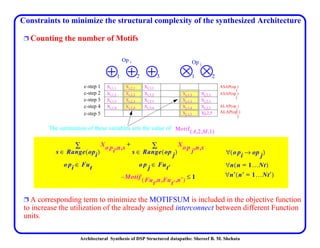
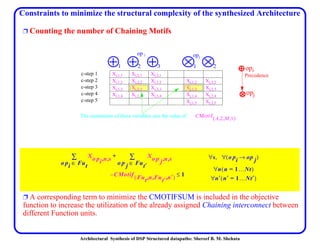
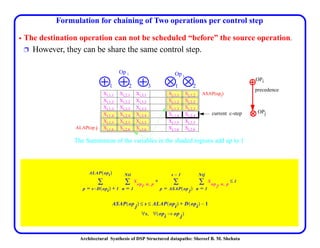
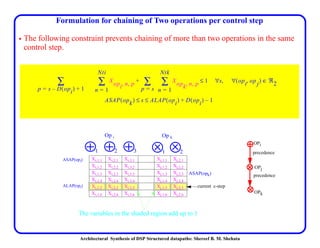
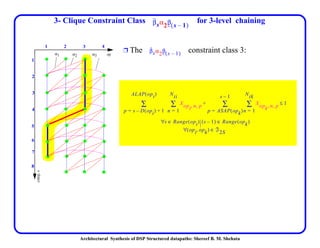
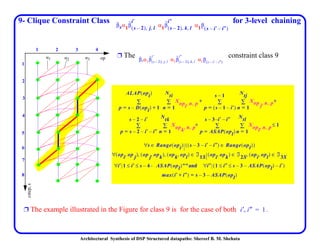
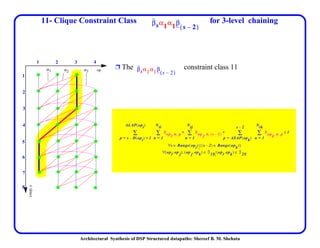
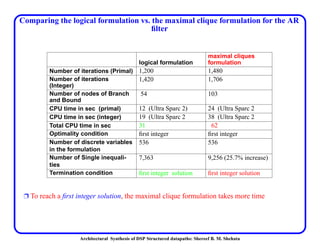
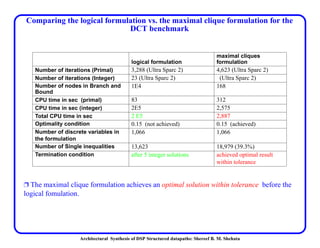
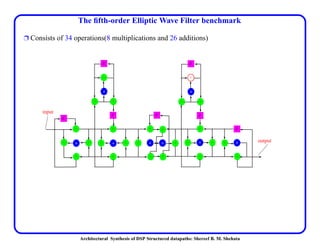
This document discusses architectural synthesis of DSP structured datapaths. It provides an overview of the architectural level synthesis problem and subtasks like scheduling, binding, and architecture optimization. The document describes using novel mathematical programming formulations to optimize performance and structural complexity for DSP synthesis. It also discusses techniques to improve the solution time for integer linear programming formulations, and provides results for typical high-level synthesis benchmarks.
















































































![Architectural Synthesis of DSP Structured datapaths: Shereef B. M. Shehata
Convex Bipartite Graph. Matching
Ë This bipartite graph corresponds to the multiply operations of the EWF benchmark. The
function unit resources are 1 Multiplier.
FU_IOEI
[3,7]
[3,7]
[8,11]
[8,11]
[12,15]
[13,15]
[13,15]
[14,15]
[3,6]
[4,7]
[8,10]
[9,11]
[12,12]
[13,13]
[14,14]
[15,15]
InitialOperation
17
18
8
29
33
24
4
12
12
34
56
78
9
10
11
12](https://image.slidesharecdn.com/3a66acca-2ac3-47ac-8bec-3b5d27f77bb6-151102181837-lva1-app6892/85/Architectural_Synthesis_for_DSP_Structured_Datapaths-98-320.jpg)




![Architectural Synthesis of DSP Structured datapaths: Shereef B. M. Shehata
Effect of Chaining and Pipelining FUs On EWF Datapath
Performance
Design
Space
CSteps, T Resources Pipeline level Chaining Cost T(ns)
1 27 1+, 1* 2-stages yes 140 2158
2-a (ours) 17 2+, 1 *,1b 2-stages NO 160 1275
2-b [13] 17 2+, 1 * 2-stages NO 180 1275
3 10 3+, 1* No-pipe yes 195 1650
4 12 3+, 1* 2-stages yes 185 996
5 11 3+, 1* 2-stages yes 190 935
6 11 3+, 1* 2-stages yes 195 913
7 17 3+, 1* 4-stages yes 225 731
8 19 3+, 1* 4-stages yes 205 836
9 17 3+, 1* 4-stages yes 210 765
10 18 3+, 1* 4-stages yes 215 774
11 17 3+, 1* 4-stages yes 220 765](https://image.slidesharecdn.com/3a66acca-2ac3-47ac-8bec-3b5d27f77bb6-151102181837-lva1-app6892/85/Architectural_Synthesis_for_DSP_Structured_Datapaths-104-320.jpg)















![Architectural Synthesis of DSP Structured datapaths: Shereef B. M. Shehata
The Discrete Cosine Transform Benchmark
Ours PSGA_Syn,
[69]
Tool [23]
Chaudhuri/
Walker
SALSA[34]
(Chain)
SALSA[34]
Resources 2*, 4+ 3*,3+ 3*, 4+ 2*, 4+ 2*,4+
# mux inputs 28 NA NA NA 30
# registers 11 14 NA 15 13
Clock (ns) 45 120a
a. This tool does not use chaining nor pipelining for the DCT.
65b
b. The tool described in [23], does not use chaining.
135c
c. The level of chaining is not reported in [34]
65d
d. SALSA[34], does not determine the clock duration of the total execution. However, we have
used the same library for comparison
# csteps 11 18 9 8 11
Totexec(ns) 495 2160 585 1080 715](https://image.slidesharecdn.com/3a66acca-2ac3-47ac-8bec-3b5d27f77bb6-151102181837-lva1-app6892/85/Architectural_Synthesis_for_DSP_Structured_Datapaths-120-320.jpg)
![Architectural Synthesis of DSP Structured datapaths: Shereef B. M. Shehata
The Discrete Cosine Transform Benchmark
Ours PSGA_Syn
Tool in [69]
SALSA
(Chain)
[34]
OSTA no-Chain
[70]
Resources 1*, 3+ 3*,3+ 2*, 4+ 3*, 6+
# mux i/p 24 NA NA 38
# registers 10 14 15 24
Clock (ns) 45 120 130 120
# csteps, T 19 18 8 9
Totexec(ns) 855 2160 1080 1080](https://image.slidesharecdn.com/3a66acca-2ac3-47ac-8bec-3b5d27f77bb6-151102181837-lva1-app6892/85/Architectural_Synthesis_for_DSP_Structured_Datapaths-121-320.jpg)















































































































