Downloaded 62 times














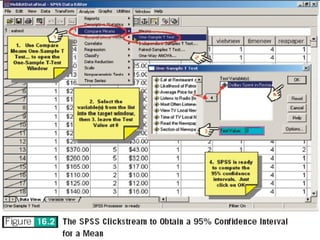
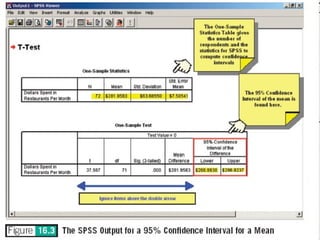







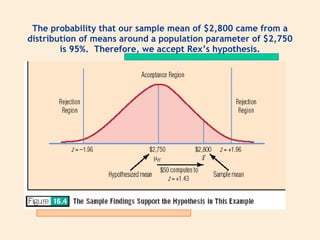


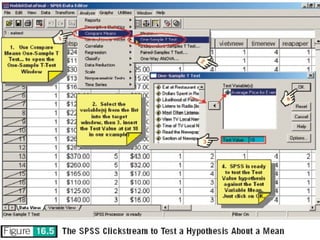
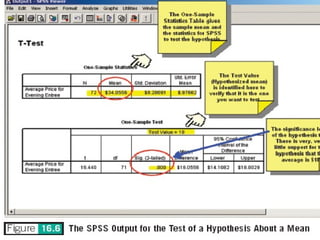



The document discusses parameter estimation and hypothesis testing. Parameter estimation involves using sample statistics to estimate population parameters and determine a confidence interval range within which the population parameter is likely to fall. Hypothesis testing uses sample statistics to determine whether to accept or reject a hypothesized statement about the population parameter. Both techniques allow researchers to generalize findings from a sample to the overall population.










































































