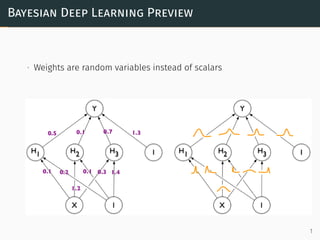
The document discusses Bayesian deep learning, emphasizing the idea that weights are treated as random variables rather than fixed scalars. It covers concepts such as maximum likelihood estimation (MLE), maximum a posteriori estimation (MAP), and various probabilistic methods like Monte Carlo sampling and variational inference for modeling uncertainty. Additionally, it addresses applications of Bayesian deep learning in critical fields such as autonomous driving and medical diagnostics, highlighting the importance of quantifying uncertainty.






![MAP and MLE Estimation
θ∗
MAP = arg min
θ
[− log p(D|θ) − logp(θ)]
θ∗
MLE = arg min
θ
[− log p(D|θ)]
∙ MLE and MAP estimation only estimate a fixed θ
∙ The resulting predictions are a fixed probability value
∙ In reality, θ might be better expressed as a ’distribution’
f(x) = p(y|xθ∗
MAP) ∈ R
8](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-9-320.jpg)
![Bayesian Inference
Eθ[ p(y|x, D) ] =
∫
p(y|x, D, θ)p(θ|D)dθ
∙ Integrating across all probable values of θ (Marginalization)
∙ Solving the integral treats θ as a distribution
∙ For a typical modern deep learning network, θ ∈ R1000000...
∙ Integrating for all possible values of θ is intractable (impossible)
9](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-10-320.jpg)
![Bayesian Methods
Instead of directly solving the integral,
p(y|x, D) =
∫
p(y|x, D, θ)p(θ|D)dθ
we approximate the integral and compute
∙ The expectation E[ p(y|x, D) ]
∙ The variance V[ p(y|x, D) ]
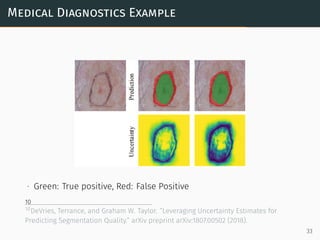
using...
∙ Monte Carlo Sampling
∙ Variational Inference (VI)
10](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-11-320.jpg)
![Output Distribution
Predicted distribution of p(y|x, D) can be visualized as
∙ Grey region is the confidence interval computed from V[ p(y|x, D) ]
∙ Blue line is the mean of the prediction E[ p(y|x, D) ]
11](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-12-320.jpg)







![Variational Inference
KL(q(θ; λ)||p(θ|D))
= −
∫
q(θ; λ) log
p(θ|D)
q(θ; λ)
dθ
= −
∫
q(θ; λ) log p(θ|D)dθ +
∫
q(θ; λ) log q(θ; λ)dθ
= −
∫
q(θ; λ) log
p(θ, D)
p(D)
dθ +
∫
q(θ; λ) log q(θ; λ)dθ
= −
∫
q(θ; λ) log p(θ, D)dθ +
∫
q(θ; λ) log p(D)dθ +
∫
q(θ; λ) log q(θ; λ)dθ
= Eq[− log p(θ, D) + log q(θ; λ)] + log p(D)
where p(D) =
∫
p(θ|D)p(θ)dθ
19](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-20-320.jpg)
![Evidence Lower Bound (ELBO)
Because of the evidence term p(D) is intractable, optimizing the KL
divergence directly is hard.
However By reformulating the problem,
KL(q(θ; λ)||p(θ|D)) = Eq[− log p(θ, D) + log q(θ; p)] + log p(D)
log p(D) = KL(q(θ; λ)||p(θ|D)) − Eq[− log p(θ, D) + log q(θ; λ)]
log p(D) ≥ Eq[log p(θ, D) − log q(θ; λ)]
∵ KL(q(θ, λ)||p(θ|D)) ≥ 0
20](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-21-320.jpg)
![Evidence Lower Bound (ELBO)
maximizeλ L[q(θ; λ)] = Eq[log p(θ, D) − log q(θ; λ)]
∙ Maximizing the evidence lower bound is equivalent of minimizing
the KL divergence
∙ ELBO and KL divergence become equal at the optimum
21](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-22-320.jpg)




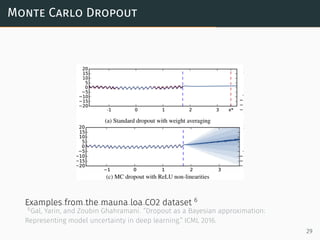
![Dropout As Variational Approximation
Since the ELBO is given as,
maximizeW,p L[q(W; p)]
= Eq[ log p(W, D) − log q(W; p) ]
∝ Eq[ log p(W|D) −
p
2
|| W ||2
2 ]
=
1
N
N∑
i∈D
log p(W|xi, yi) −
p
2σ2
|| W ||2
2
is the optimization objective.
∙ if p approaches 1 or 0, q(W; p) becomes a constant distribution.
26](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-27-320.jpg)
![Monte Carlo Inference
Eθ[ p(y|x, D)] =
∫
p(y|x, D, θ)p(θ)dθ
≈
∫
p(y|x, D, θ)q(θ; p)dθ
= Eq[p(y|x, D)]
≈
1
T
T∑
t
p(y|x, D, θt) θt ∼ q(θ; p)
∙ Prediction is done with dropout turned on and averaging multiple
evaluations.
∙ This is equivalent to monte carlo integration by sampling from the
variational distribution.
27](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-28-320.jpg)
![Monte Carlo Inference
Vθ[ p(y|x, D)] ≈
1
S
S∑
s
( p(y|x, D, θs) − Eθ[p(y|x, D)] )2
Uncertainty is the variance of the samples taken from the variational
distribution.
28](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-29-320.jpg)








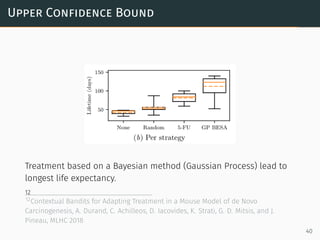
![Upper Confidence Bound
Treatment selection policy
at = arg max
a∈A
[µa(xt) + βσ2
a(xt)]
Quality measure
R(T) =
T∑
t
[max
a∈A
µa(xt) − µa(xt)]
where A is the set of possible treatments
µ(x), σ2
(x) is the predicted mean, variance at x
39](https://image.slidesharecdn.com/bayesiandeeplearning-190407061823/85/Bayesian-Deep-Learning-40-320.jpg)