Download as PDF, PPTX


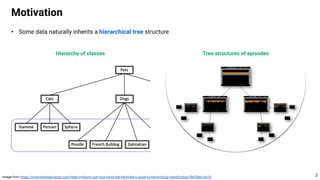
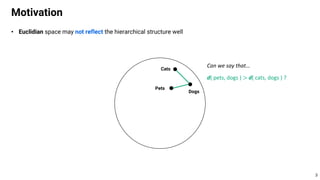
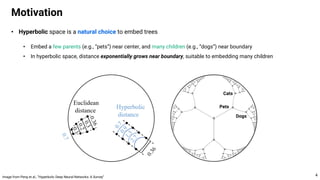



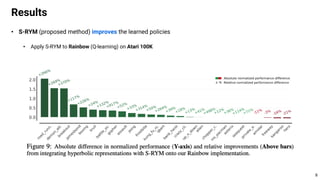




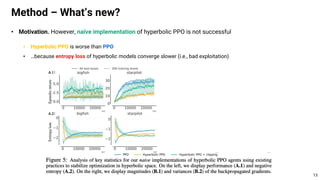
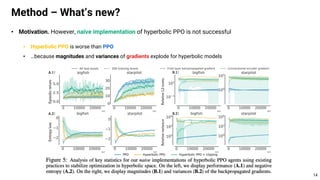
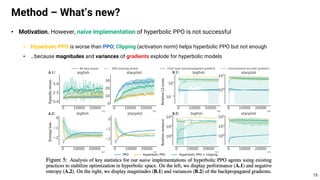


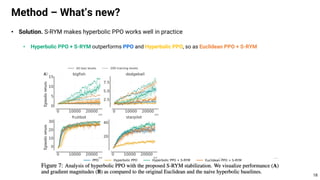
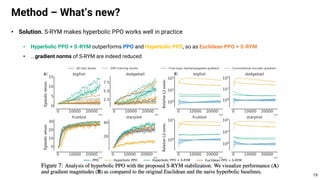






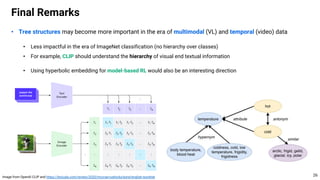


This document proposes using hyperbolic space to embed hierarchical tree structures, like those that can represent sequences of events in reinforcement learning problems. Specifically, it suggests a method called S-RYM that applies spectral normalization to regularize gradients when training deep reinforcement learning agents with hyperbolic embeddings. This stabilization technique allows naive hyperbolic embeddings to outperform standard Euclidean embeddings. It works by reducing gradient norm explosions during training, allowing the entropy loss to converge properly. The document provides technical details on spectral normalization, hyperbolic space representations, and how S-RYM trains deep reinforcement learning agents with stabilized hyperbolic embeddings.



![[DL輪読会]Conditional Neural Processes](https://cdn.slidesharecdn.com/ss_thumbnails/conditionalneuralprocesses-180727001730-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]data2vec: A General Framework for Self-supervised Learning in Speech,...](https://cdn.slidesharecdn.com/ss_thumbnails/220204nonakadl1-220204025334-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Weight Agnostic Neural Networks](https://cdn.slidesharecdn.com/ss_thumbnails/dl0906-190906002243-thumbnail.jpg?width=640&height=640&fit=bounds)













![[ICLR/ICML2019読み会] A Wrapped Normal Distribution on Hyperbolic Space for Grad...](https://cdn.slidesharecdn.com/ss_thumbnails/slidenaganoicmlyomiv2-190721042557-thumbnail.jpg?width=640&height=640&fit=bounds)






















































