Downloaded 107 times


















![Try it out!
From hands-on session: https://www.dropbox.com/s/92sckhnf1hjgjlo/CNN.zip?dl=0
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
…….
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
Optimizer: SGD, RMSprop, Adagrad, Adam…. (https://keras.io/optimizers/)](https://image.slidesharecdn.com/dloptimization-170715221703/85/Optimization-in-Deep-Learning-28-320.jpg)


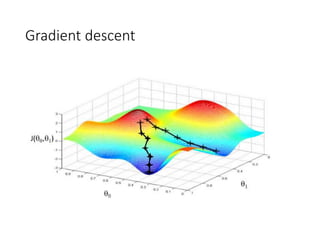
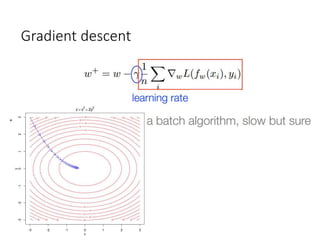
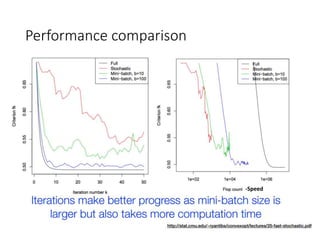
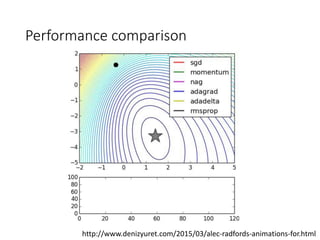
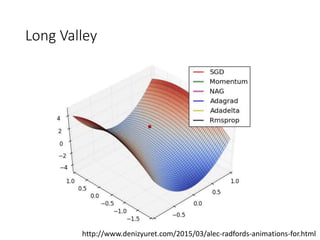
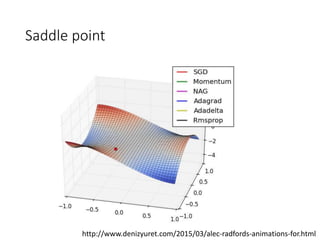
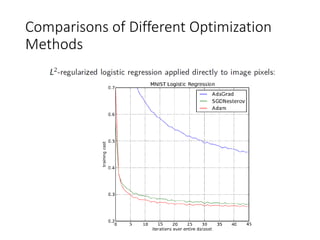
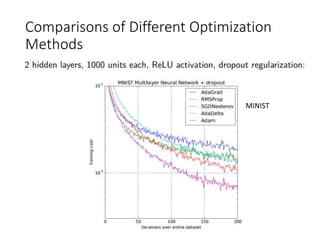
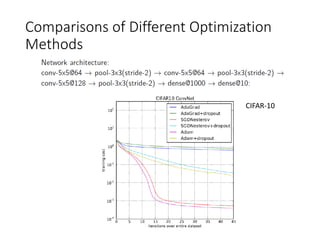
This document summarizes various optimization techniques for deep learning models, including gradient descent, stochastic gradient descent, and variants like momentum, Nesterov's accelerated gradient, AdaGrad, RMSProp, and Adam. It provides an overview of how each technique works and comparisons of their performance on image classification tasks using MNIST and CIFAR-10 datasets. The document concludes by encouraging attendees to try out the different optimization methods in Keras and provides resources for further deep learning topics.





















































































![谷歌留痕技术 [ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130174328-3833018c-thumbnail.jpg?width=640&height=640&fit=bounds)

