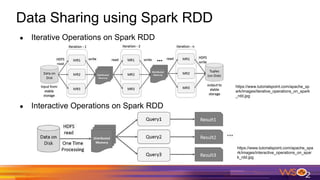
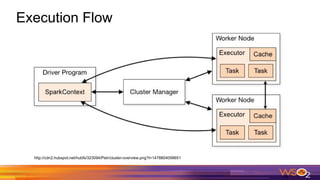
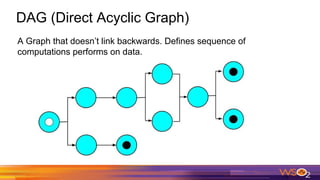
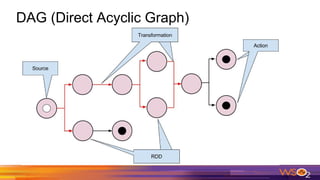
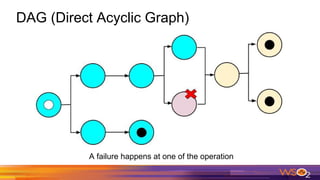
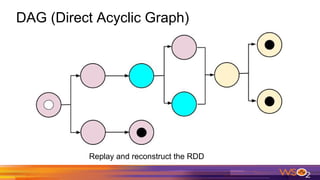
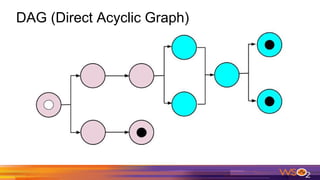
This document provides an overview of Spark driven big data analytics. It begins by defining big data and its characteristics. It then discusses the challenges of traditional analytics on big data and how Apache Spark addresses these challenges. Spark improves on MapReduce by allowing distributed datasets to be kept in memory across clusters. This enables faster iterative and interactive processing. The document outlines Spark's architecture including its core components like RDDs, transformations, actions and DAG execution model. It provides examples of writing Spark applications in Java and Java 8 to perform common analytics tasks like word count.




























![Writing Analytics Applications
1. SparkConf conf = new SparkConf().setMaster("local").setAppName("Word Count App");
2. JavaSparkContext sc = new JavaSparkContext(conf);
3.
4. JavaRDD<String> lines = spark.read().textFile(args[0]).javaRDD();
5.
6. JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
7. @Override
8. public Iterator<String> call(String s) {
9. return Arrays.asList(s.split(" ")).iterator();
10. }
11. });
12.
13. JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
14. @Override
15. public Tuple2<String, Integer> call(String s) {
16. return new Tuple2<>(s, 1);
17. }
18. });
19.
20. JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
21. @Override
22. public Integer call(Integer i1, Integer i2) {
23. return i1 + i2;
24. }
25. });
26.
27. List<Tuple2<String, Integer>> output = counts.collect();
28 for (Tuple2<?,?> tuple : output) {
29 System.out.println(tuple._1() + ": " + tuple._2());
30. }](https://image.slidesharecdn.com/sparkdrivenbigdataanalytics-161111112000/85/Spark-Driven-Big-Data-Analytics-39-320.jpg)
![Writing Analytics Applications (contd.)
SparkConf conf = new SparkConf().setMaster("local").setAppName("Word Count App");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = spark.read().textFile(args[0]).javaRDD();
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) {
return Arrays.asList(s.split(" ")).iterator();
}
});
JavaPairRDD<String, Integer> ones = words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<>(s, 1);
}
});
JavaPairRDD<String, Integer> counts = ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List<Tuple2<String, Integer>> output = counts.collect();
for (Tuple2<?,?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
Green colored codes are not executing on the driver. Those are executing on another node.](https://image.slidesharecdn.com/sparkdrivenbigdataanalytics-161111112000/85/Spark-Driven-Big-Data-Analytics-40-320.jpg)
![Writing Analytics Applications (contd.)
SparkConf conf = new SparkConf().setMaster("local").setAppName("Word Count App");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = spark.read().textFile(args[0]).javaRDD();
JavaRDD<String> words =lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) {
return Arrays.asList(s.split(" ")).iterator();
}
});
JavaPairRDD<String, Integer> ones =words.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) {
return new Tuple2<>(s, 1);
}
});
JavaPairRDD<String, Integer> counts =ones.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List<Tuple2<String, Integer>> output =counts.collect();
for (Tuple2<?,?> tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
Blue colored codes are transformations. Red colored code is an action. Green colored code is stuffs
that happens locally (not Spark related things)](https://image.slidesharecdn.com/sparkdrivenbigdataanalytics-161111112000/85/Spark-Driven-Big-Data-Analytics-41-320.jpg)




































![[Infographic] How will Internet of Things (IoT) change the world as we know it?](https://cdn.slidesharecdn.com/ss_thumbnails/iotinfographicv3-160309101328-thumbnail.jpg?width=640&height=640&fit=bounds)































![Hacking-Uncovered-How-People-Get-Hacked-and-How-to-Stay-Safe[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/hacking-uncovered-how-people-get-hacked-and-how-to-stay-safe1-260130170011-4883a9c7-thumbnail.jpg?width=640&height=640&fit=bounds)










