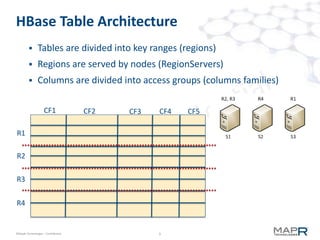
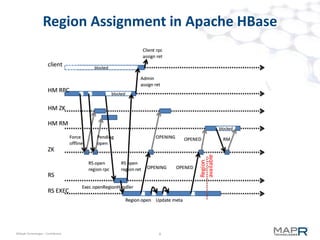
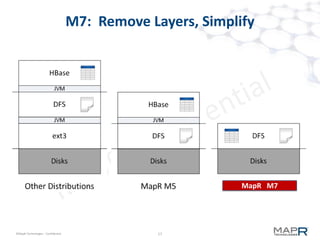
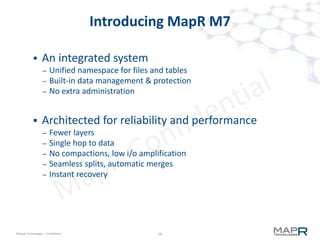
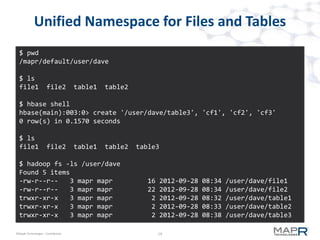
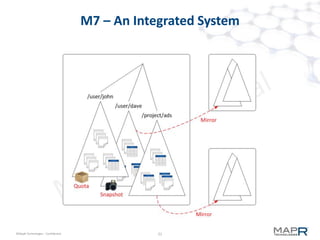
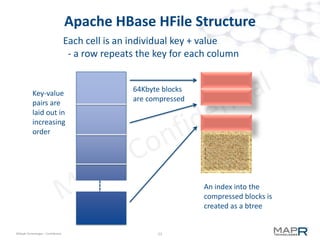
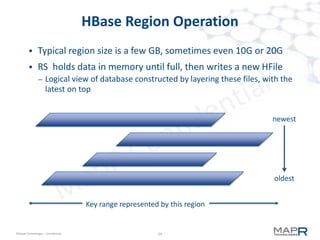
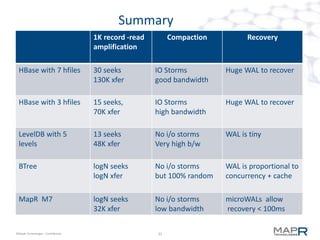
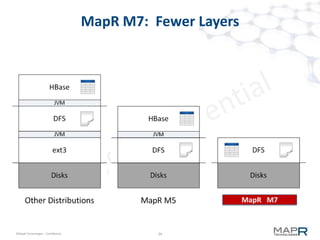
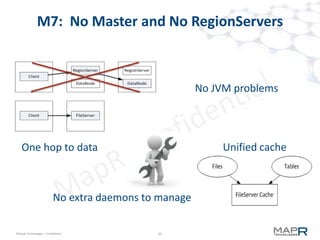
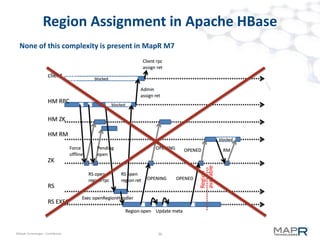
The document provides an overview of MapR M7, an integrated system for structured and unstructured data. M7 combines aspects of LSM trees and B-trees to provide faster reads and writes compared to Apache HBase. It achieves instant recovery from failures through its use of micro write-ahead logs and parallel region recovery. Benchmark results show MapR M7 providing 5-11x faster performance than HBase for common operations like reads, updates, and scans.