
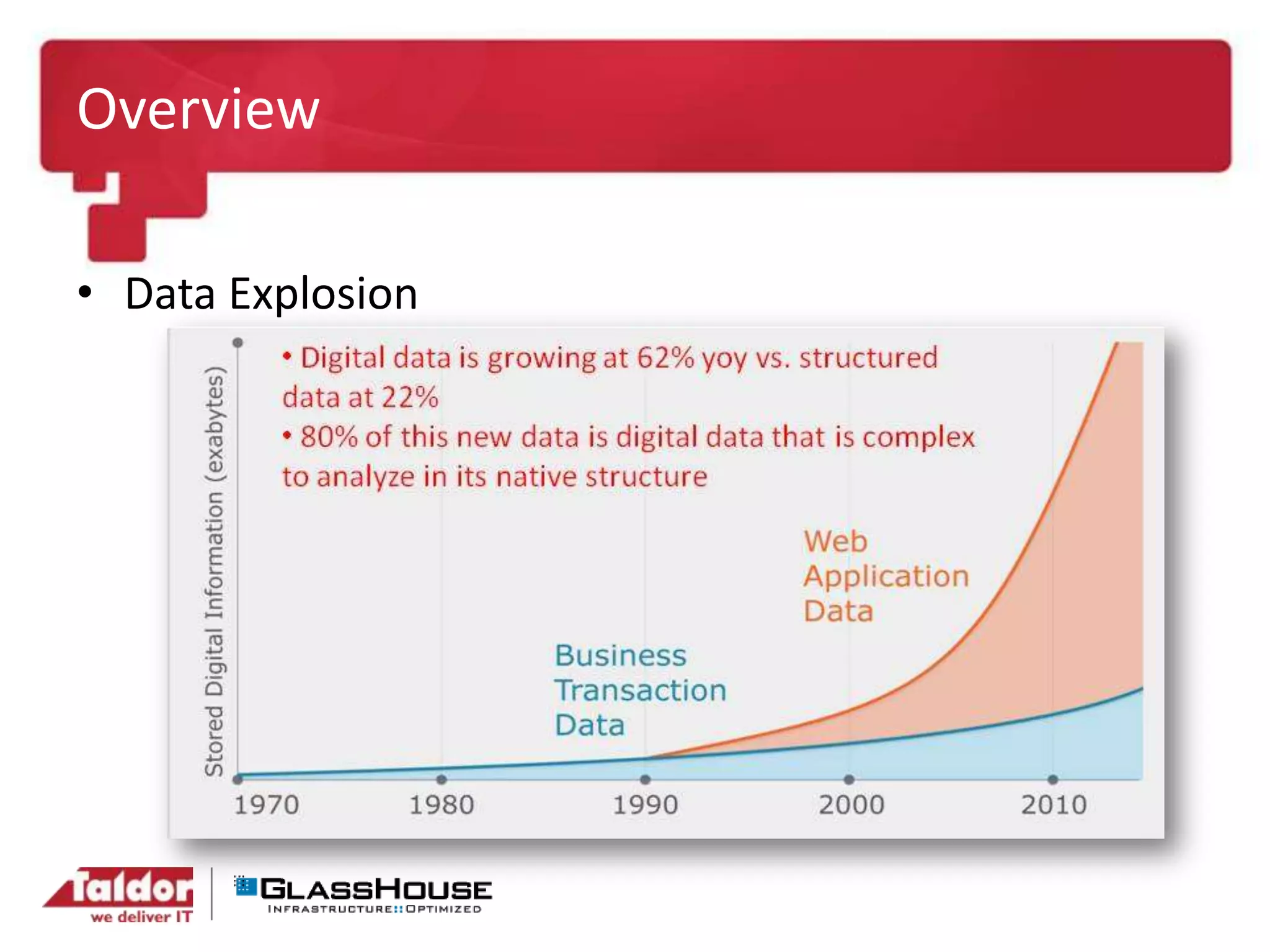


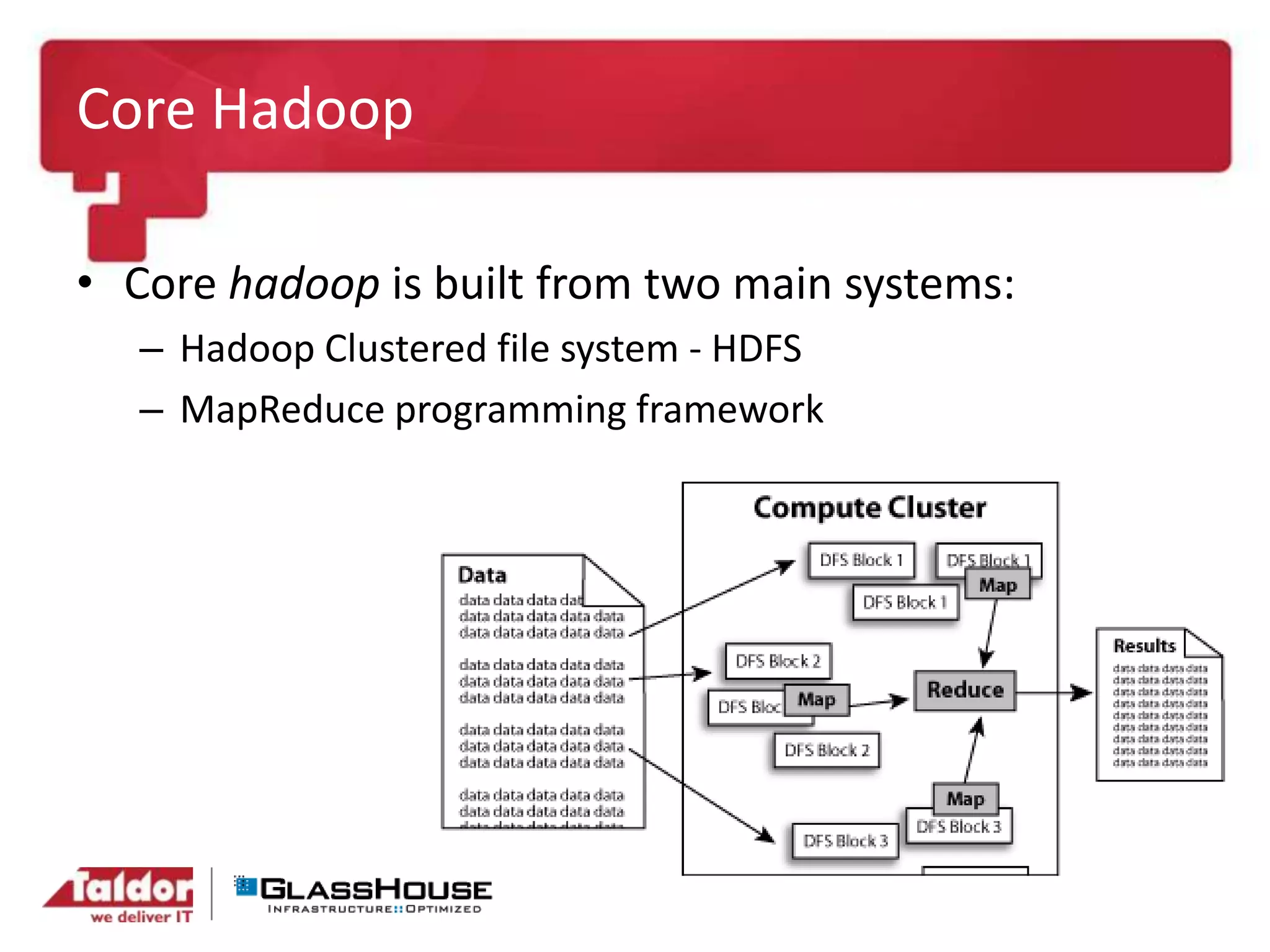
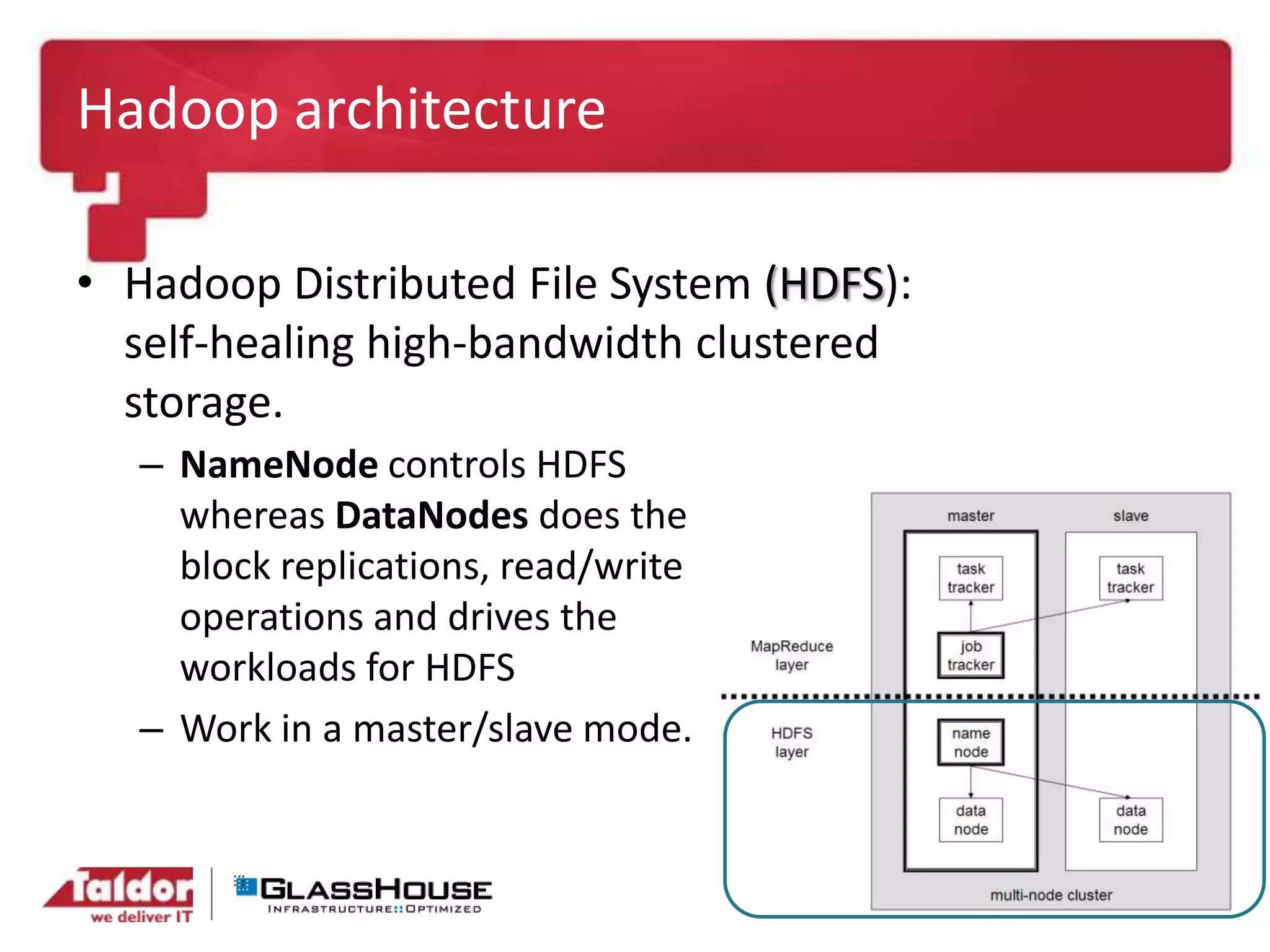
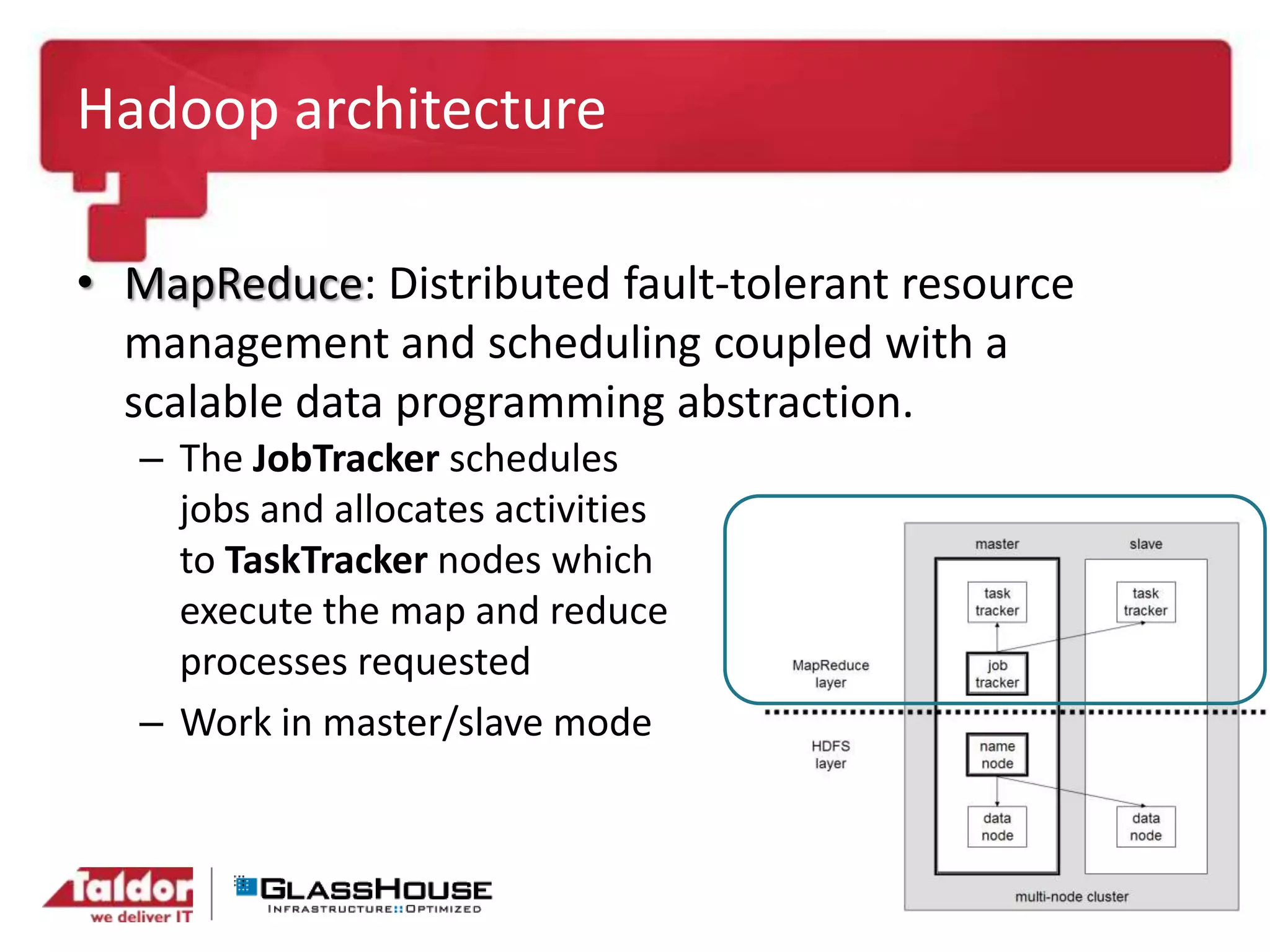








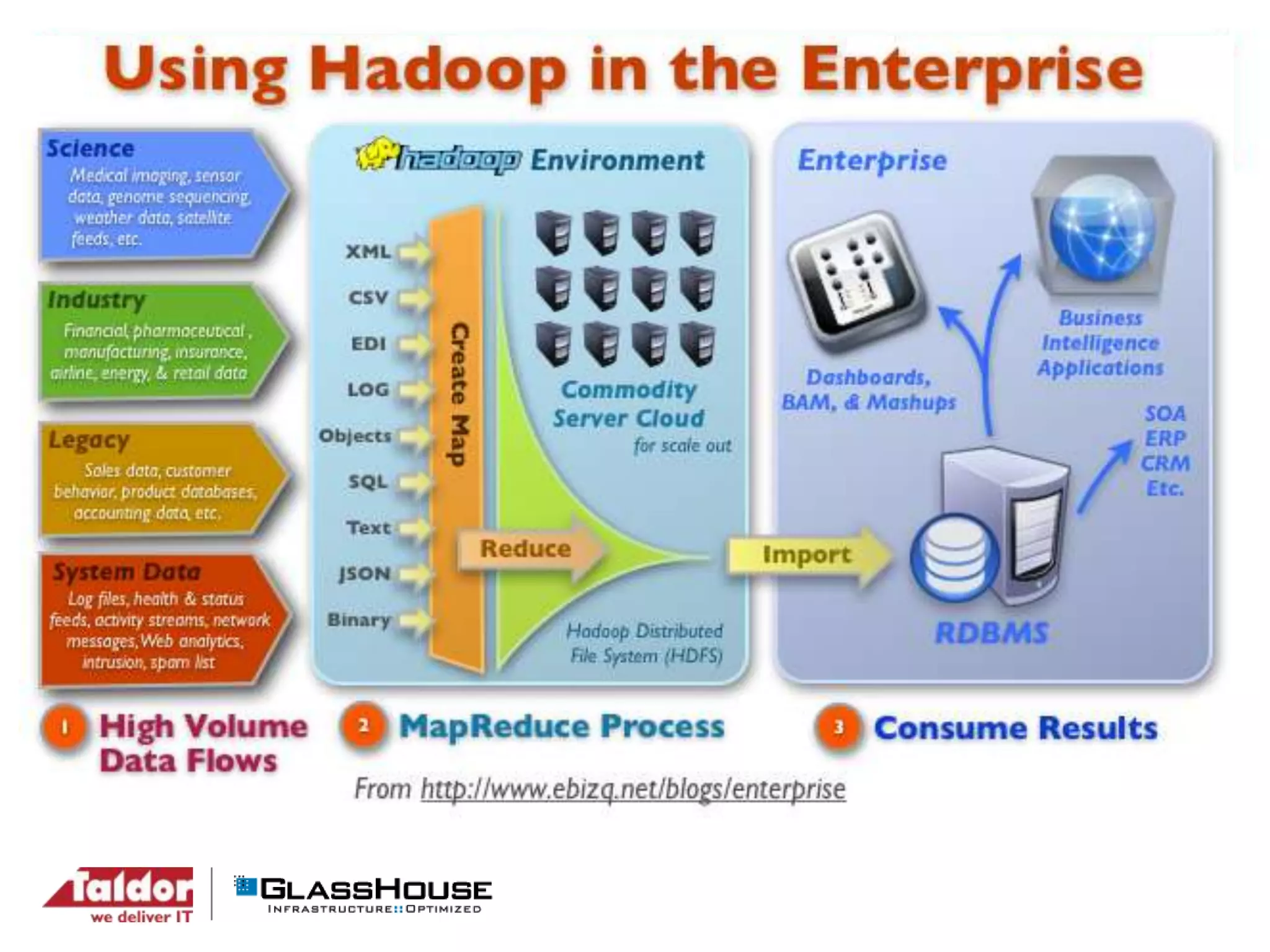


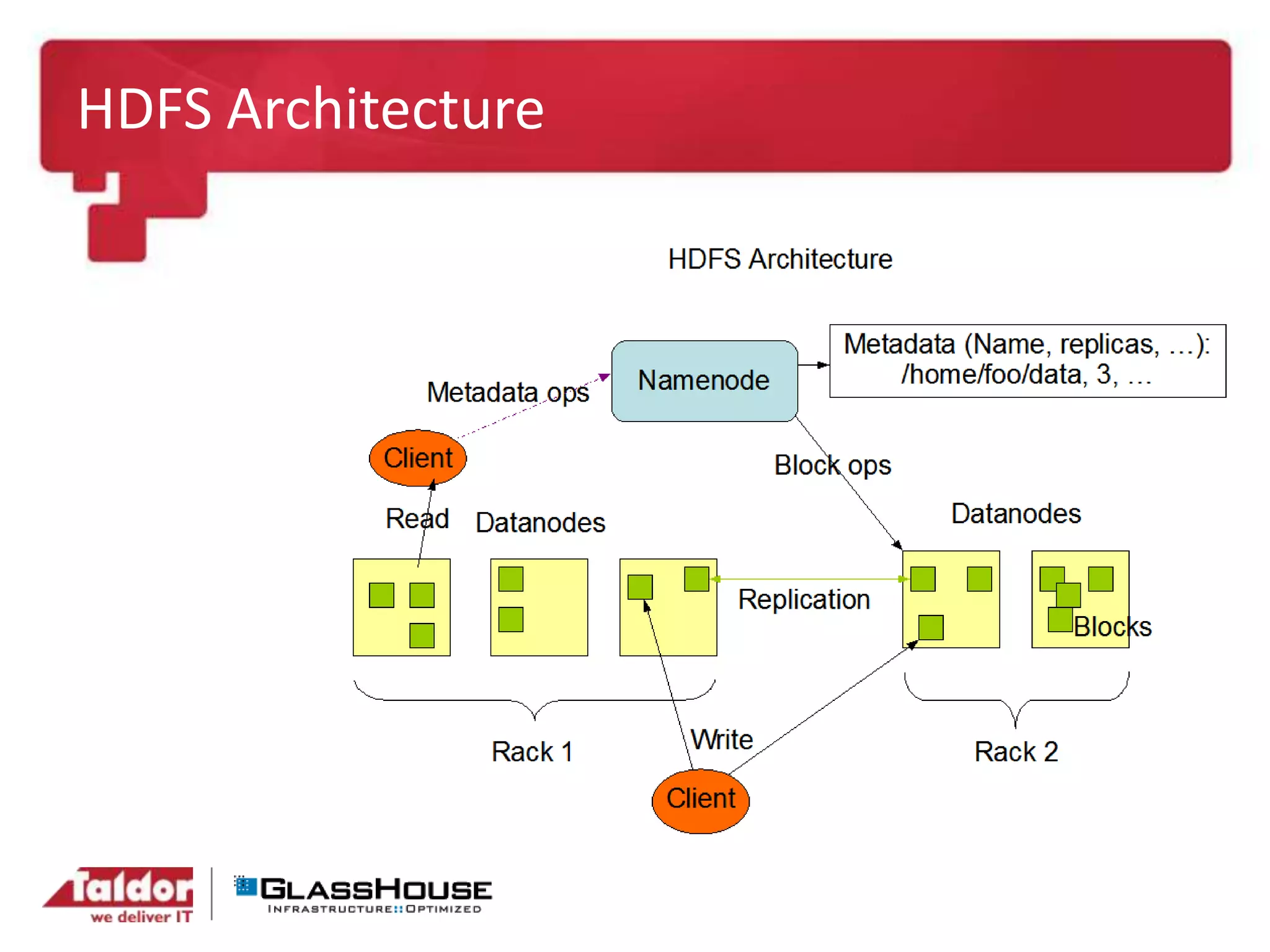


This document discusses big data and Hadoop. It provides an overview of Hadoop, including what it is, how it works, and its core components like HDFS and MapReduce. It also discusses what Hadoop is good for, such as processing large datasets, and what it is not as good for, like low-latency queries or transactional systems. Finally, it covers some best practices for implementing Hadoop, such as infrastructure design and performance considerations.





























































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















