Downloaded 41 times








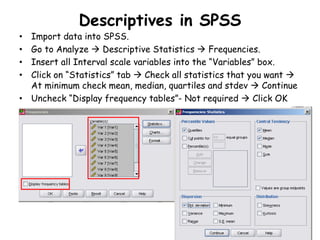
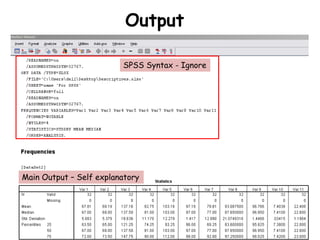
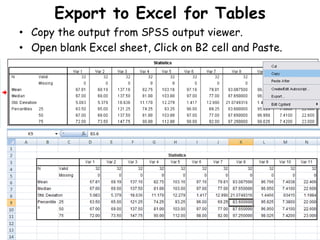

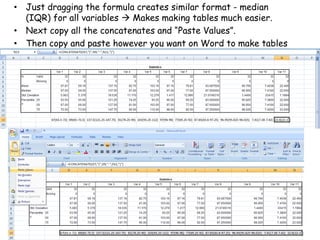

The document discusses various types of data: interval, ordinal, and nominal, along with their statistical measures such as central tendency (mean, median, mode) and dispersion (standard deviation, variance). It also explains concepts like standard error and confidence intervals, emphasizing their importance in estimating population parameters from sample statistics. Additionally, practical guidance for performing descriptive statistics using Excel and SPSS is provided.