Downloaded 350 times








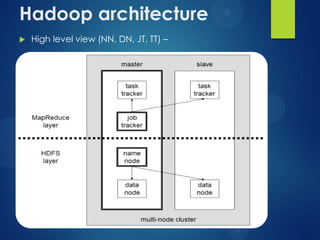

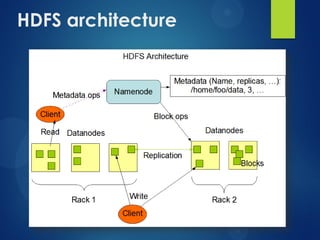



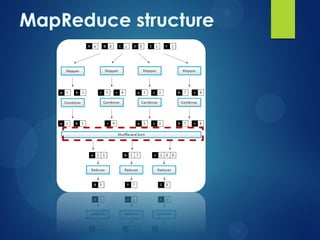

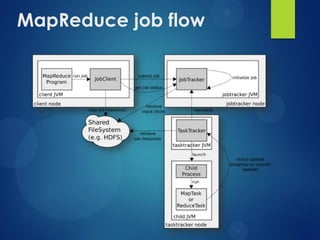







The document provides an agenda for a presentation on Hadoop. It discusses the need for new big data processing platforms due to the large amounts of data generated each day by companies like Twitter, Facebook, and Google. It then summarizes the origin of Hadoop, describes what Hadoop is and some of its core components like HDFS and MapReduce. The document outlines the Hadoop architecture and ecosystem and provides examples of real world use cases for Hadoop. It poses the question of when an organization should implement Hadoop and concludes by asking if there are any questions.











































































































