Downloaded 235 times

















![PatentCitation Code
public class PatentCitation {
public static class MapClass extends Mapper<LongWritable, Text, Text, Text> {
public void map(LongWritable key, Text value, Context context) throws
IOException, InterruptedException {
String[] citation = value.toString().split(",");
context.write(new Text(citation[1]), new Text(citation[0]));
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text> {
public void reduce(Text key, Iterable<Text> values,Context context)throws
IOException, InterruptedException {
String csv = "";
for (Text val:values) {
if (csv.length() > 0) csv += ",";
csv += val.toString();
}
context.write(key, new Text(csv));
}
}](https://image.slidesharecdn.com/apachehadoop-120625040218-phpapp01/85/Apache-Hadoop-29-320.jpg)






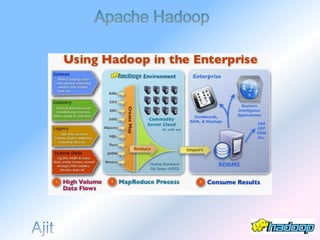
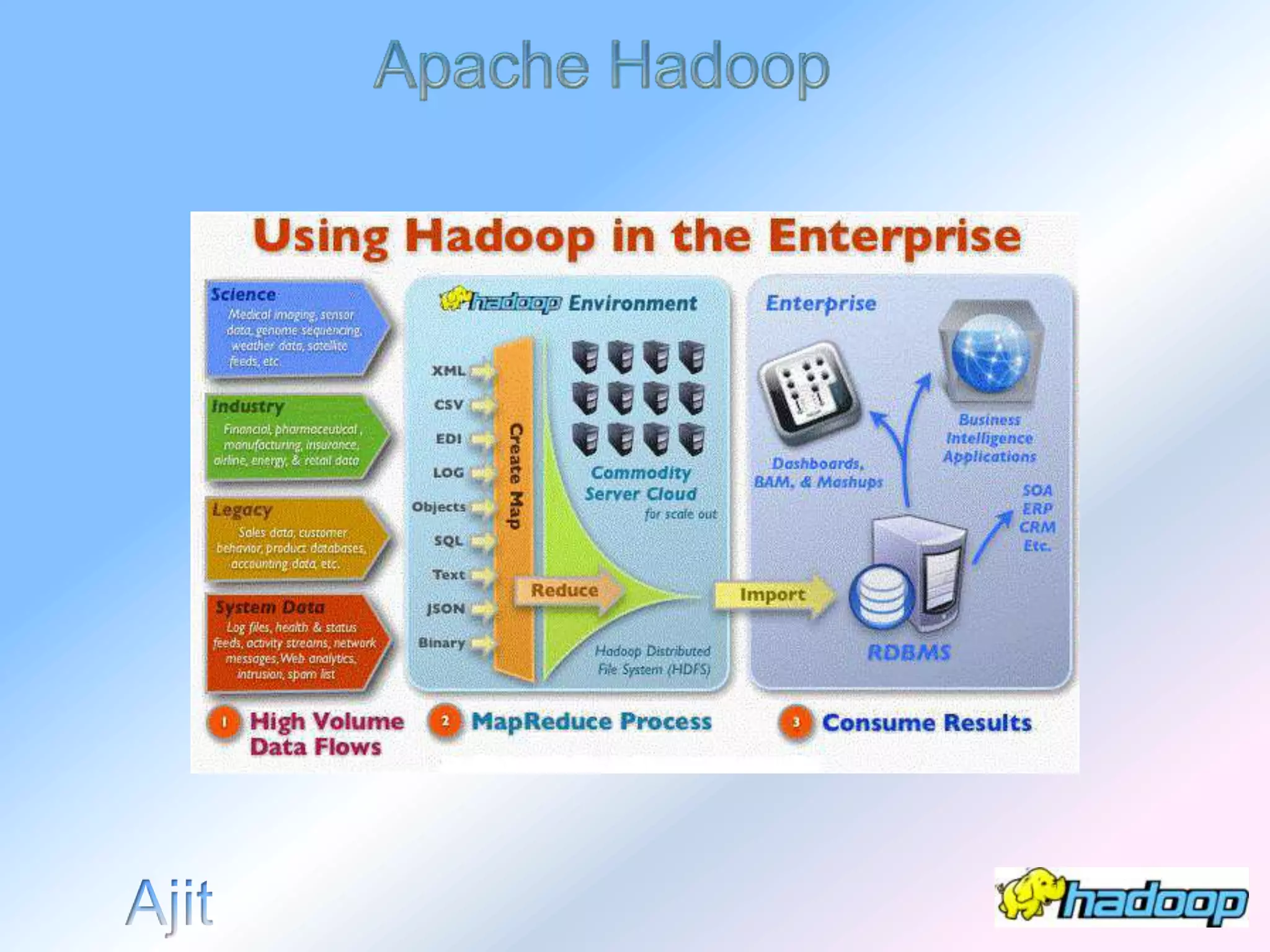
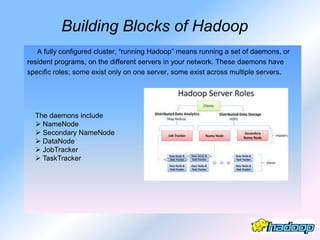
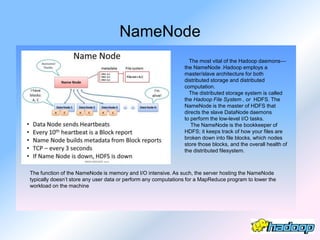
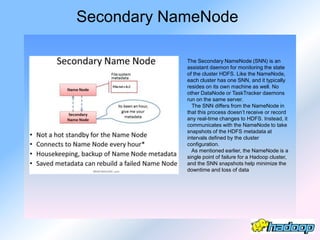
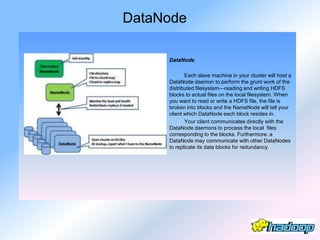
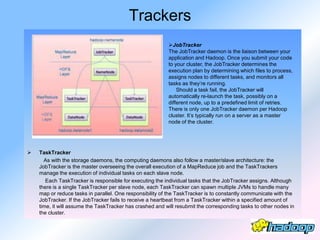
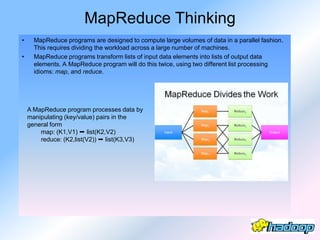
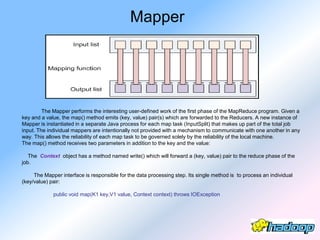
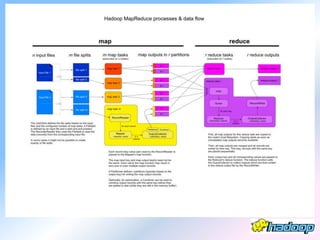
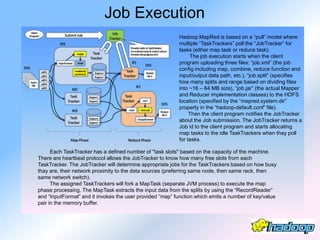
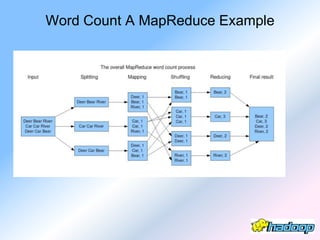
The document describes the evolution and significance of Hadoop as an open-source distributed computing system designed to process large datasets across clusters of commodity hardware. It highlights the challenges posed by exponential data growth and the inadequacies of existing tools, leading to the adoption of Hadoop for its accessibility, robustness, scalability, and simplicity. Key components of Hadoop such as HDFS, mappers, reducers, and the MapReduce programming model are outlined, along with its wide adoption by tech companies and traditional businesses alike.








































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)

