Download as PDF, PPTX














![®
© 2014 MapR Technologies 18
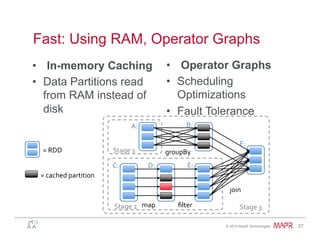
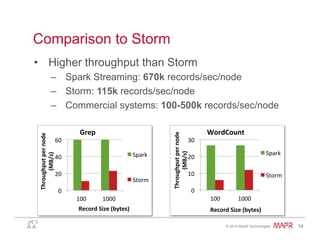
Easy: Example – Word Count
• Spark• Hadoop MapReduce
public static class WordCountMapClass extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class WorkdCountReduce extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
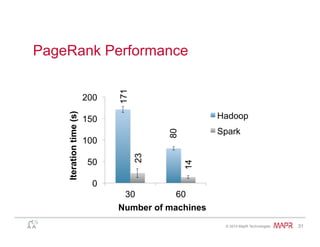
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
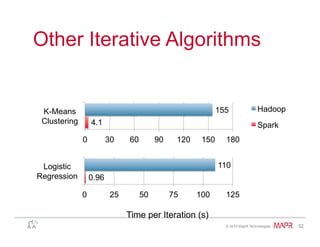
}
val spark = new SparkContext(master, appName, [sparkHome], [jars])
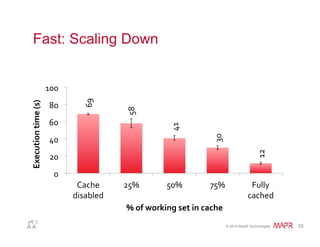
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-18-320.jpg)
![®
© 2014 MapR Technologies 19
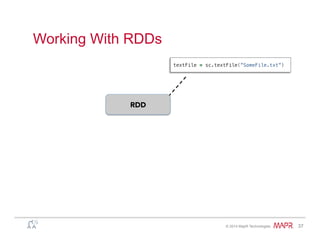
Easy: Example – Word Count
• Spark• Hadoop MapReduce
public static class WordCountMapClass extends MapReduceBase
implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class WorkdCountReduce extends MapReduceBase
implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
val spark = new SparkContext(master, appName, [sparkHome], [jars])
val file = spark.textFile("hdfs://...")
val counts = file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://...")](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-19-320.jpg)







![®
© 2014 MapR Technologies 29
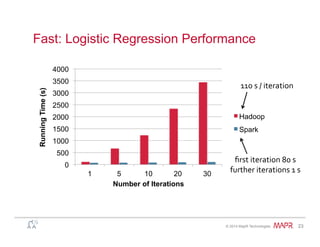
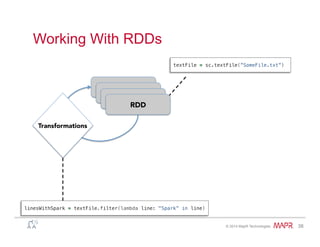
Easy: Fault Recovery
RDDs track lineage information that can be used to
efficiently recompute lost data
msgs = textFile.filter(lambda s: s.startsWith(“ERROR”))
.map(lambda s: s.split(“t”)[2])
HDFS File Filtered RDD Mapped RDD
filter
(func
=
startsWith(…))
map
(func
=
split(...))](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-29-320.jpg)







![®
© 2014 MapR Technologies 47
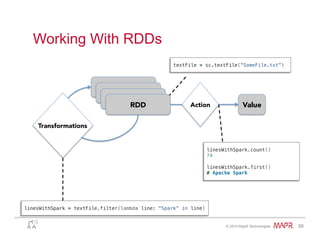
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
Driver
messages.filter(lambda s: “mysql” in s).count()](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-47-320.jpg)
![®
© 2014 MapR Technologies 48
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
Driver
messages.filter(lambda s: “mysql” in s).count()
Action](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-48-320.jpg)
![®
© 2014 MapR Technologies 49
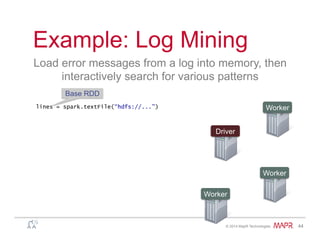
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
Driver
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-49-320.jpg)
![®
© 2014 MapR Technologies 50
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
tasks
tasks
tasks](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-50-320.jpg)
![®
© 2014 MapR Technologies 51
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Read
HDFS
Block
Read
HDFS
Block
Read
HDFS
Block](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-51-320.jpg)
![®
© 2014 MapR Technologies 52
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
Process
& Cache
Data
Process
& Cache
Data
Process
& Cache
Data](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-52-320.jpg)
![®
© 2014 MapR Technologies 53
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
results
results
results](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-53-320.jpg)
![®
© 2014 MapR Technologies 54
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Driver
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-54-320.jpg)
![®
© 2014 MapR Technologies 55
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()
tasks
tasks
tasks
Driver](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-55-320.jpg)
![®
© 2014 MapR Technologies 56
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()
Driver
Process
from
Cache
Process
from
Cache
Process
from
Cache](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-56-320.jpg)
![®
© 2014 MapR Technologies 57
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()
Driver
results
results
results](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-57-320.jpg)
![®
© 2014 MapR Technologies 58
Example: Log Mining
Load error messages from a log into memory, then
interactively search for various patterns
lines = spark.textFile(“hdfs://...”)
errors = lines.filter(lambda s: s.startswith(“ERROR”))
messages = errors.map(lambda s: s.split(“t”)[2])
messages.cache()
Worker
Worker
Worker
messages.filter(lambda s: “mysql” in s).count()
Block 1
Block 2
Block 3
Cache 1
Cache 2
Cache 3
messages.filter(lambda s: “php” in s).count()
Driver
Cache your data è Faster Results
Full-text search of Wikipedia
• 60GB on 20 EC2 machines
• 0.5 sec from cache vs. 20s for on-disk](https://image.slidesharecdn.com/spark-overview-june2014-140711131800-phpapp01/85/Apache-Spark-Hadoop-58-320.jpg)












The document provides an overview of Apache Spark and its comparison with MapReduce, highlighting its advantages such as ease of use, performance, and in-memory data processing capabilities. It introduces key concepts like Resilient Distributed Datasets (RDDs), fault tolerance, and the platform's support for multiple programming languages. Examples of practical applications, such as word counting and log mining, demonstrate Spark's functionality and efficiency in handling big data tasks.




































































































