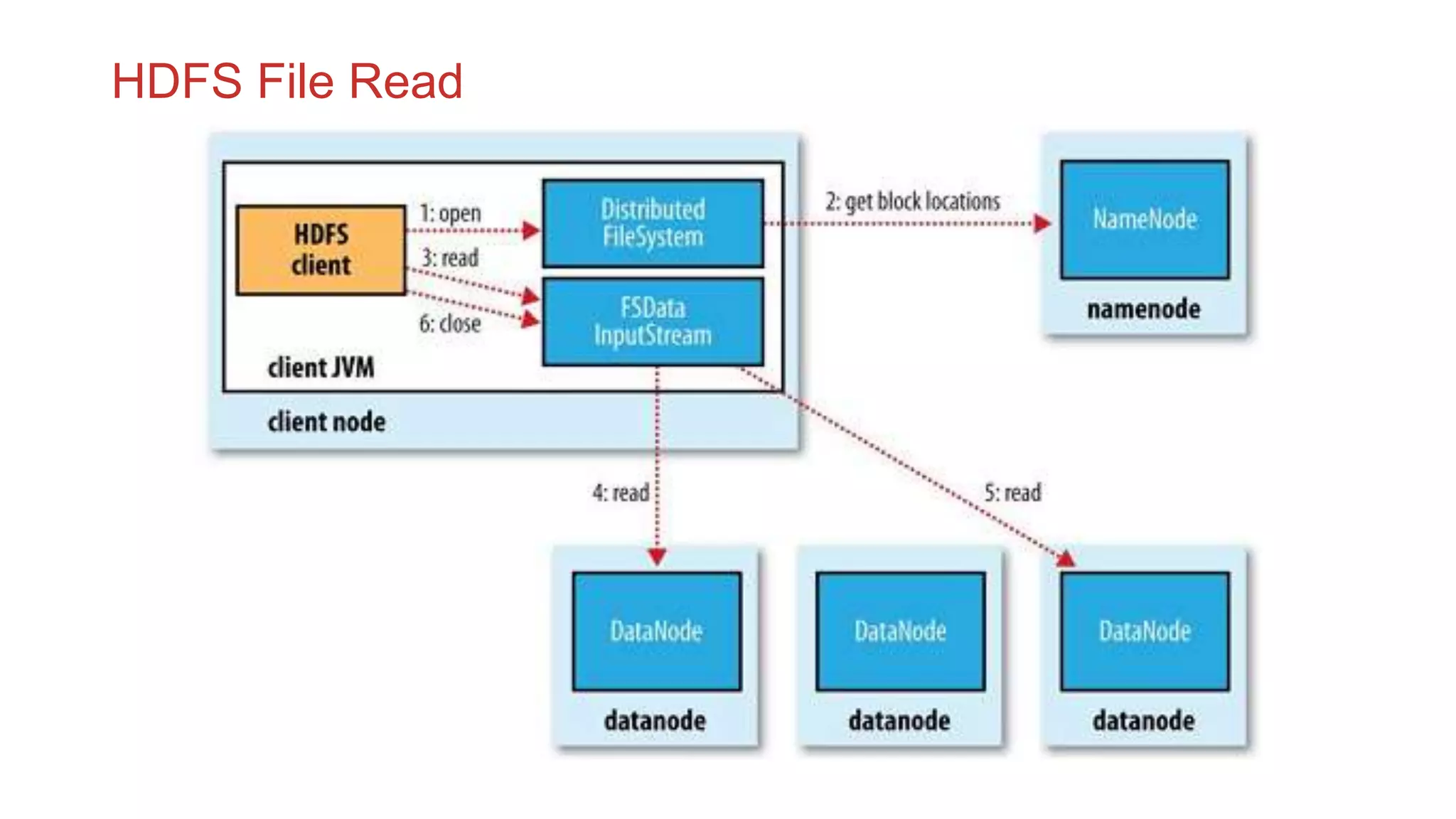
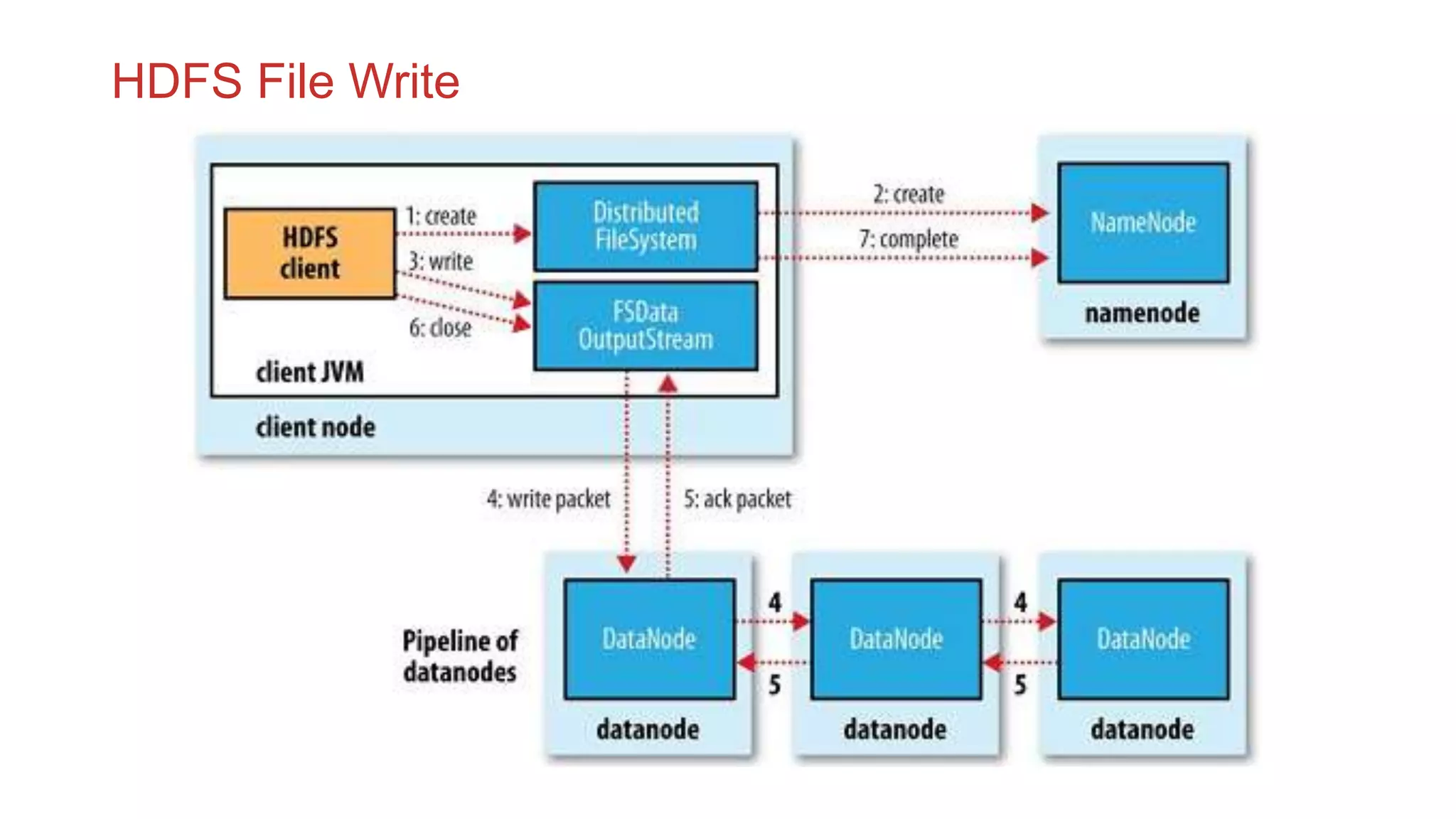
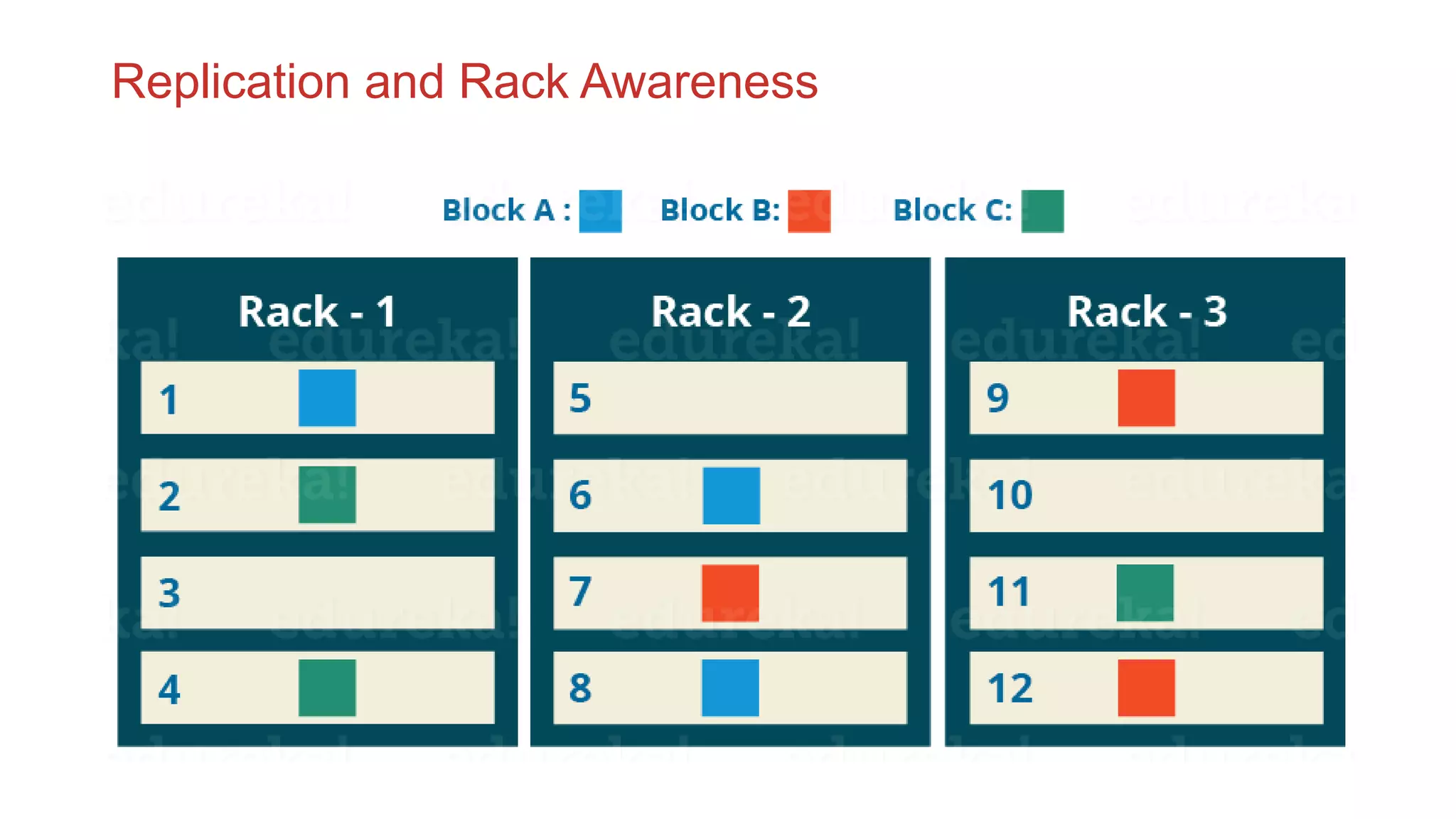




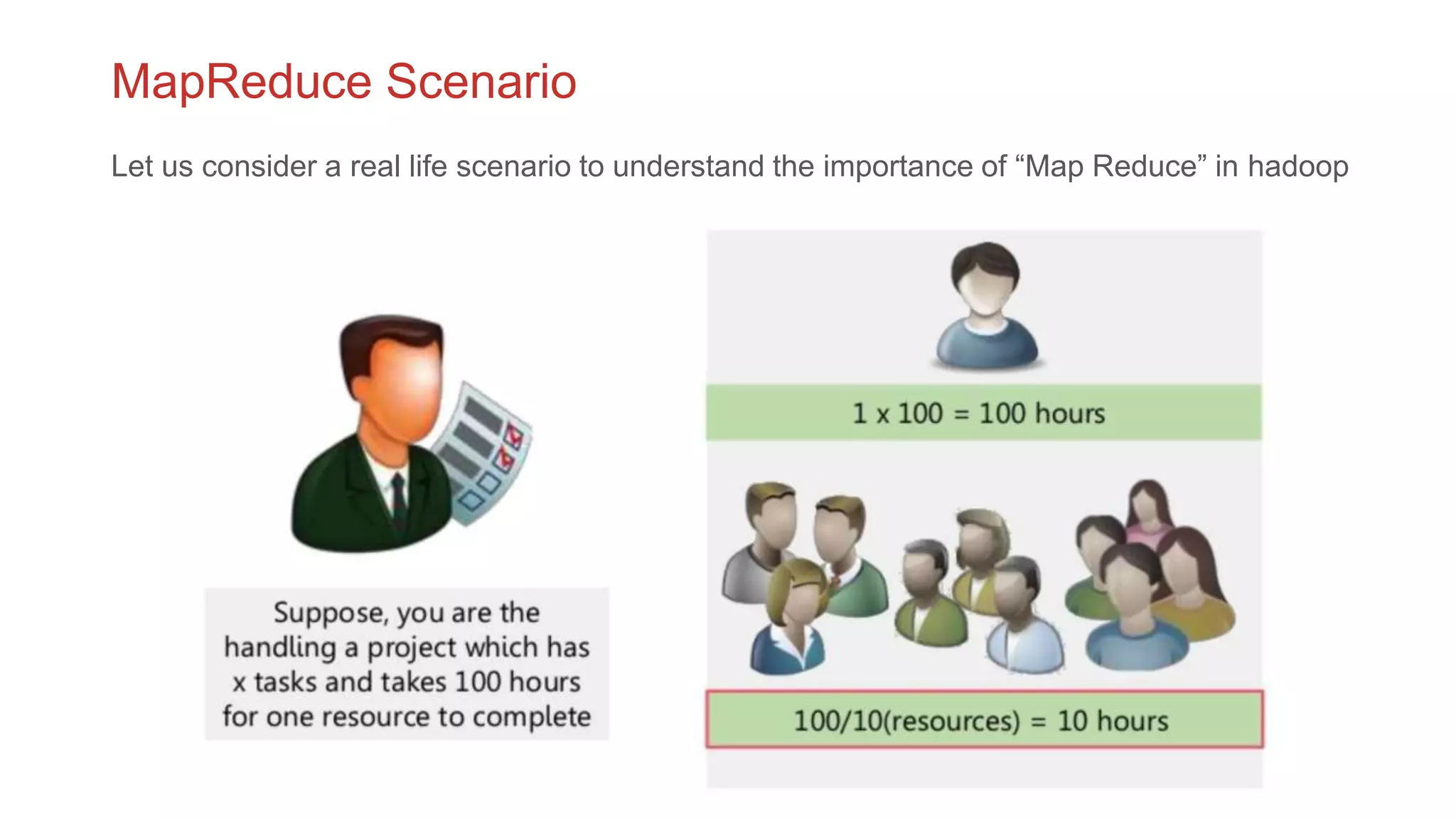
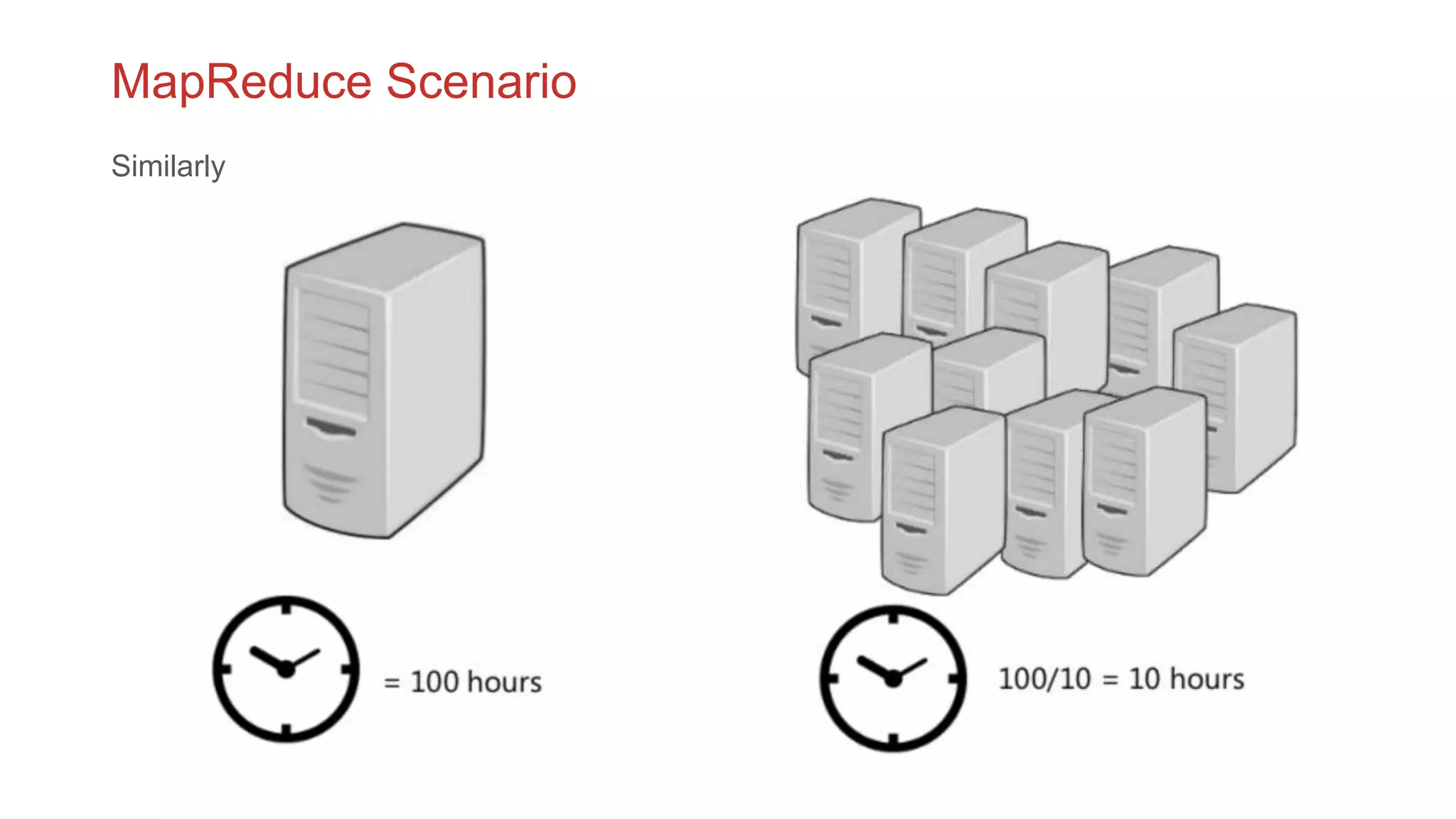

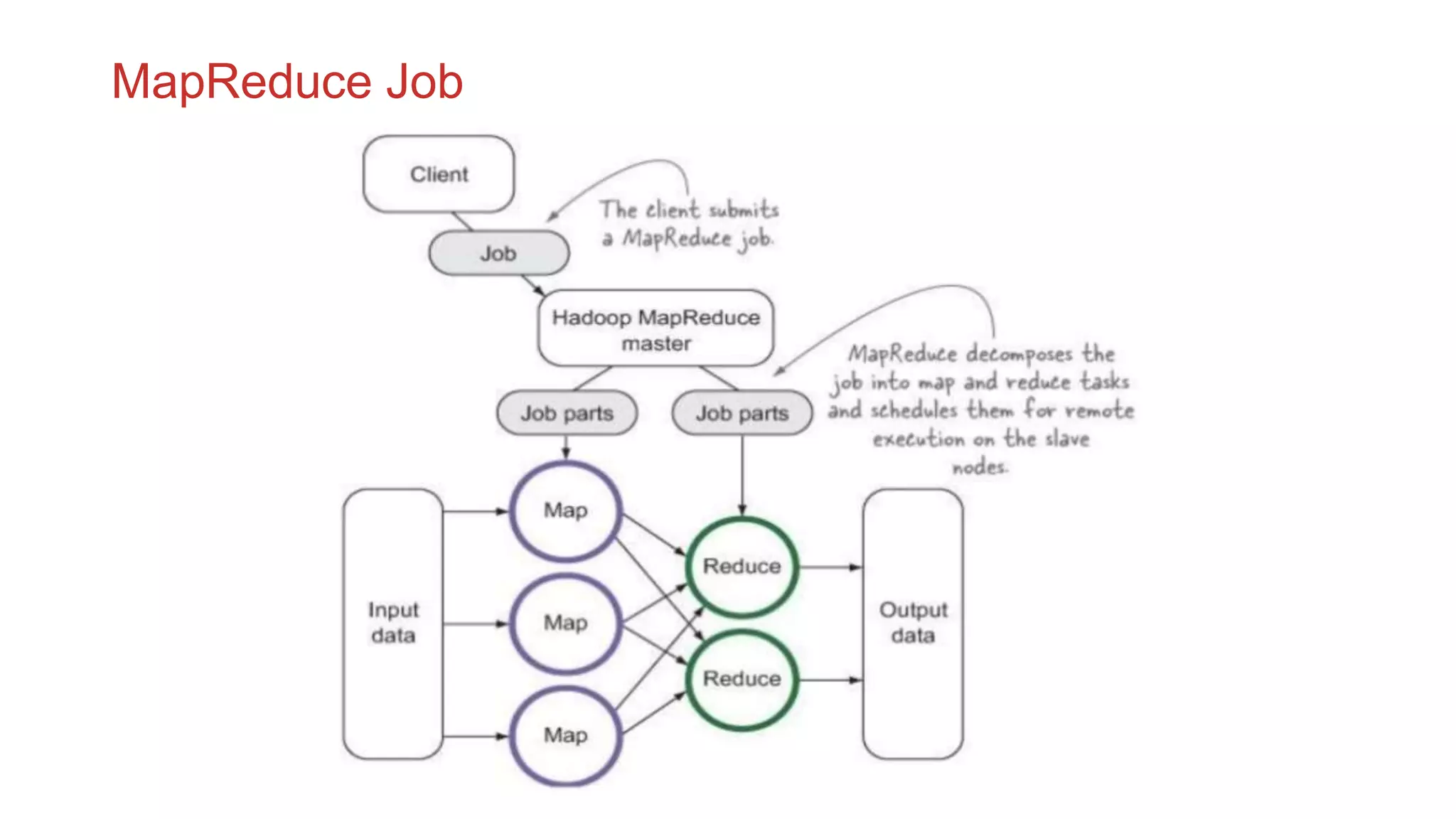

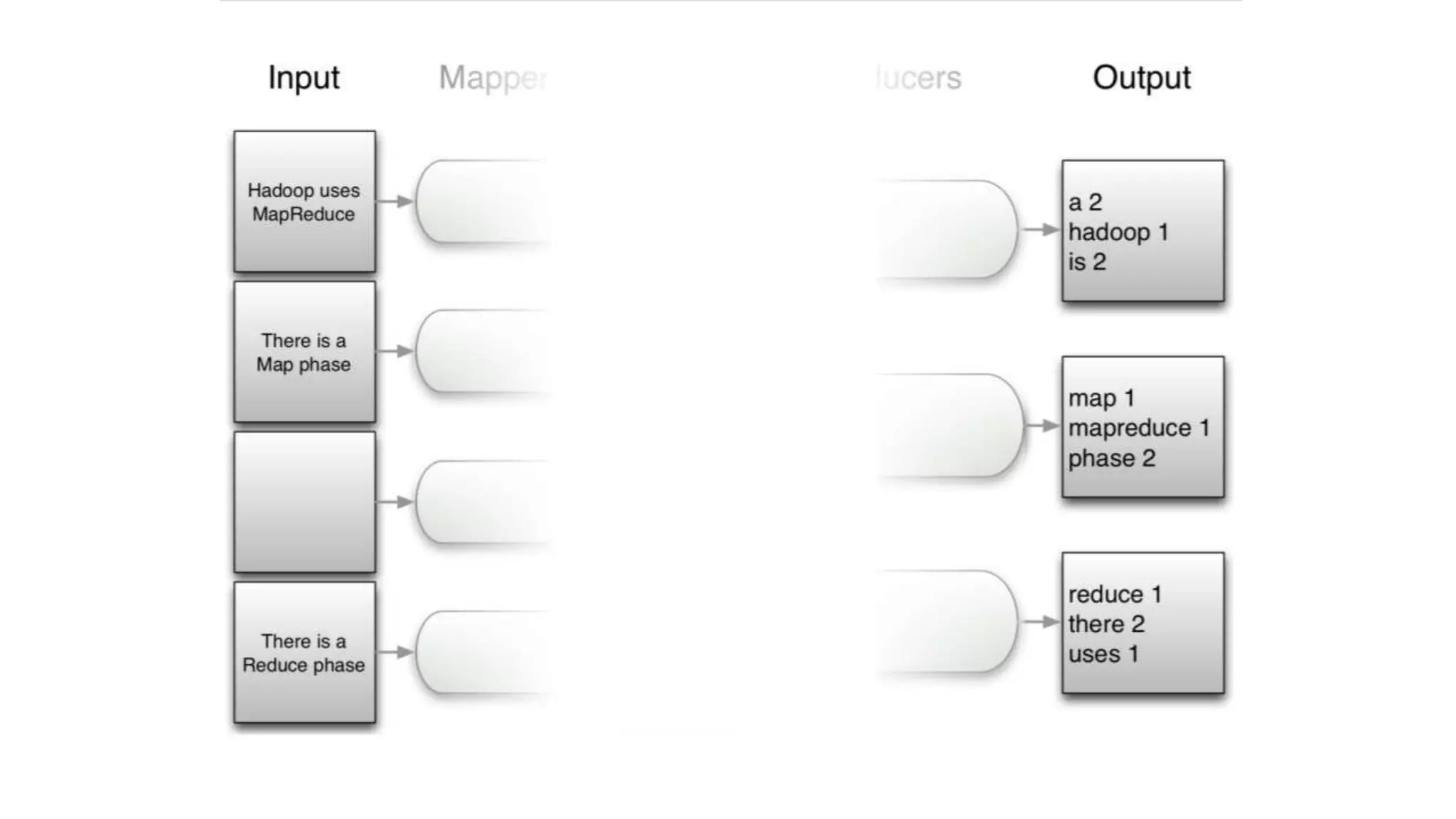
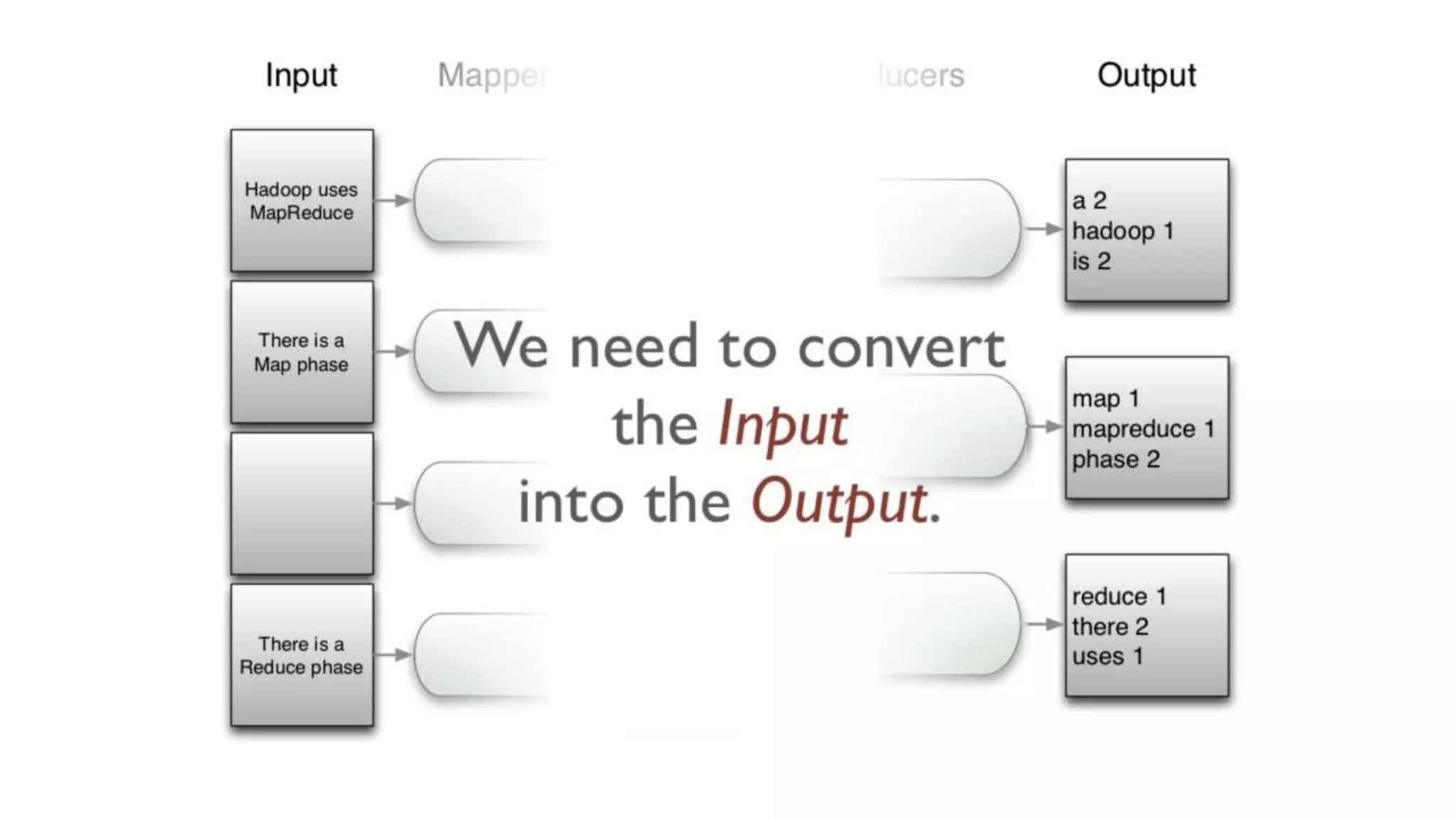
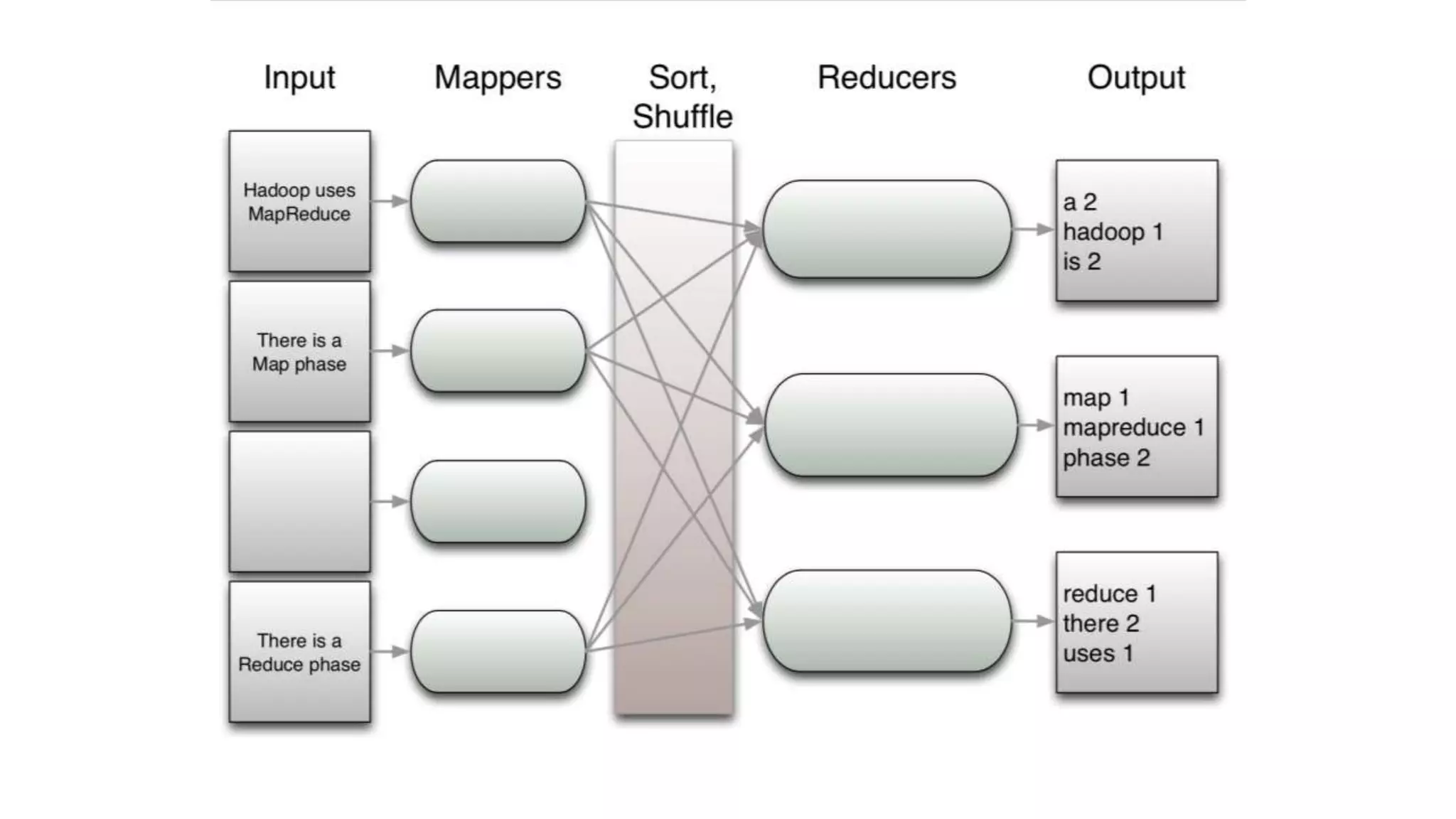
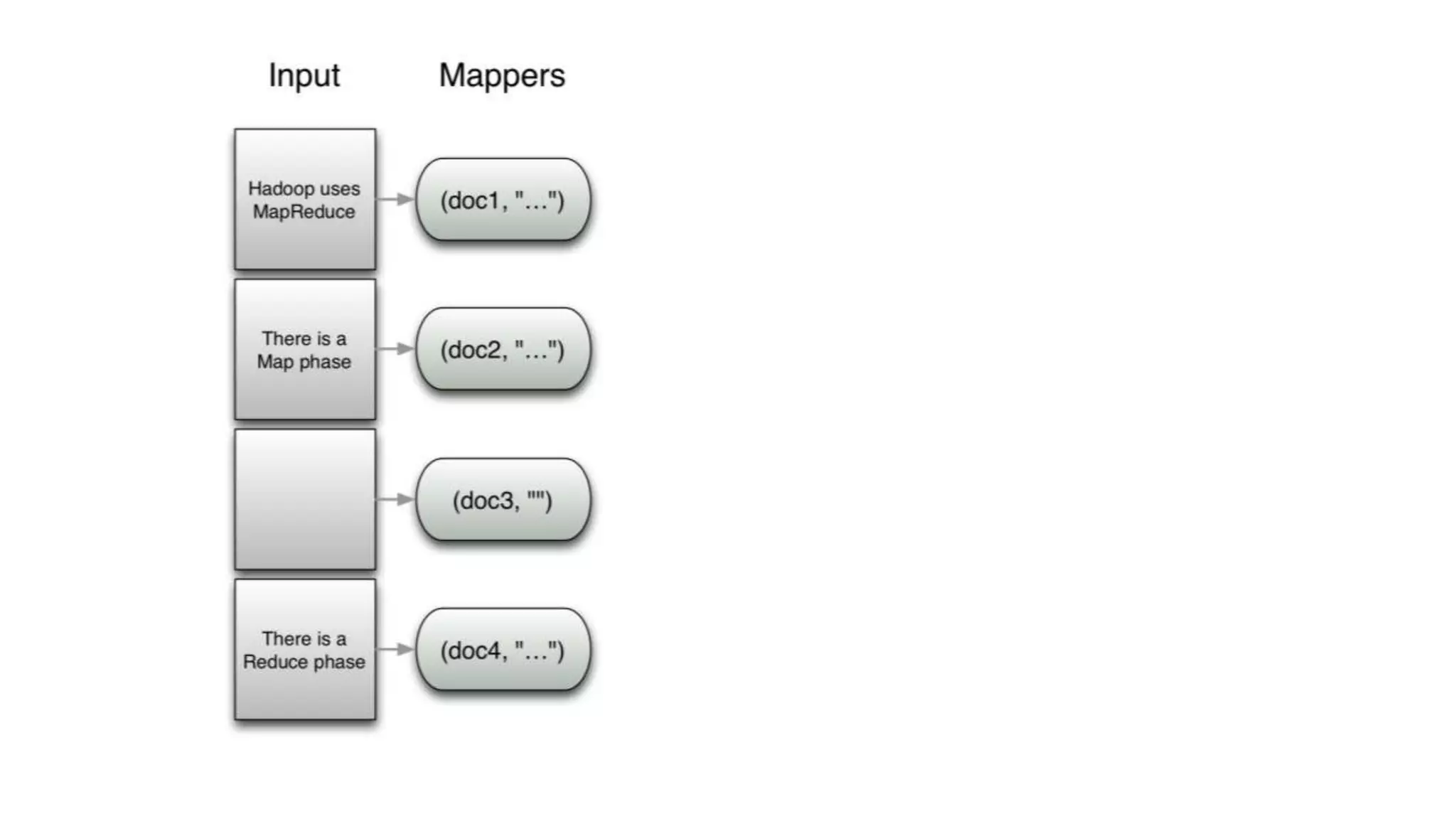
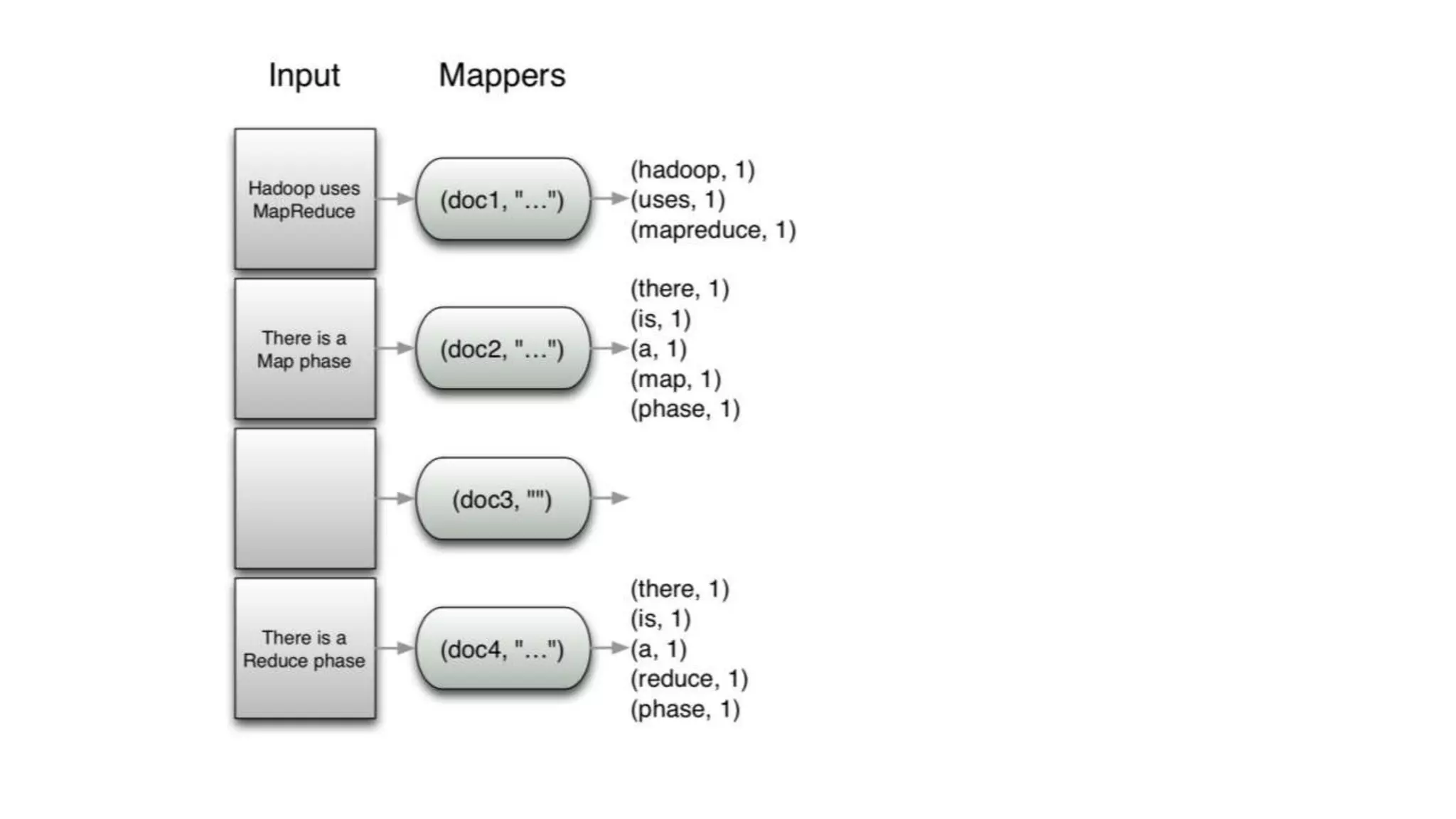
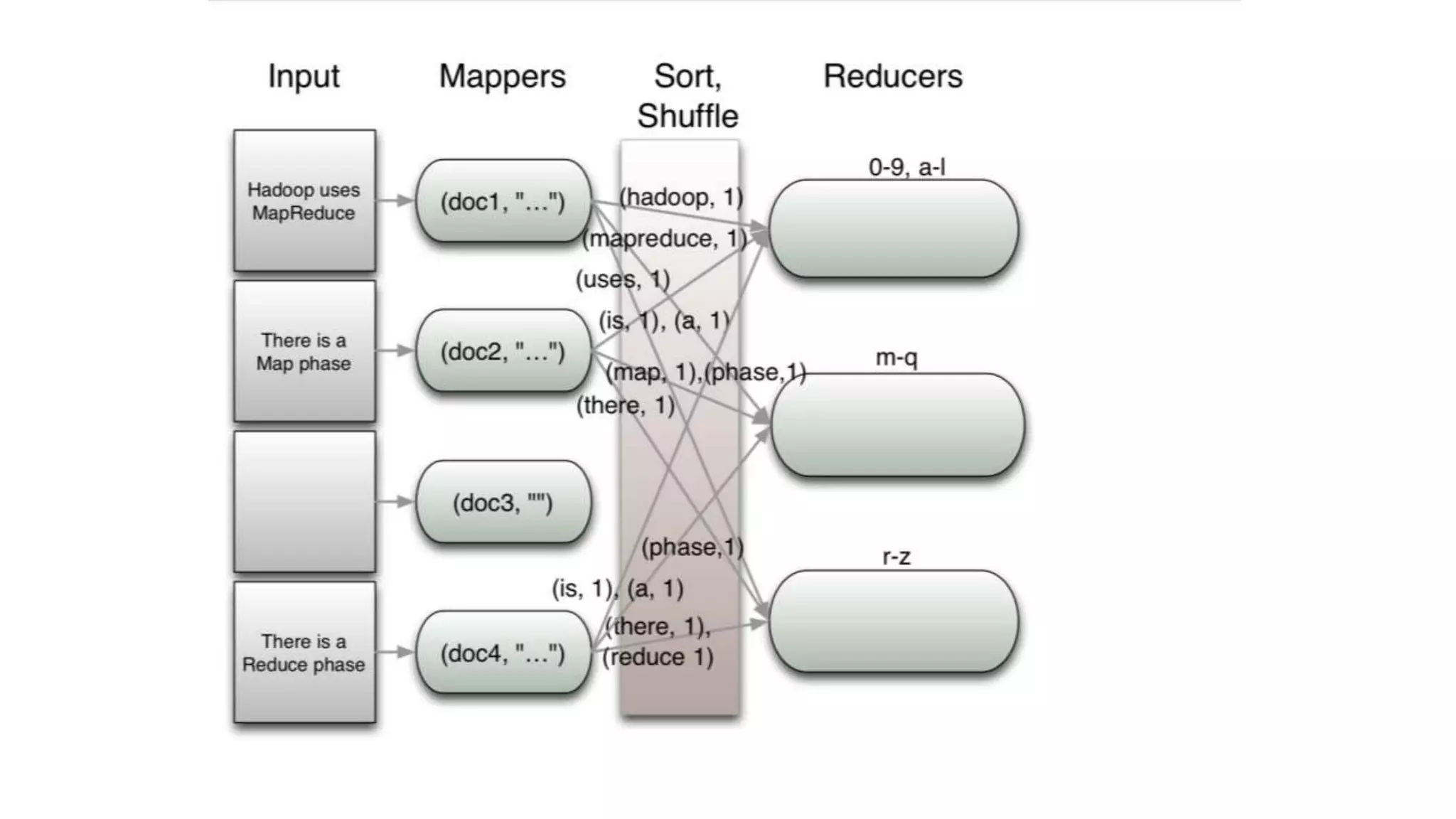
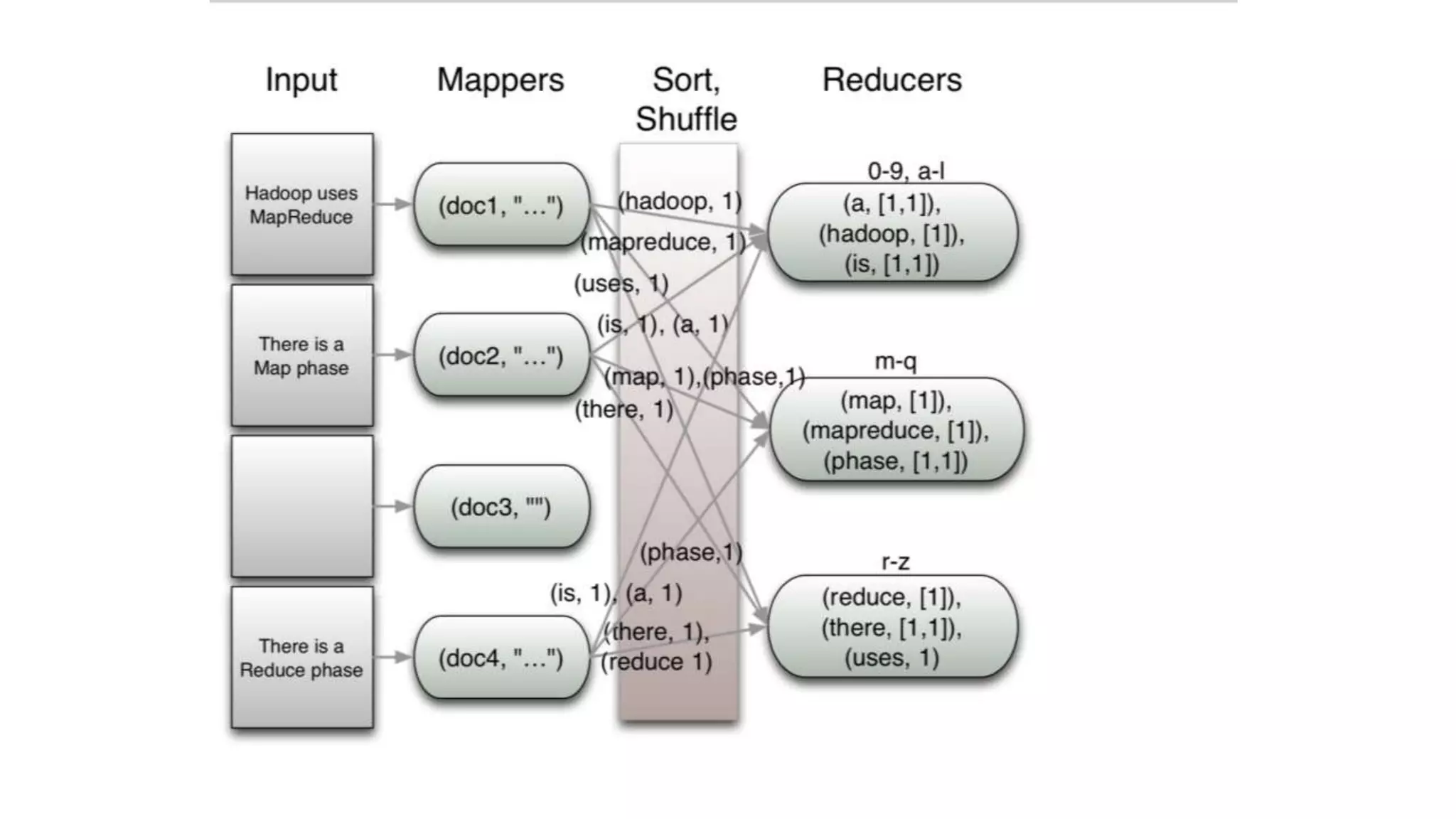
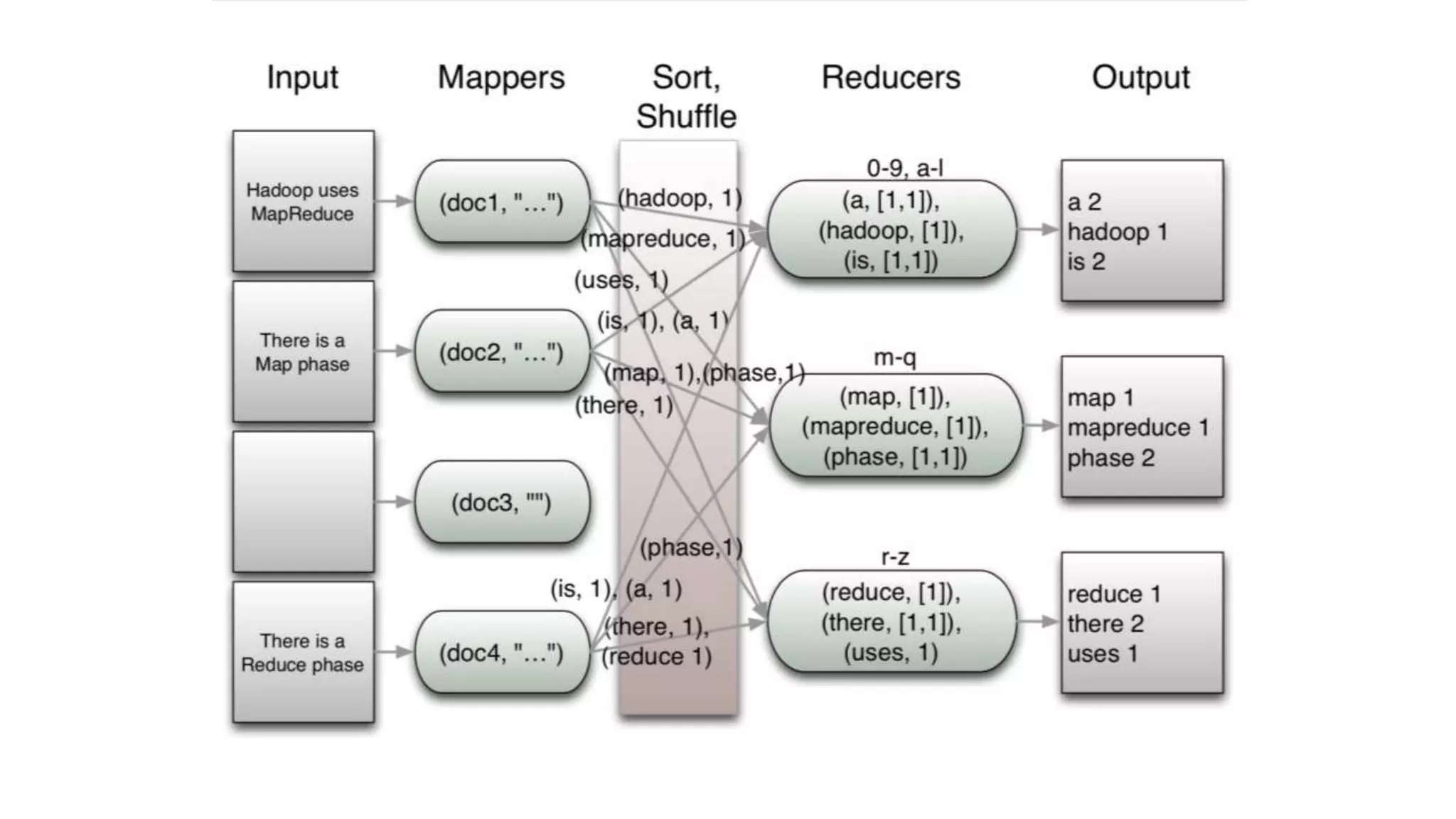
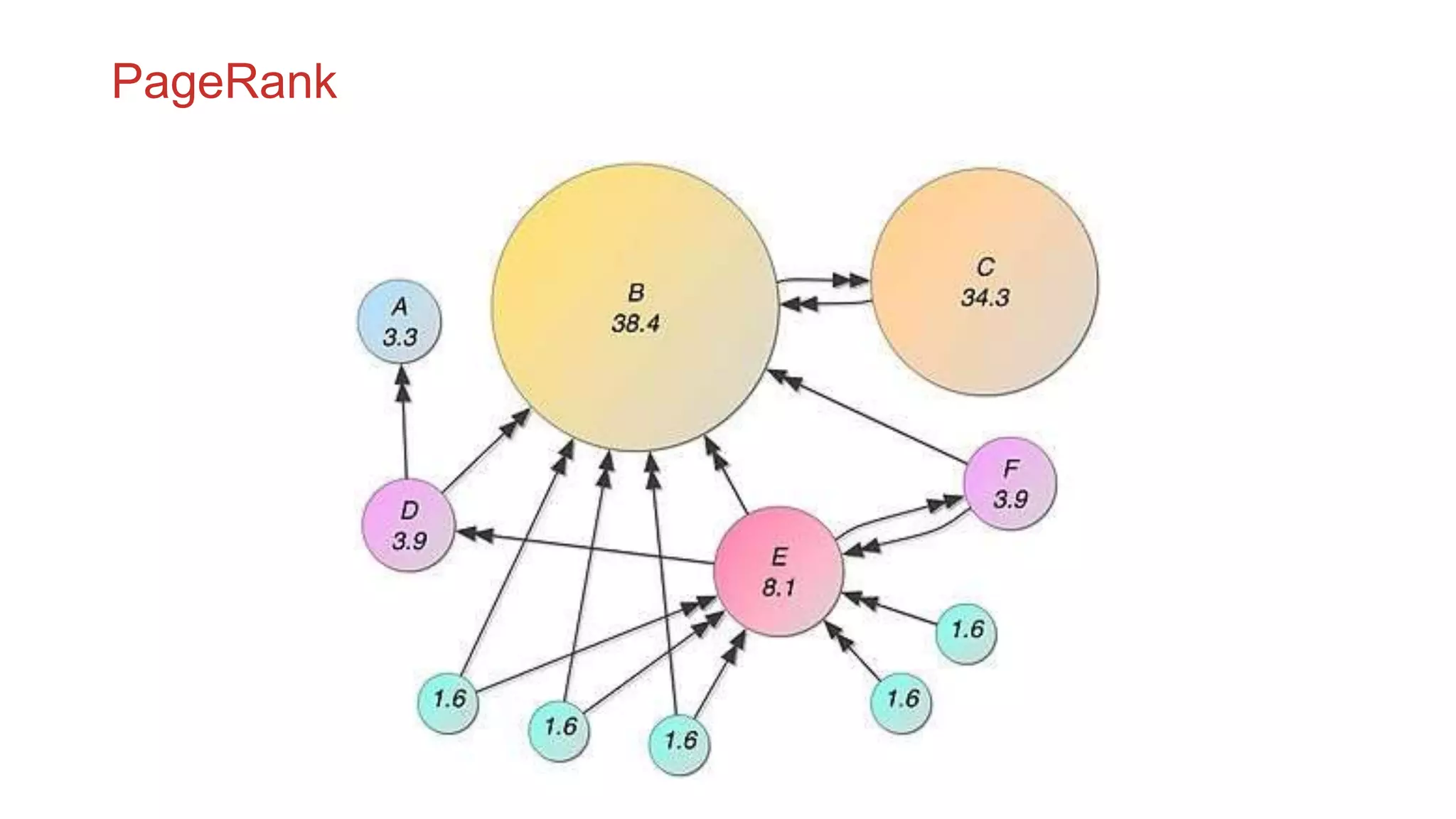
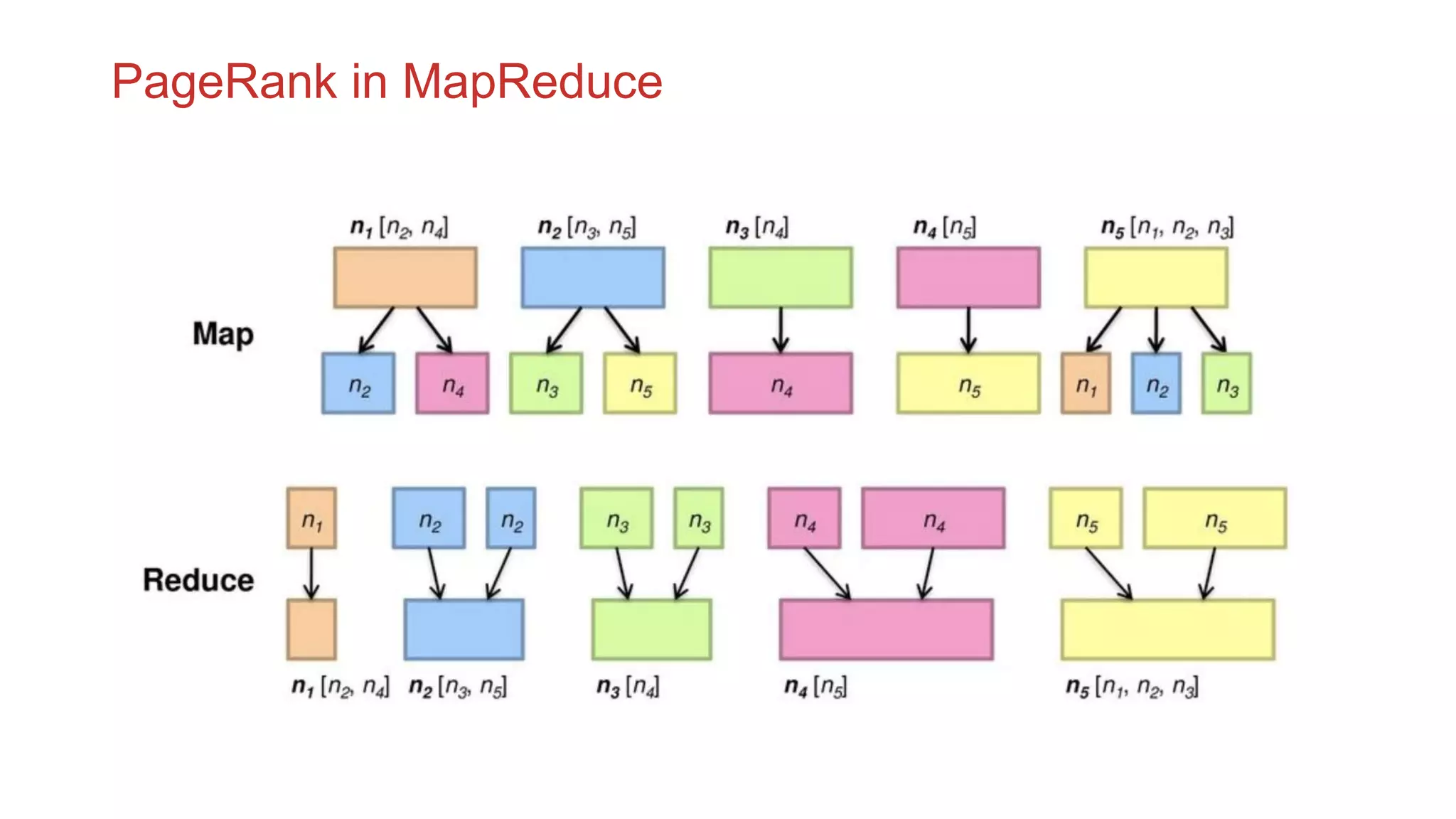



The document discusses the concepts of big data, Hadoop, HDFS, and MapReduce, emphasizing their roles in managing large data sets. Hadoop is a framework for distributed processing, while HDFS is its file system designed for large files with high throughput, though not suitable for low-latency access. MapReduce is highlighted as a critical component for processing data, with examples like word count and PageRank to illustrate its functionality.


































































