Downloaded 29 times












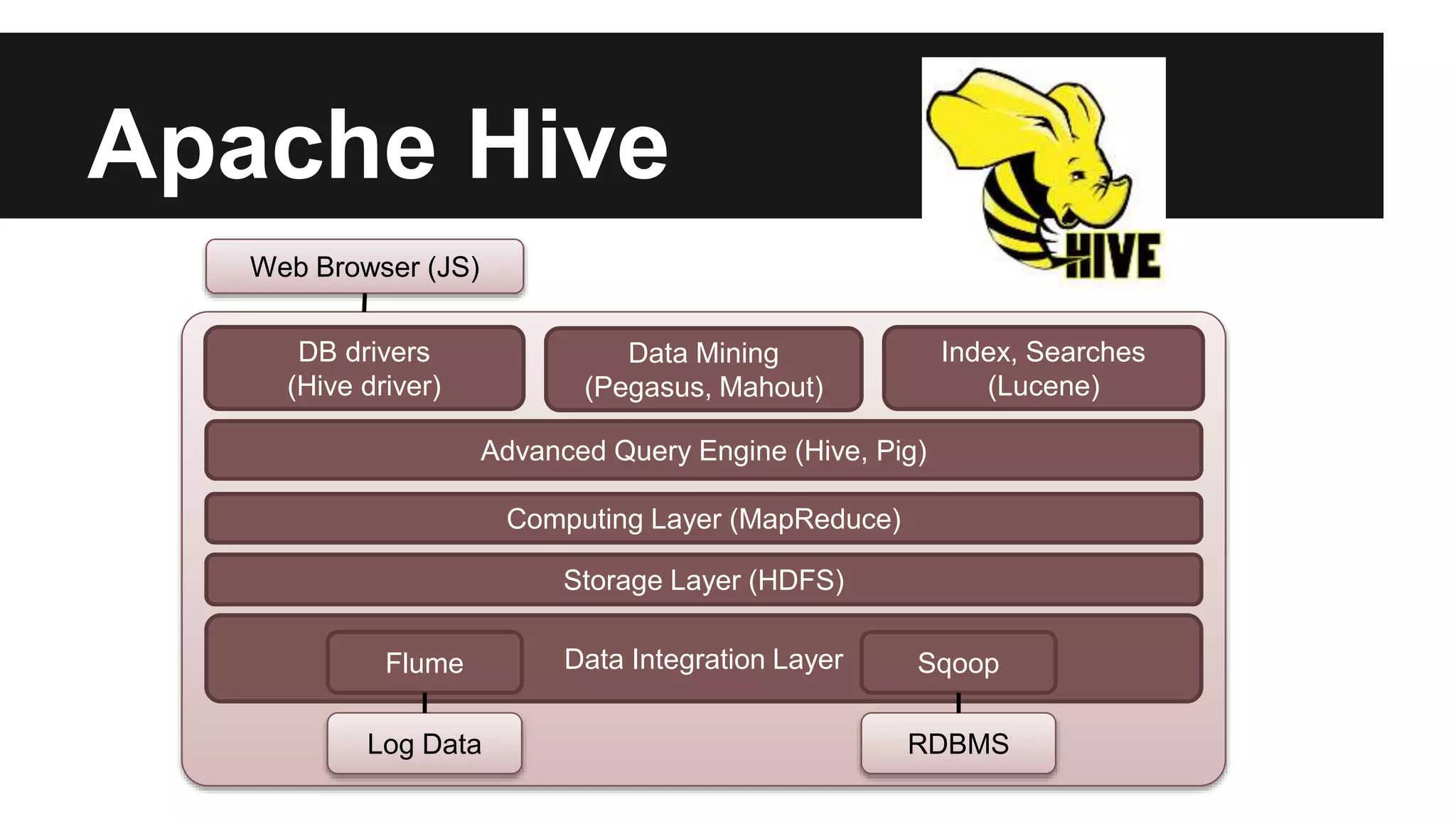
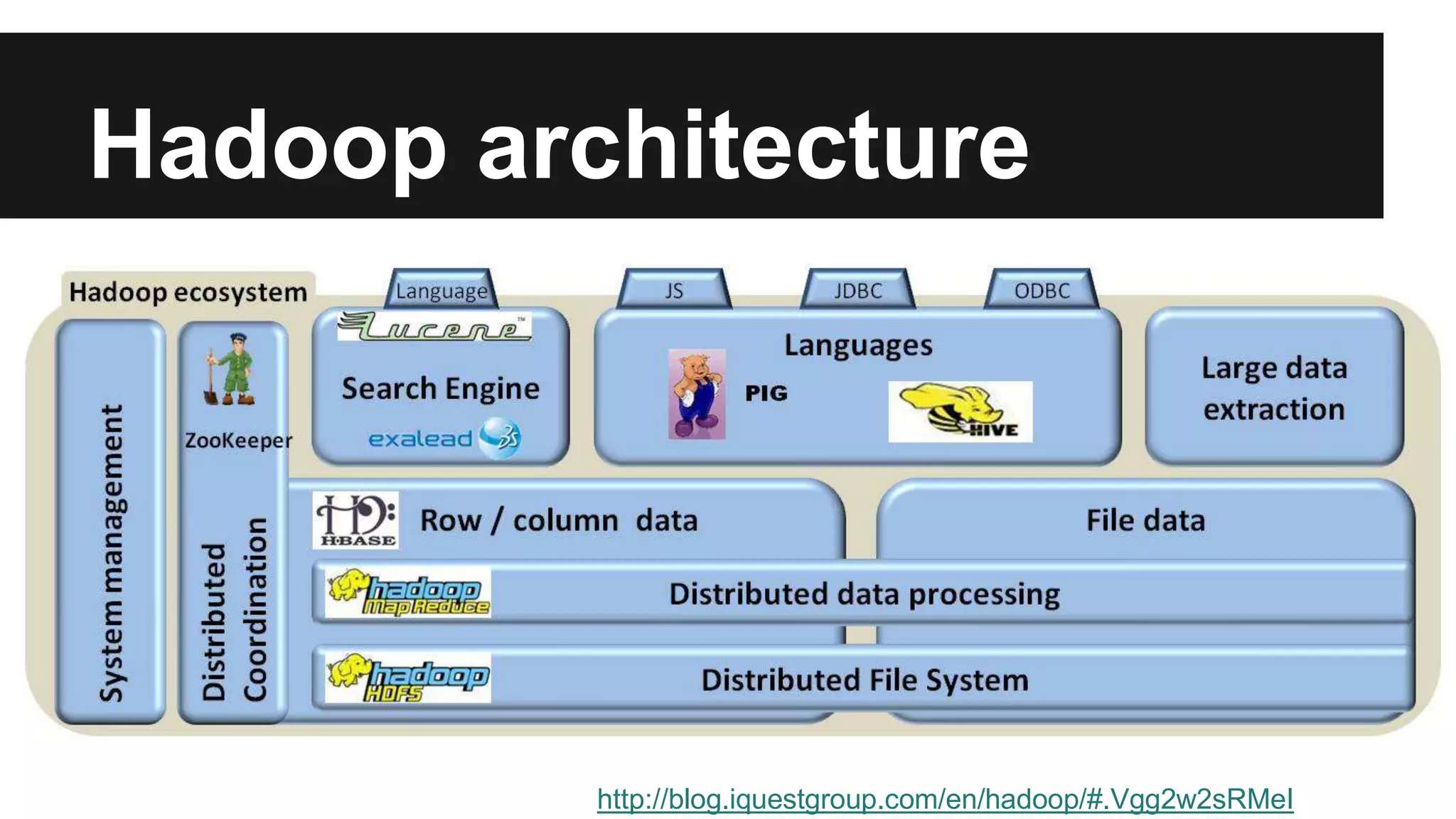
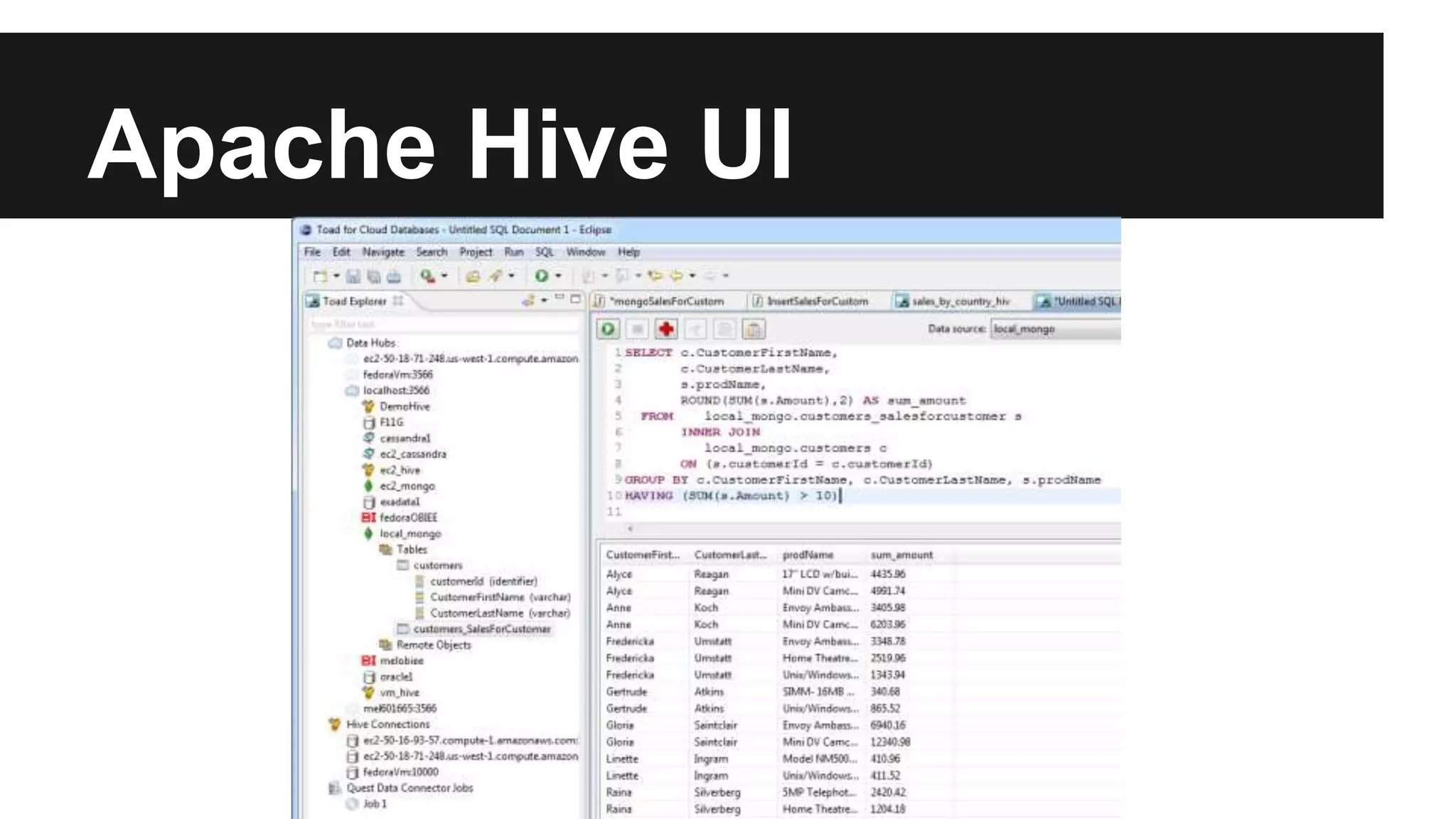

























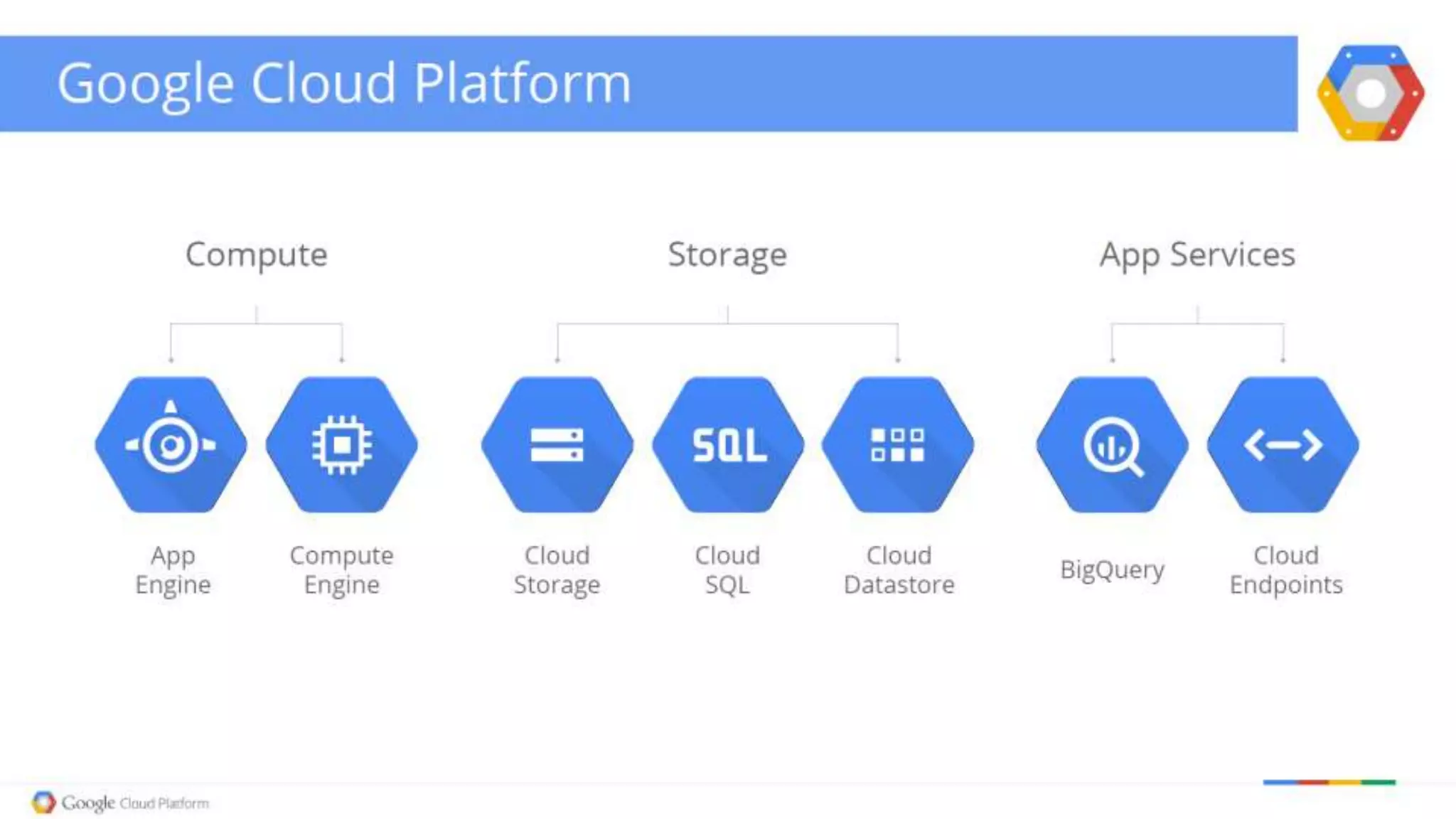

The document discusses the capabilities and architecture of Google BigQuery and Hadoop, emphasizing their roles in handling big data through querying and processing. It contrasts row-based and column-based data storage, explaining their efficiency in OLTP and OLAP scenarios, and details various technologies like MapReduce and Apache Spark that enhance big data processing. Additionally, it provides a brief look at big data statistics and examples from social media and genomic research to illustrate the magnitude and challenges of processing large datasets.




























































































