Downloaded 65 times










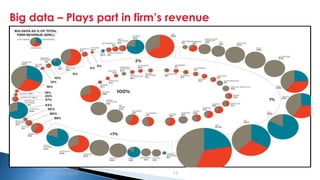


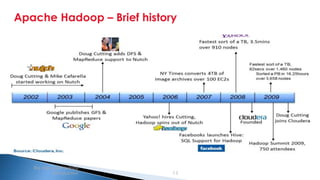


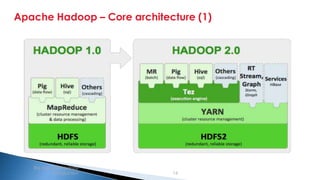

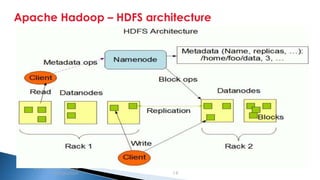
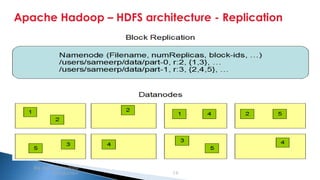
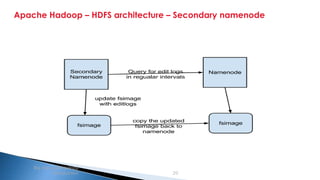
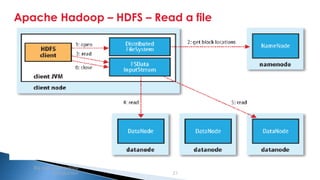
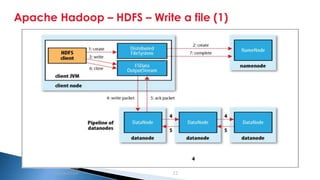
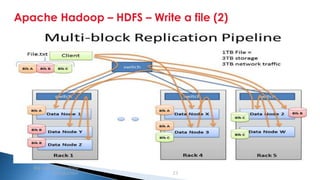
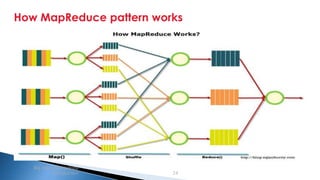
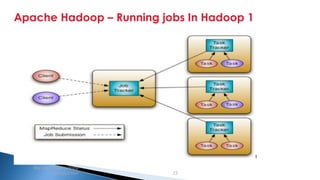
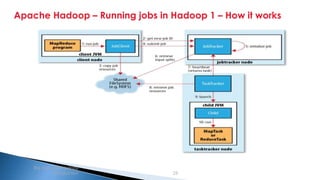
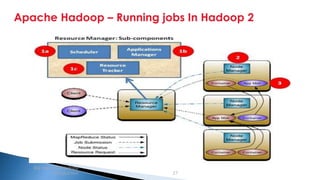
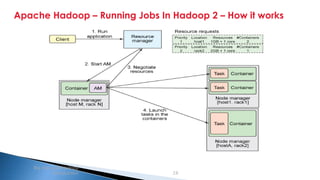



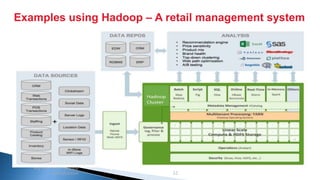
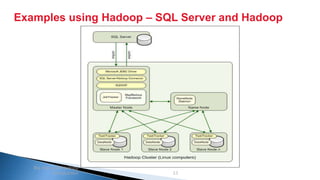
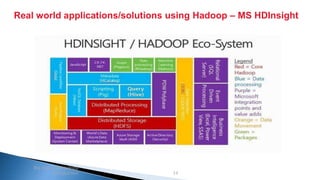






The document provides an introduction to big data and Apache Hadoop. It discusses big data concepts like the 3Vs of volume, variety and velocity. It then describes Apache Hadoop including its core architecture, HDFS, MapReduce and running jobs. Examples of using Hadoop for a retail system and with SQL Server are presented. Real world applications at Microsoft and case studies are reviewed. References for further reading are included at the end.








































































