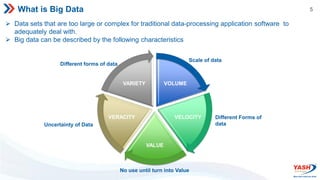
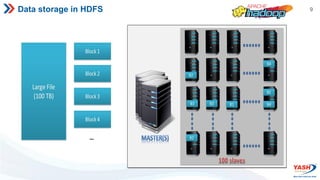
The document provides an overview of Apache Spark, including what it is, its ecosystem, features, and architecture. Some key points:
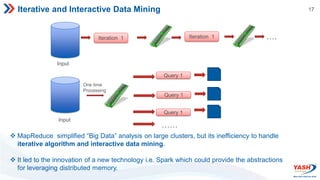
- Apache Spark is an open-source cluster computing framework for large-scale data processing. It is up to 100x faster than Hadoop for iterative/interactive algorithms.
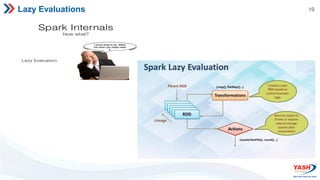
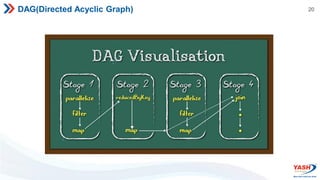
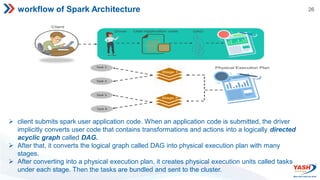
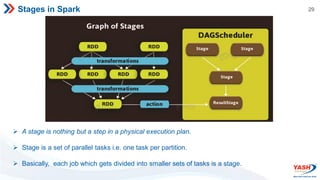
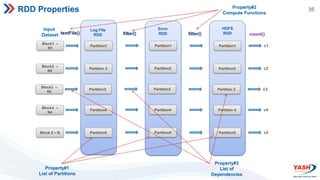
- Spark features include its RDD abstraction, lazy evaluation, and use of DAGs to optimize performance. It supports Scala, Java, Python, and R.
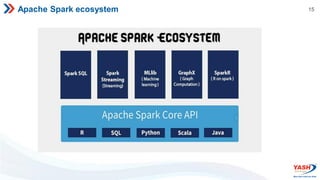
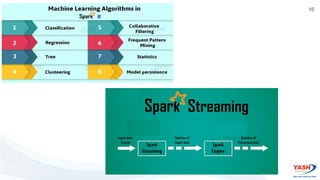
- The Spark ecosystem includes tools like Spark SQL, MLlib, GraphX, and Spark Streaming. It can run on Hadoop YARN, Mesos, or in standalone mode.
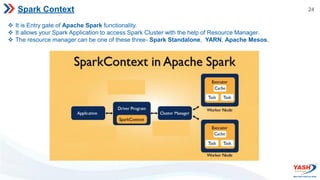
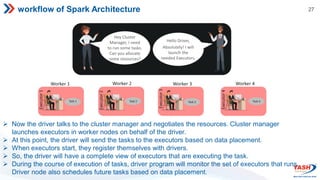
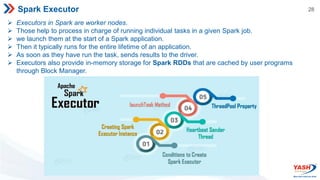
- Spark's architecture includes the SparkContext,