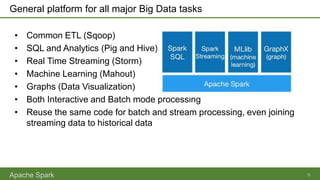
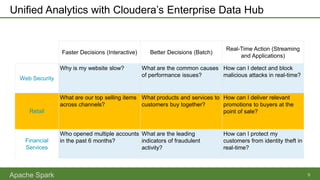
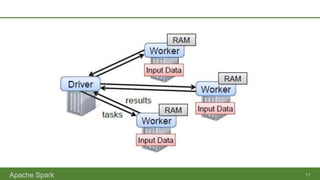
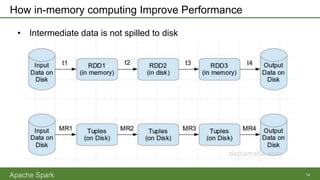
Apache Spark is an open-source parallel data processing framework that supports all major big data environments, enabling both batch and real-time analytics with enhanced speed and ease of use. It features resilient distributed datasets (RDDs) that allow for fault-tolerant data processing and in-memory computing, making it significantly faster than Hadoop MapReduce. Spark can be used with various programming languages and integrations, catering to a wide range of data sources and analytical tasks.



















































![RAHUL[1]](https://cdn.slidesharecdn.com/ss_thumbnails/8964189b-693b-49e2-86f6-4164bc4ccd80-150613172202-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)










































