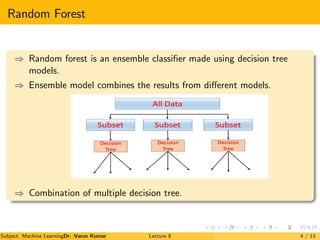
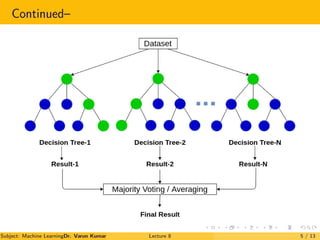
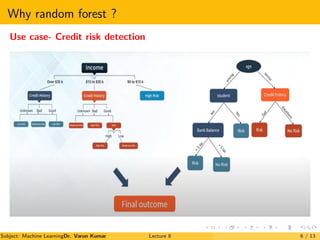
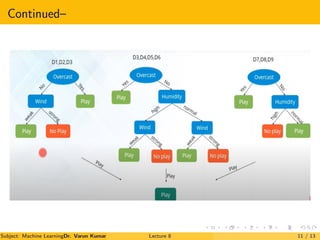
The document is a lecture on Random Forests in machine learning, explaining their use as ensemble classifiers made from decision trees. It discusses their applications, benefits, and the process of how they function, particularly in credit risk detection. Additionally, it outlines the necessary steps for implementing the Random Forest algorithm and includes references for further reading.