










![History
• [2002] Hadoop, created by Doug Cutting
(part of the Lucene project), starts as an
Open Source search engine for the Web.
• It has its origins in Apache Nutch, parts of
the Lucene project (full text search engine).
• [2003] Google publishes a paper
describing its own distributed file system,
also called GFS.
20](https://image.slidesharecdn.com/002-introductiontohadoopv3-211214034247/75/002-Introduction-to-hadoop-v3-20-2048.jpg)
![History (1)
• [2004] The first version of NDFS, Nutch
Distributed FS, implementing the Google’s
paper.
• [2004] Google publishes, another, paper
introducing the MapReduce algorithm
• [2005] The first version of MapReduce is
implemented in Nutch
21](https://image.slidesharecdn.com/002-introductiontohadoopv3-211214034247/75/002-Introduction-to-hadoop-v3-21-2048.jpg)
![History (2)
• [2005 (end)] Nutch’s MapReduce is
running on NDFS
• [2006 (Feb)] Nutch’s MapReduce and
NDFS became the core of a new Lucene’s
subproject.
• [2008] Yahoo launches the World’s largest
Hadoop PRODUCTION site
22](https://image.slidesharecdn.com/002-introductiontohadoopv3-211214034247/75/002-Introduction-to-hadoop-v3-22-2048.jpg)













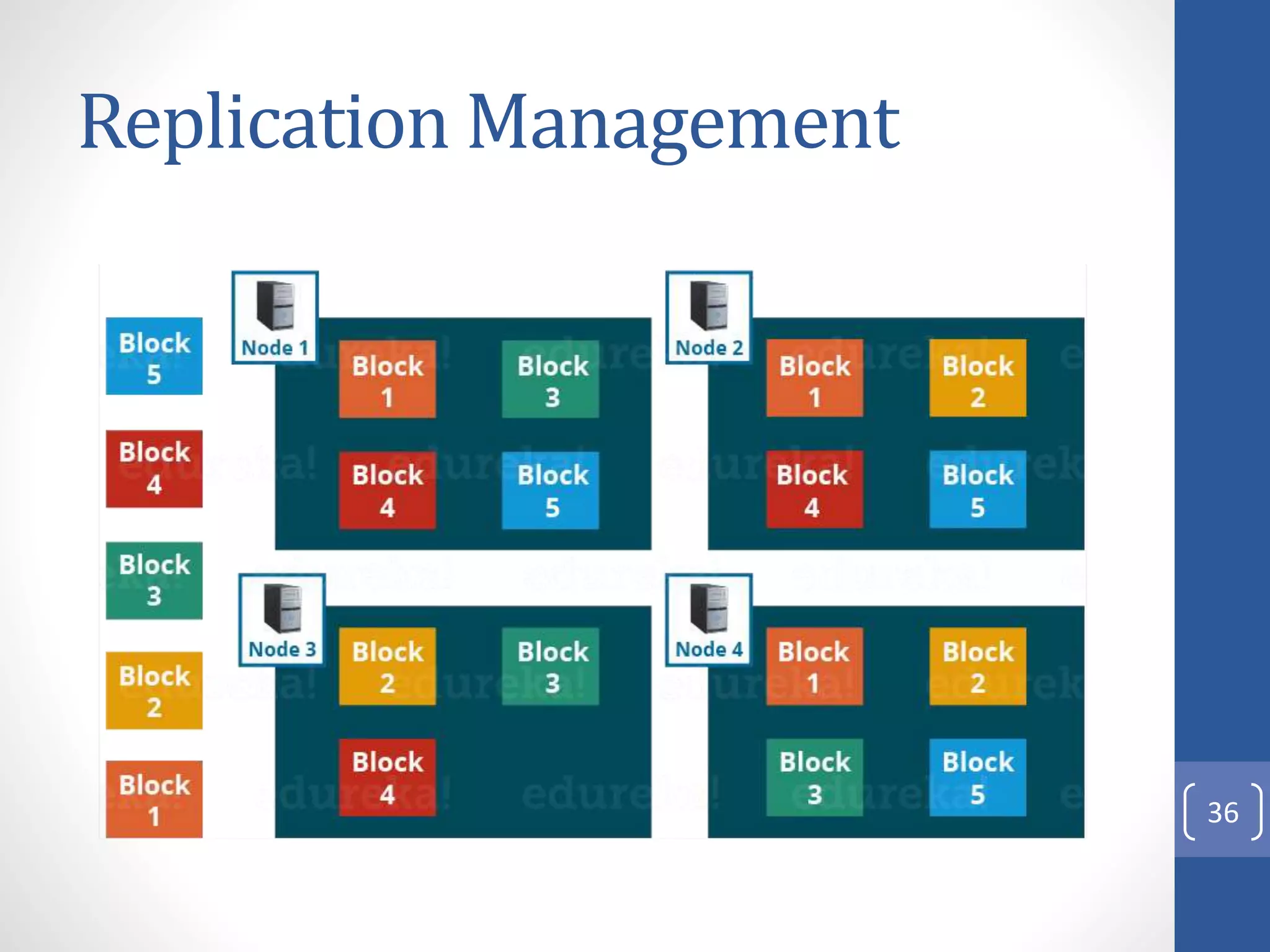
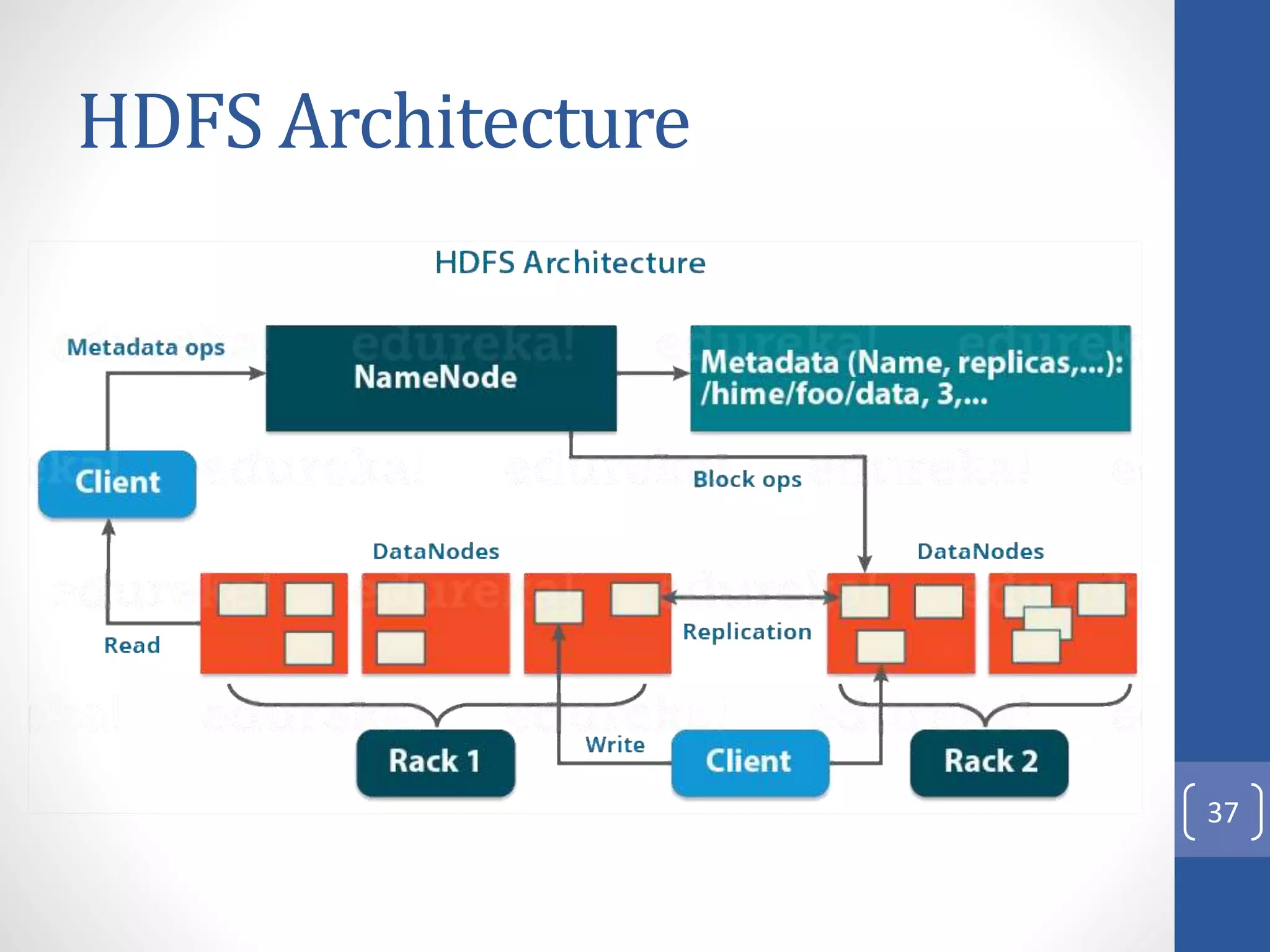
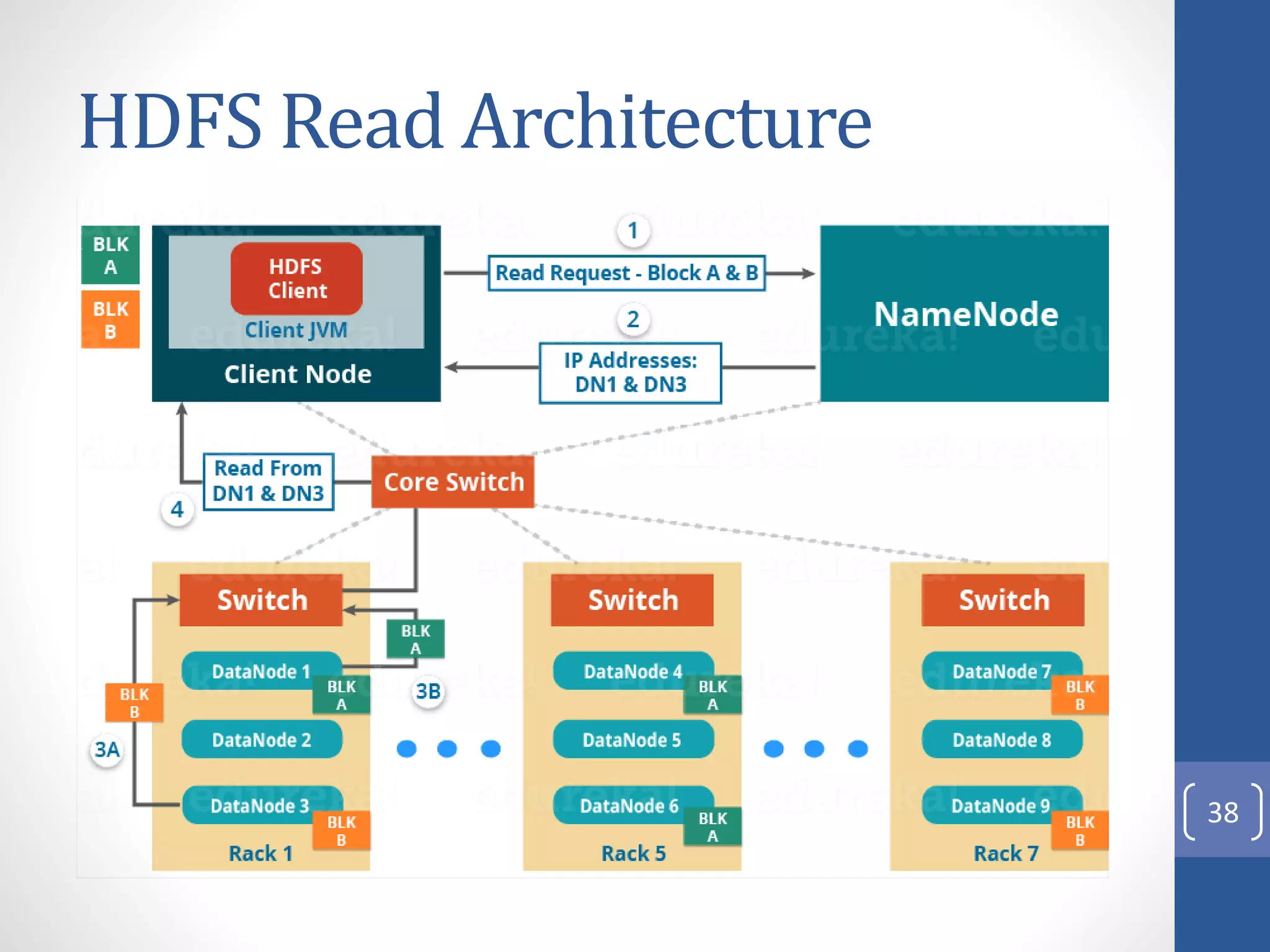
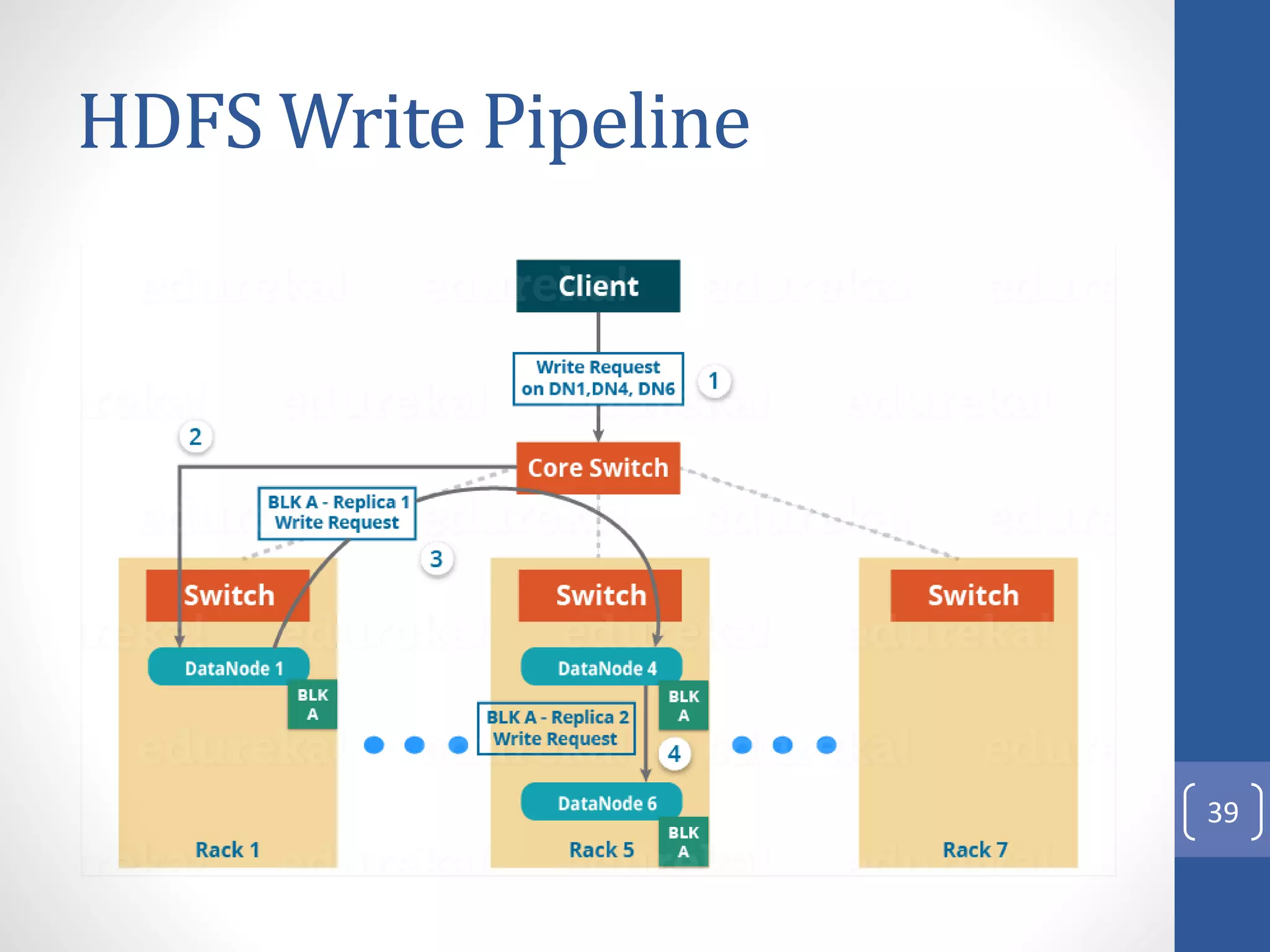
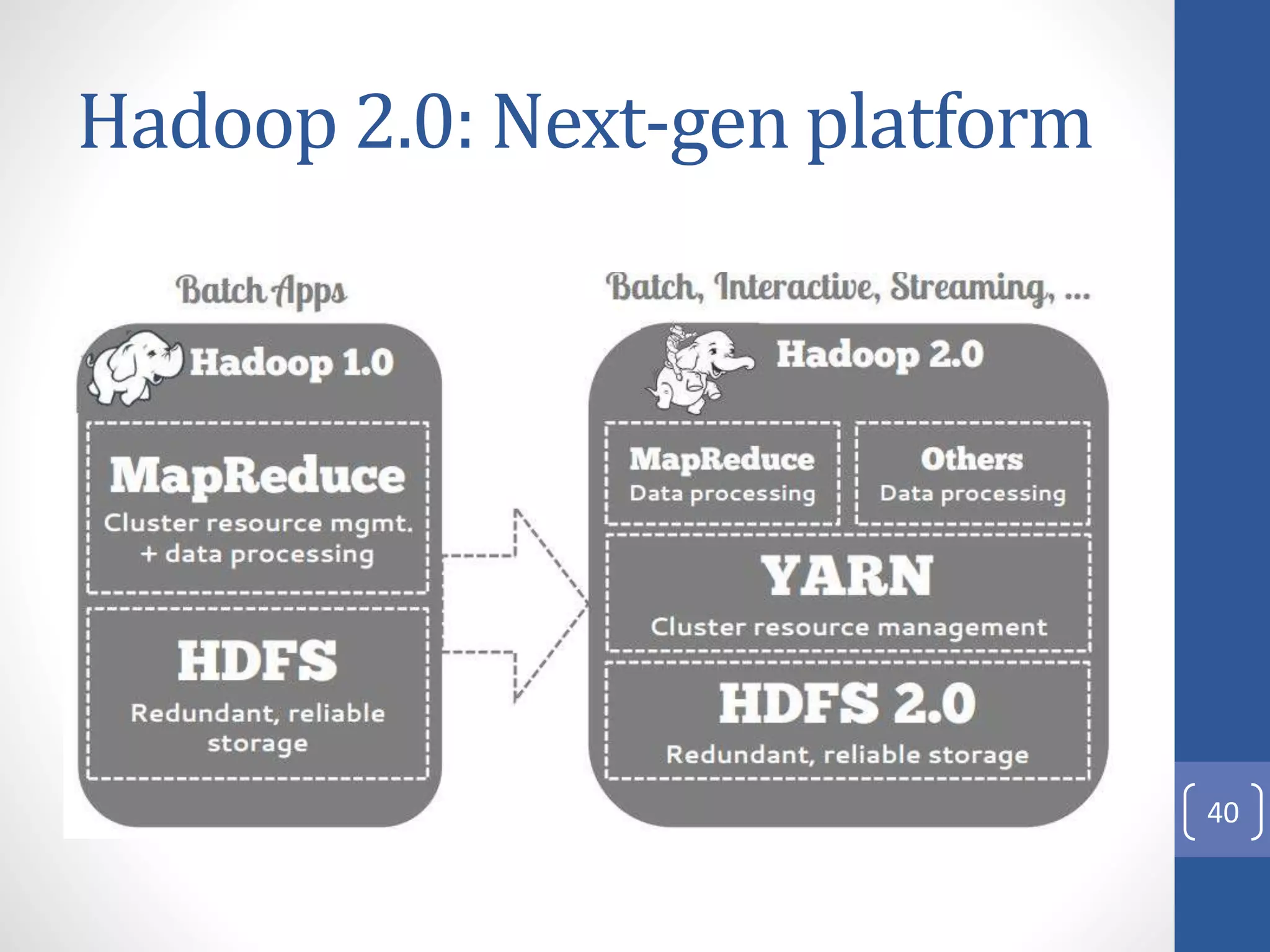
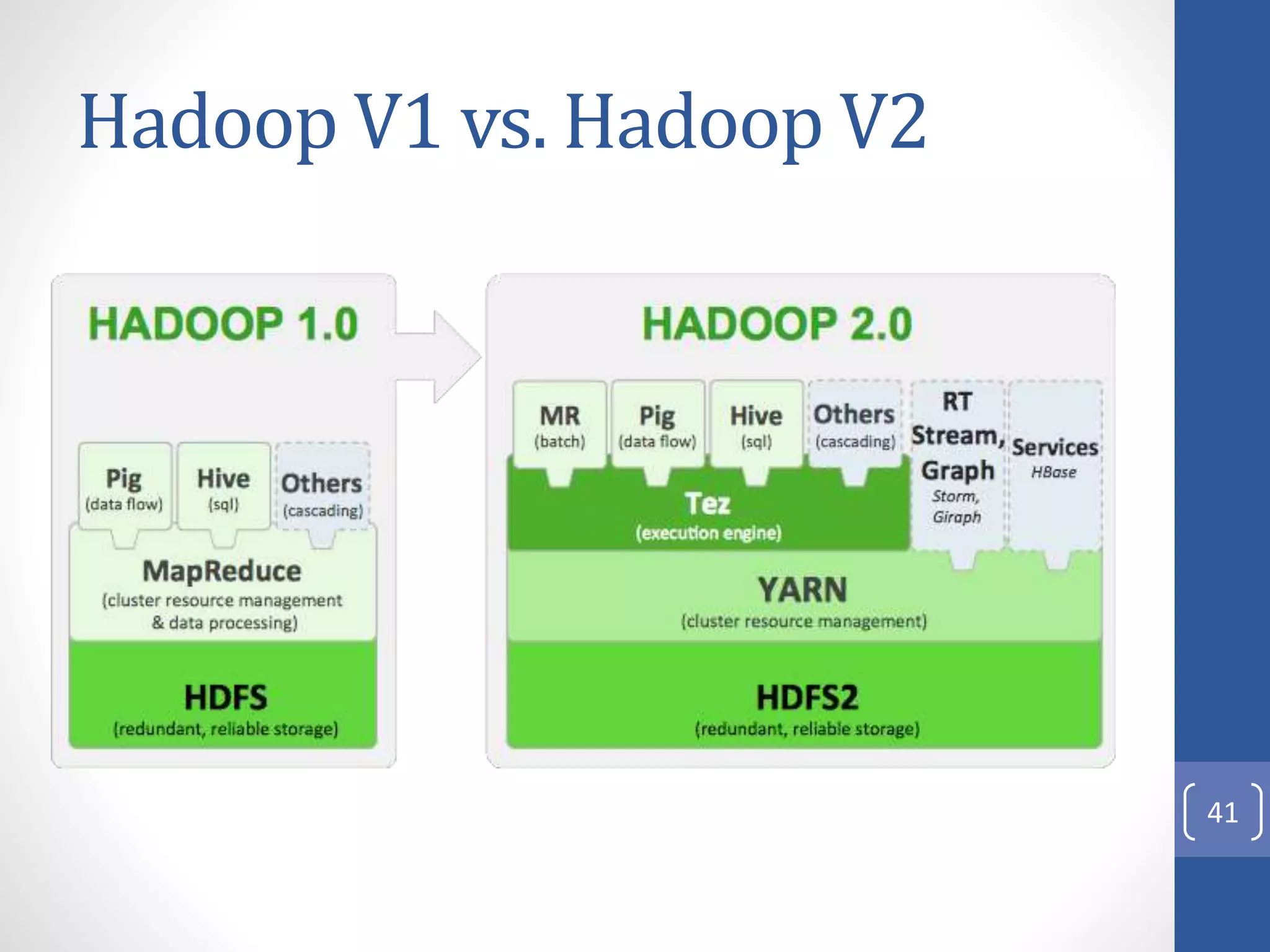
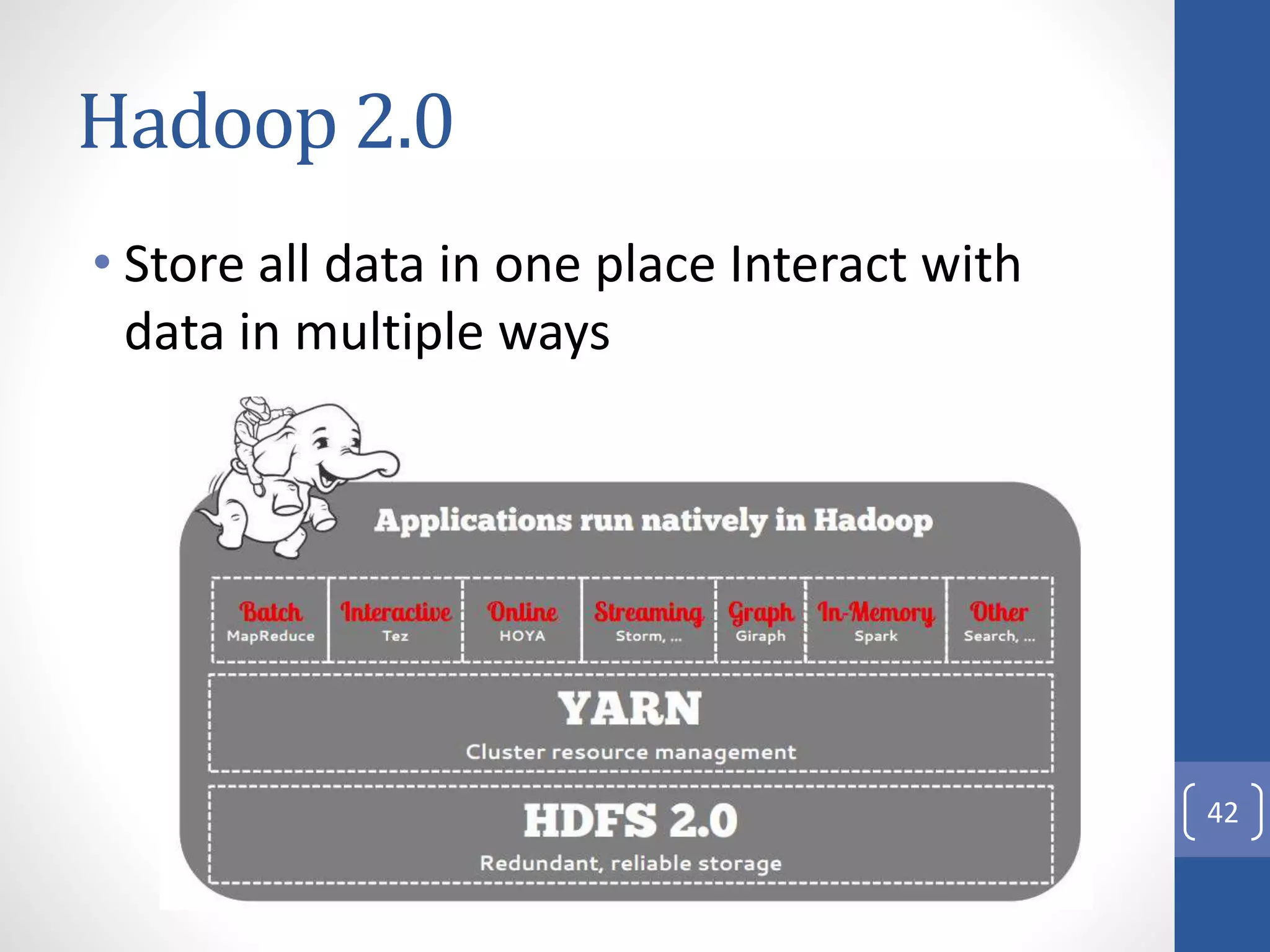

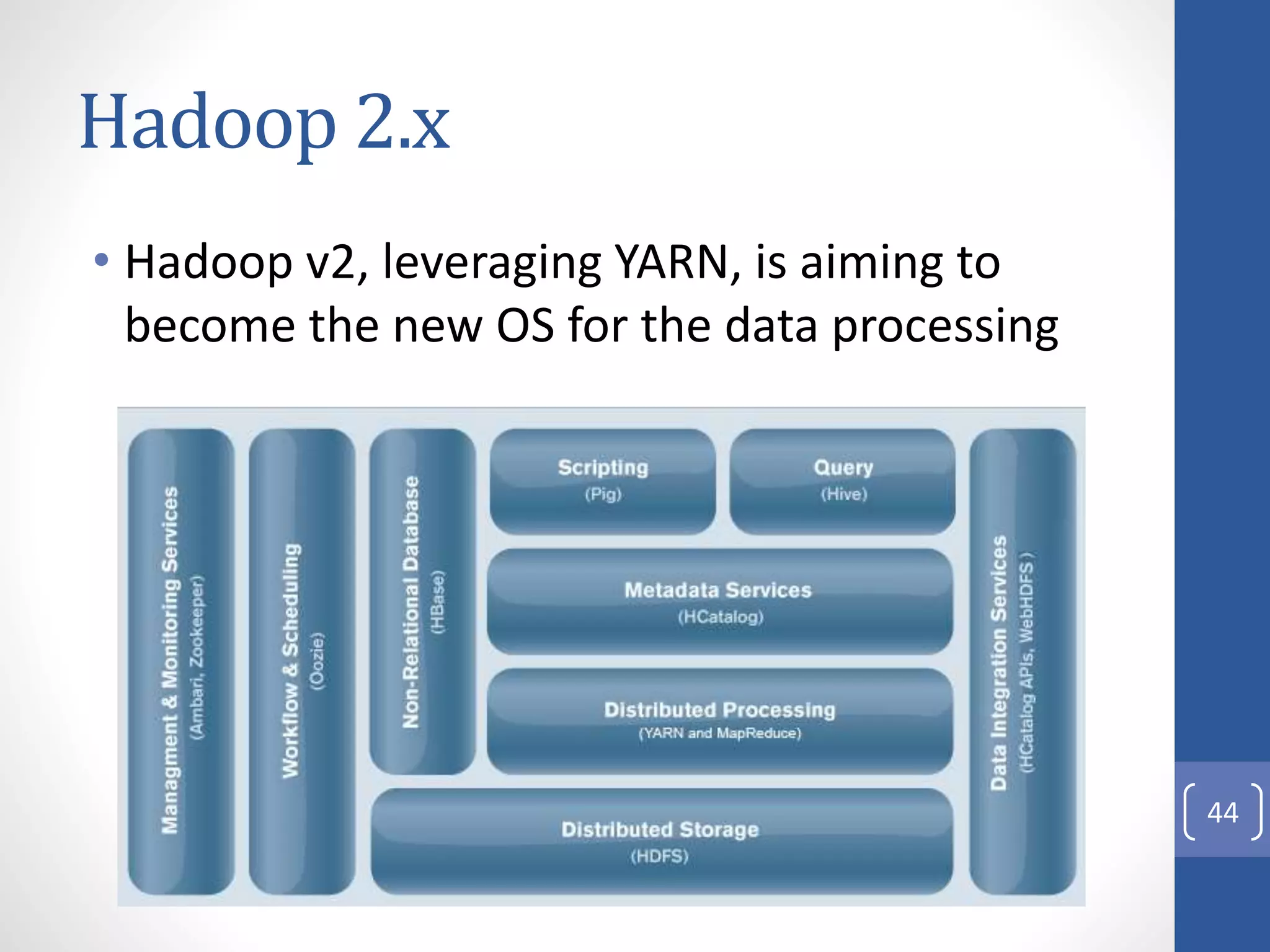

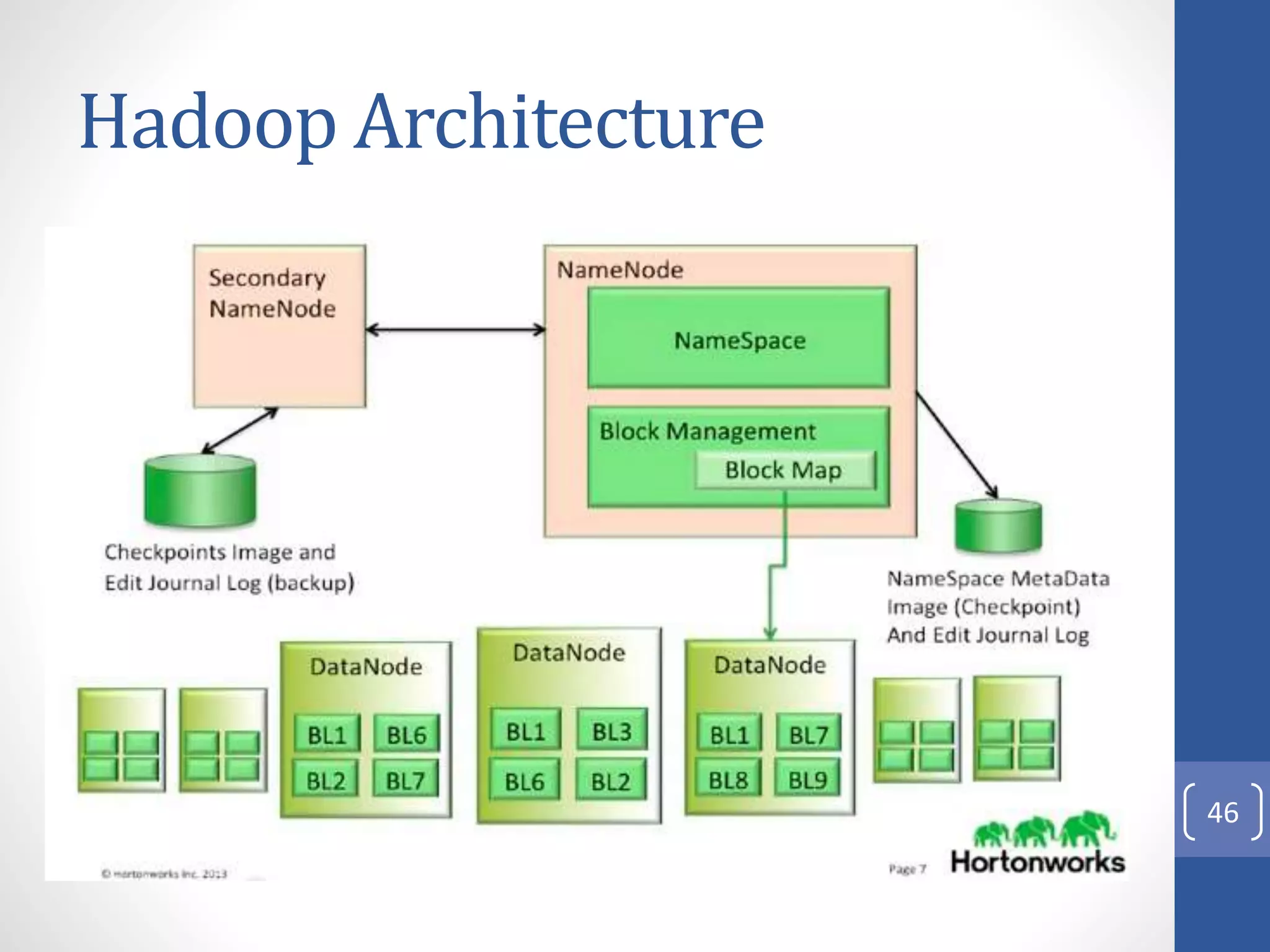
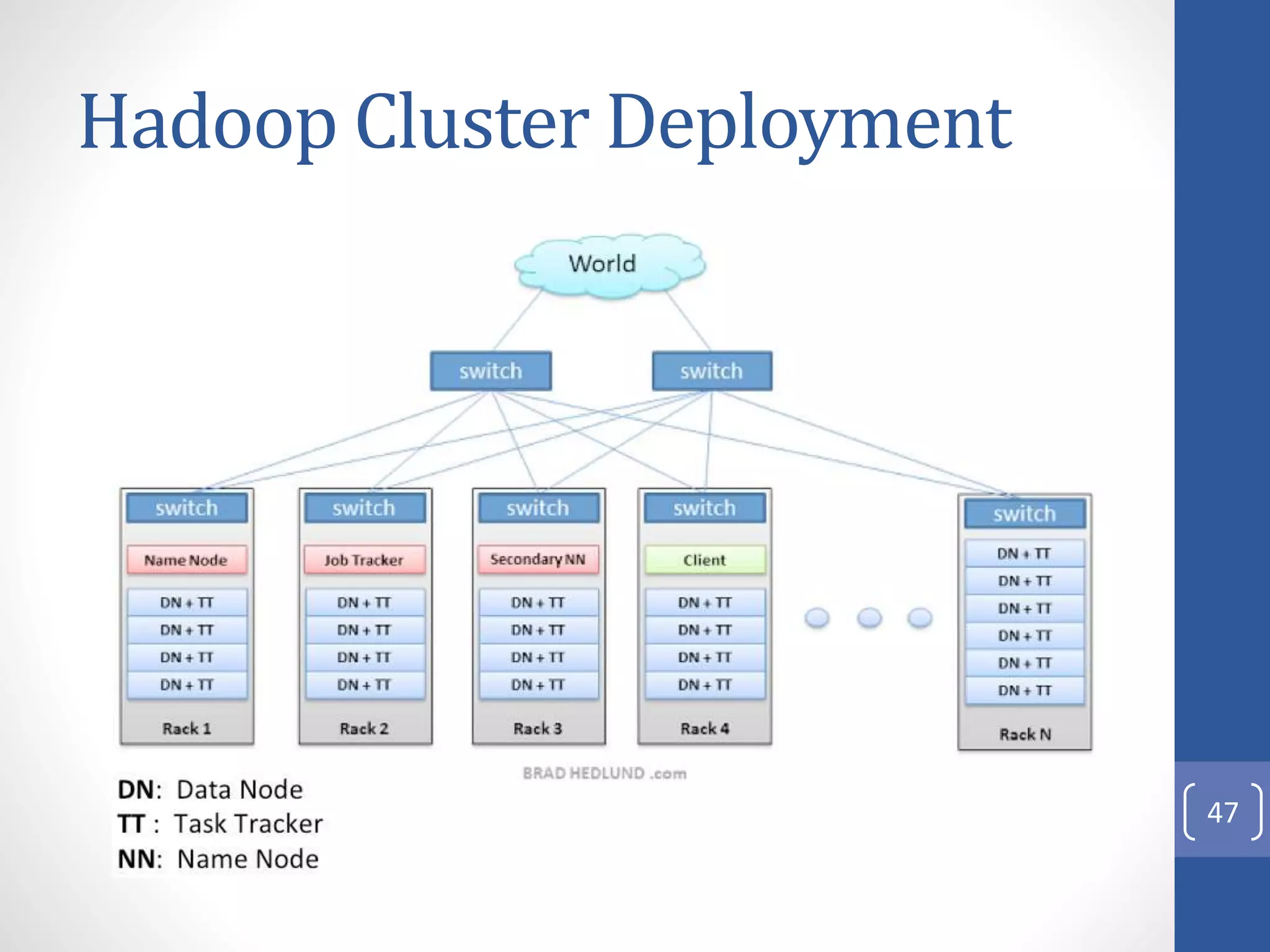
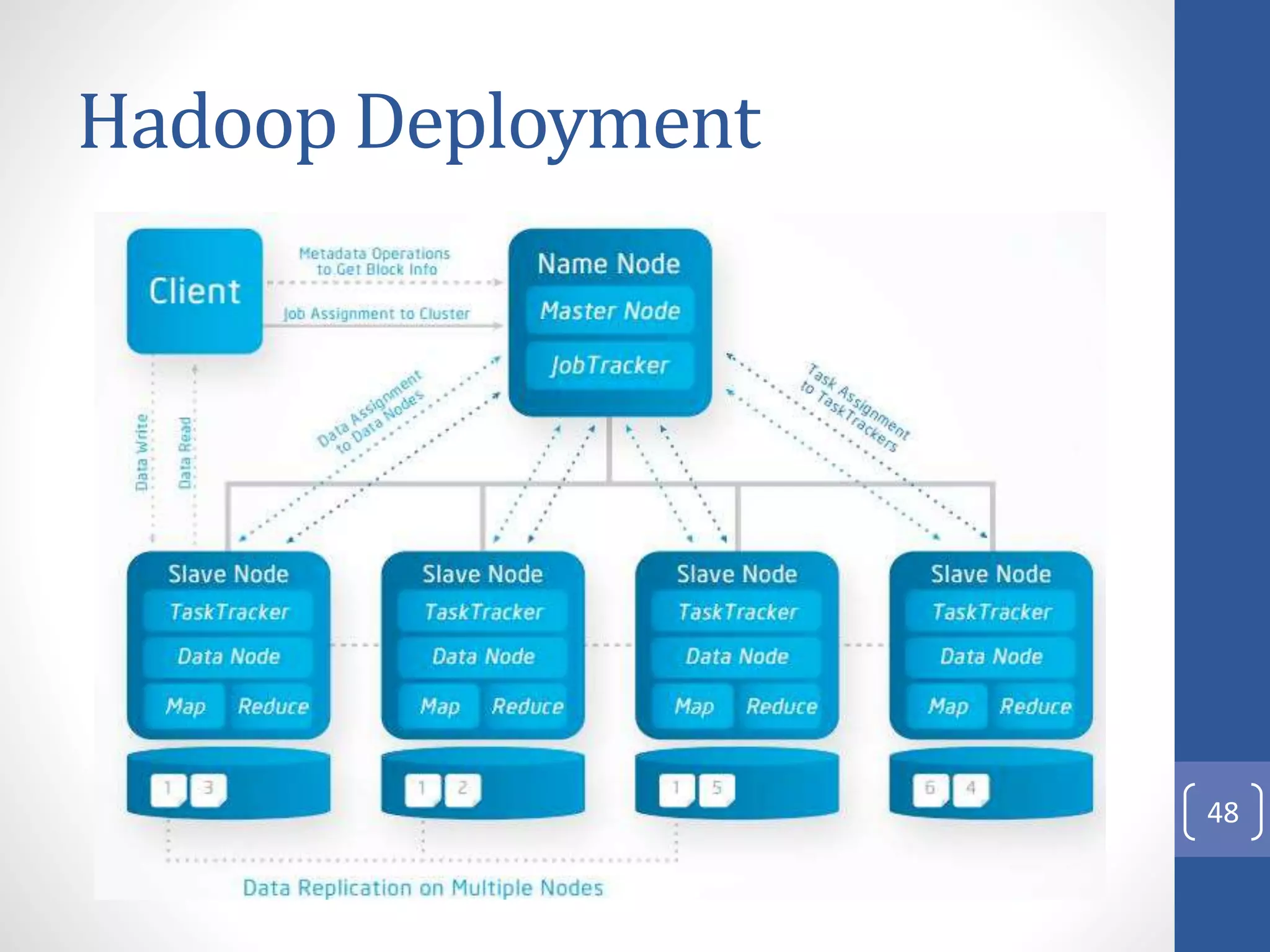



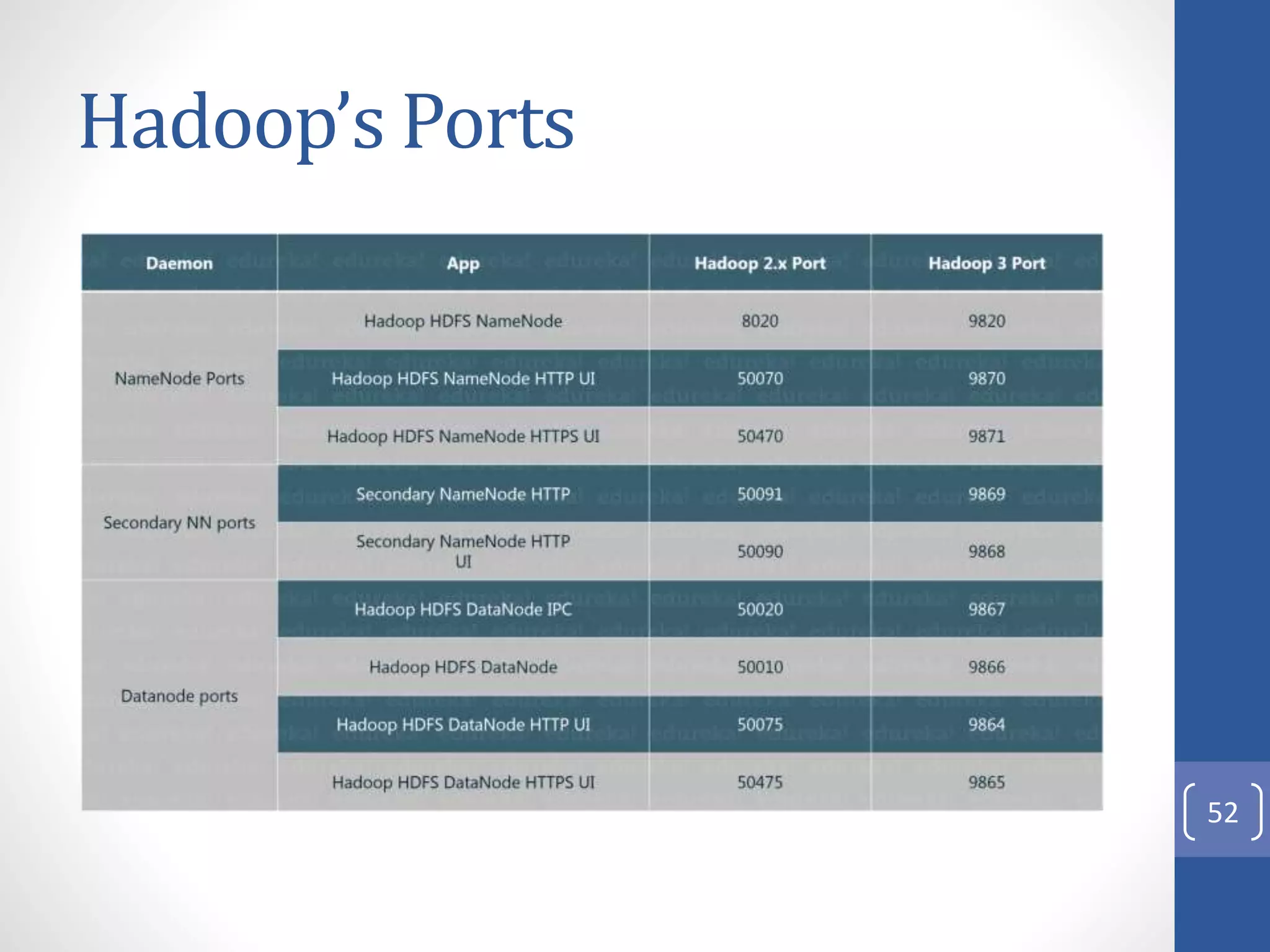

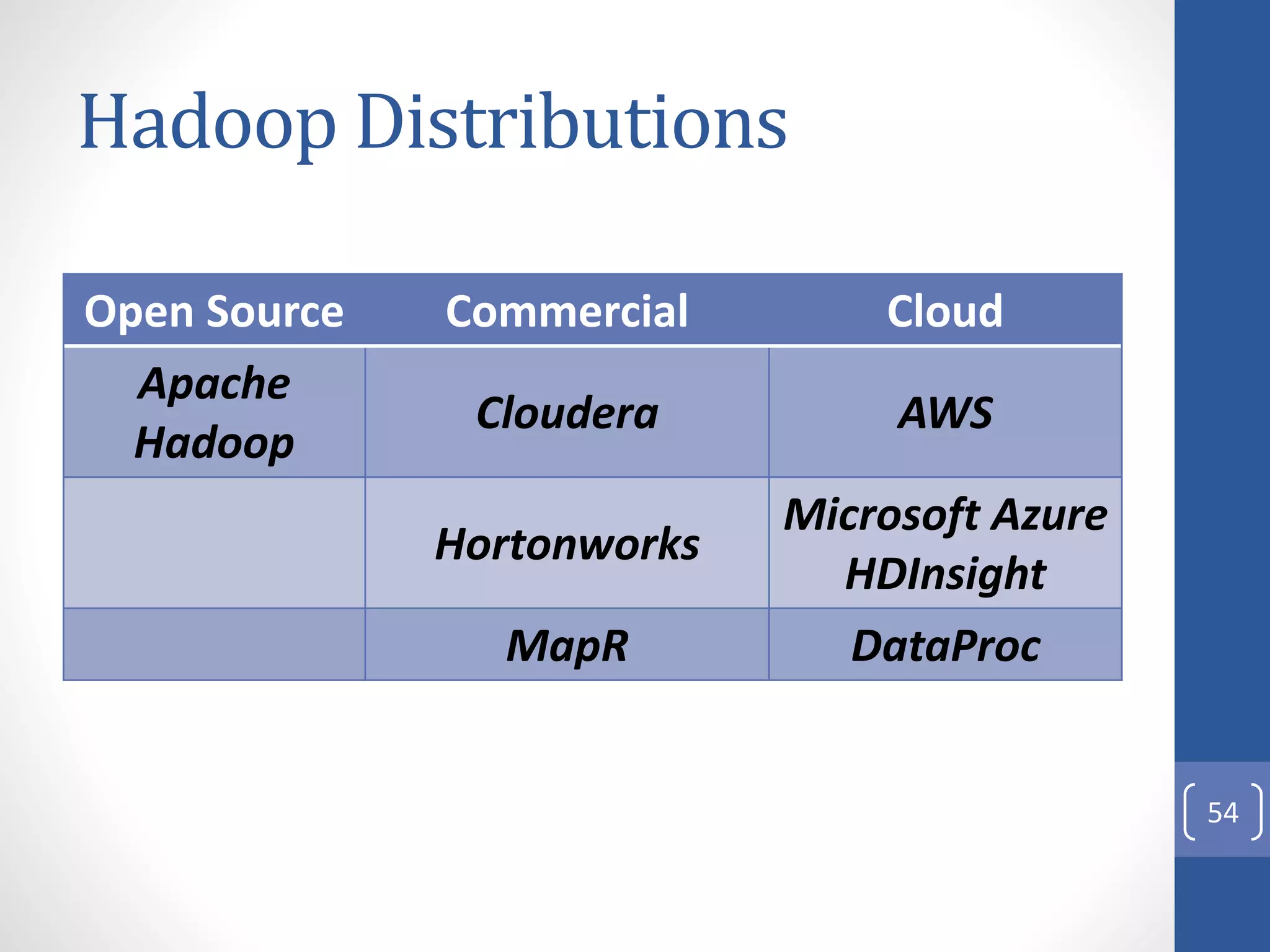

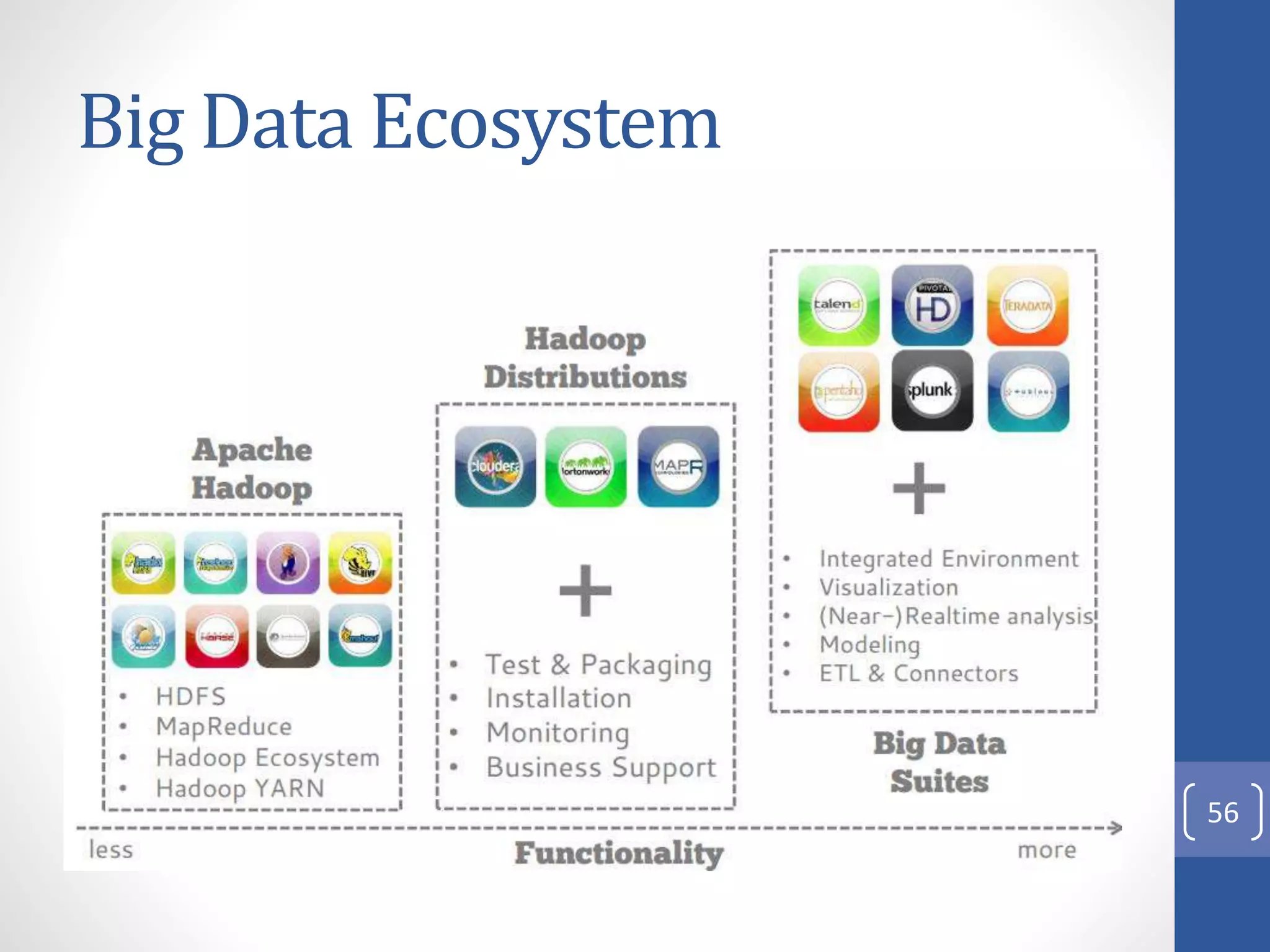

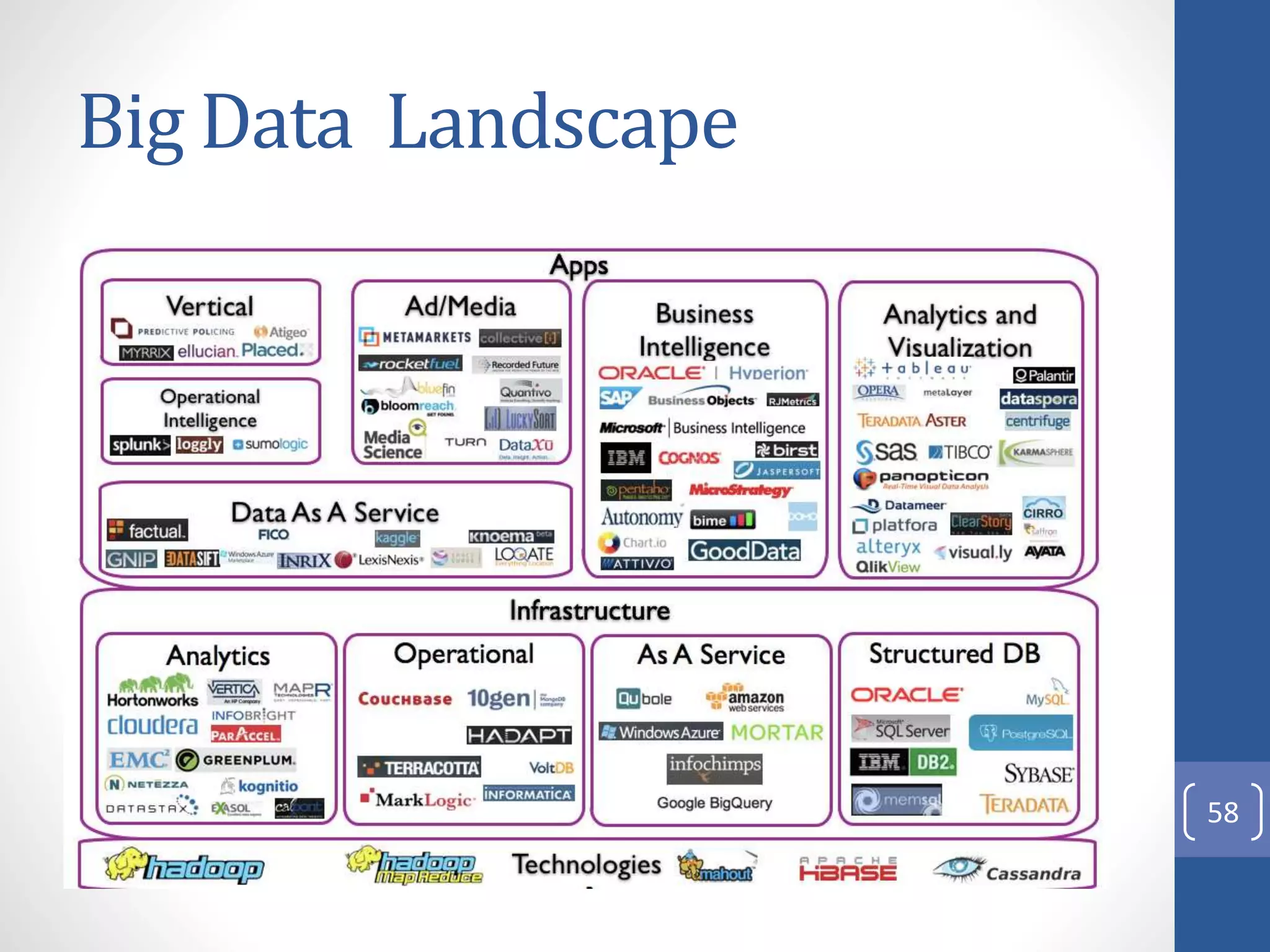

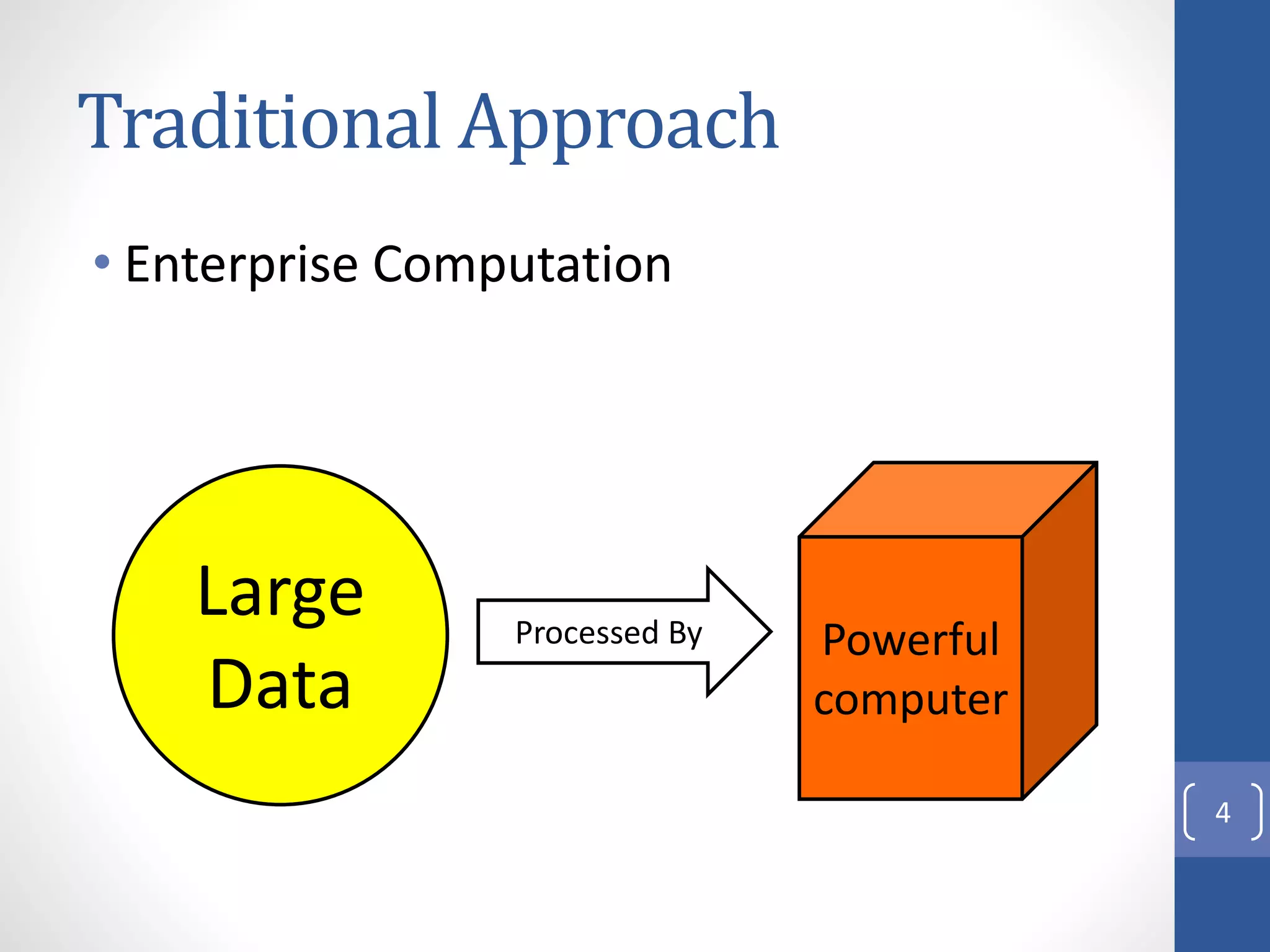
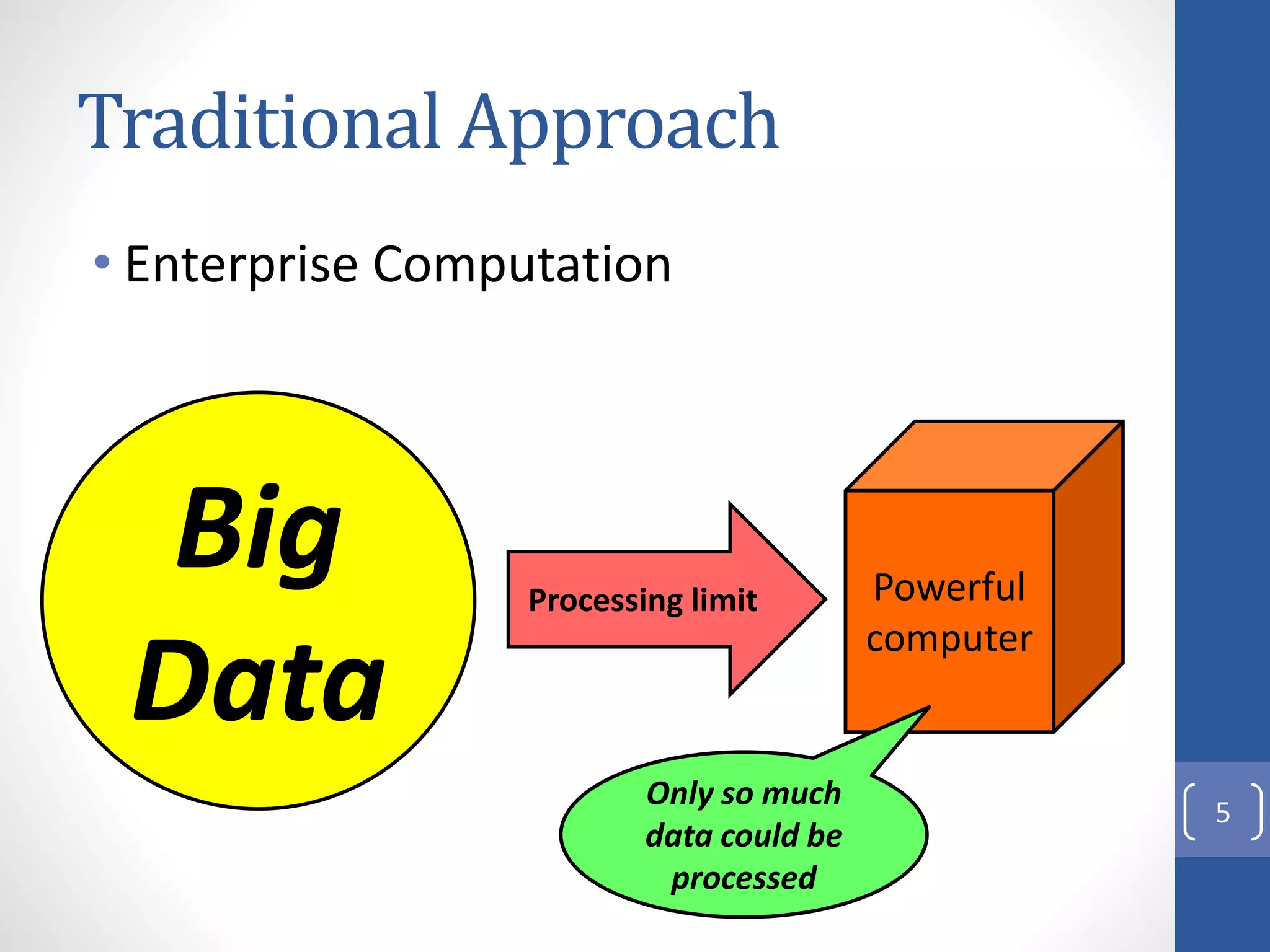
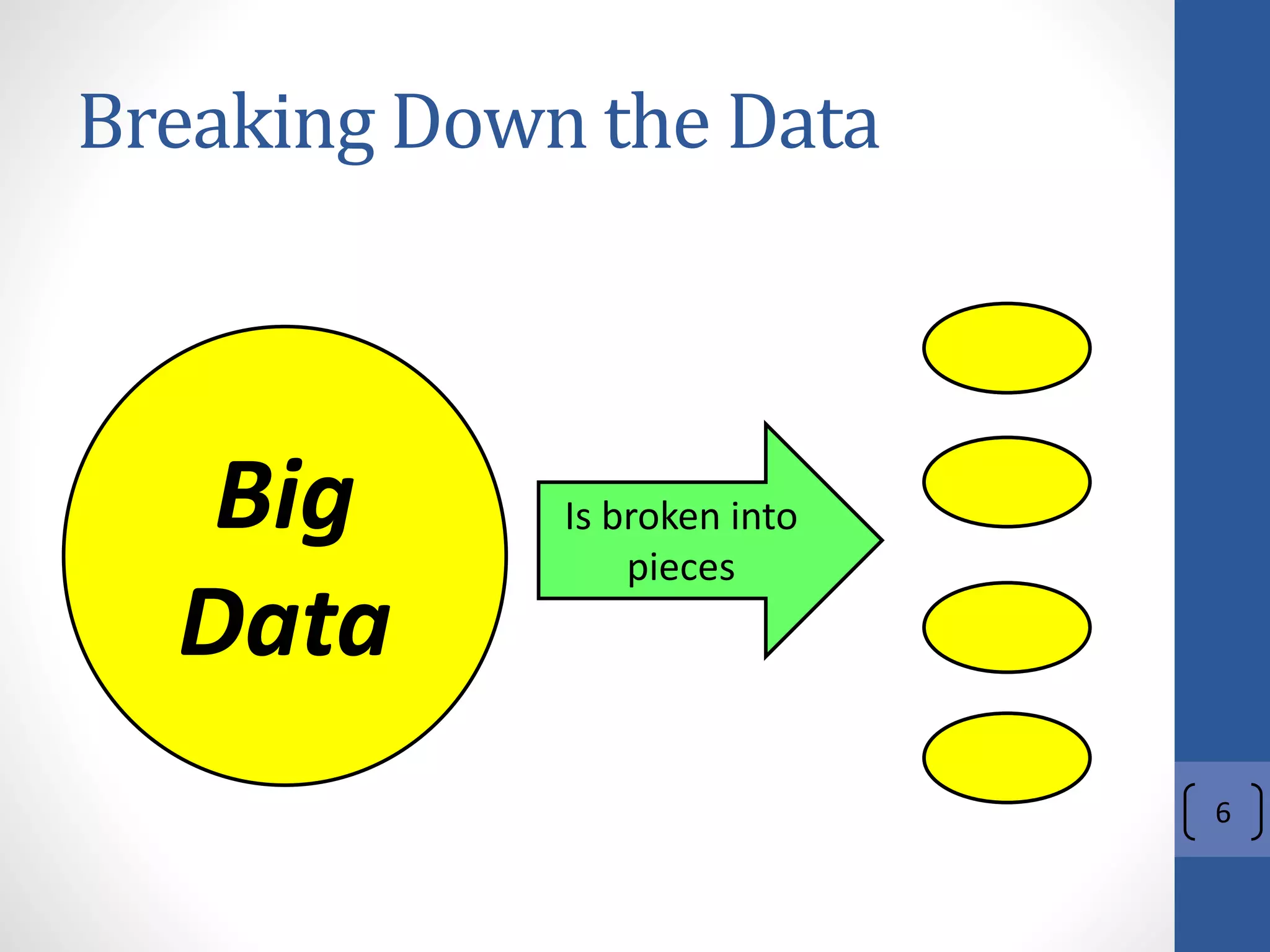
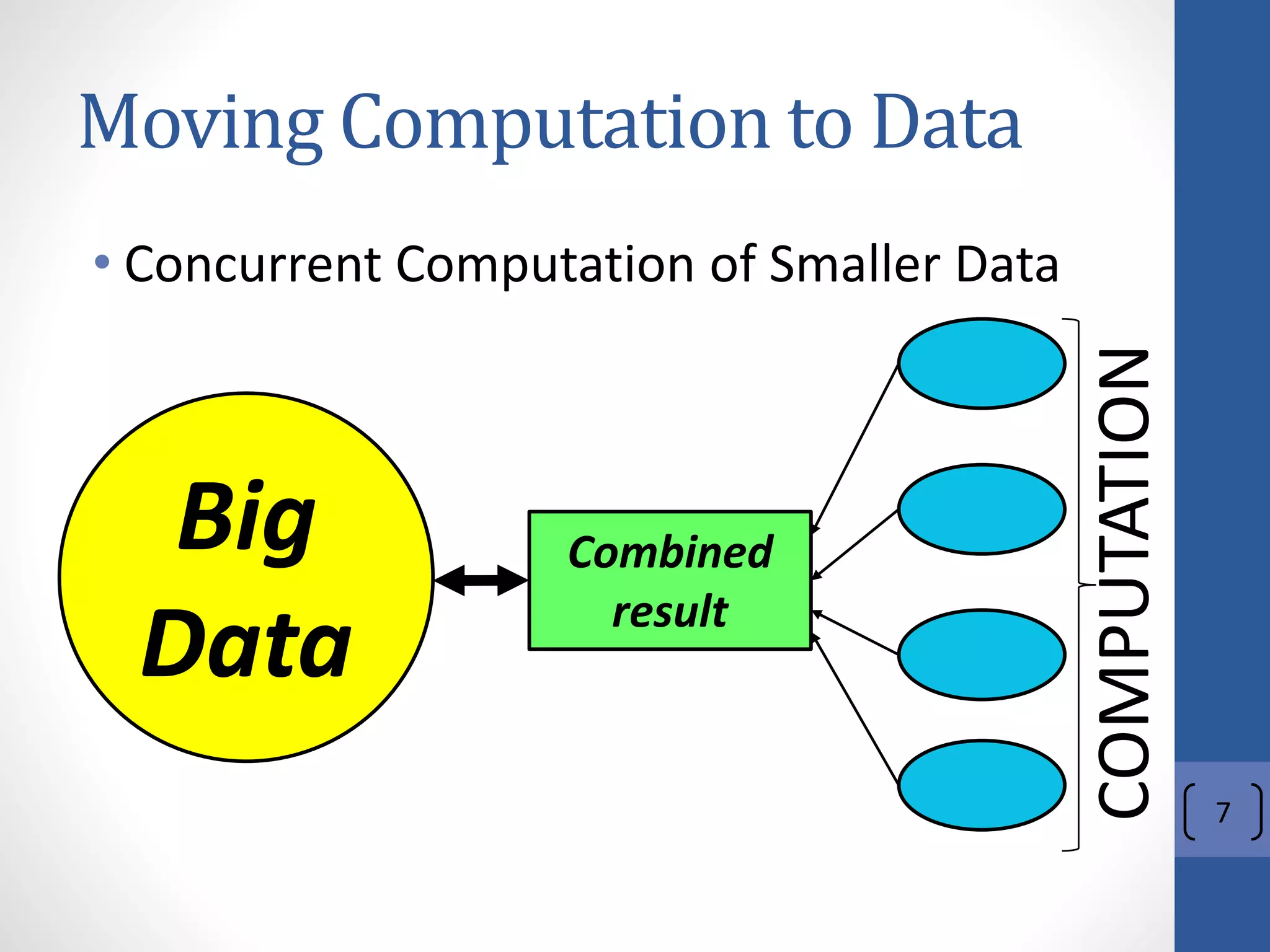
The document provides an introduction to Apache Hadoop, including: 1) It describes Hadoop's architecture which uses HDFS for distributed storage and MapReduce for distributed processing of large datasets across commodity clusters. 2) It explains that Hadoop solves issues of hardware failure and combining data through replication of data blocks and a simple MapReduce programming model. 3) It gives a brief history of Hadoop originating from Doug Cutting's Nutch project and the influence of Google's papers on distributed file systems and MapReduce.



































































