Download as PDF, PPTX







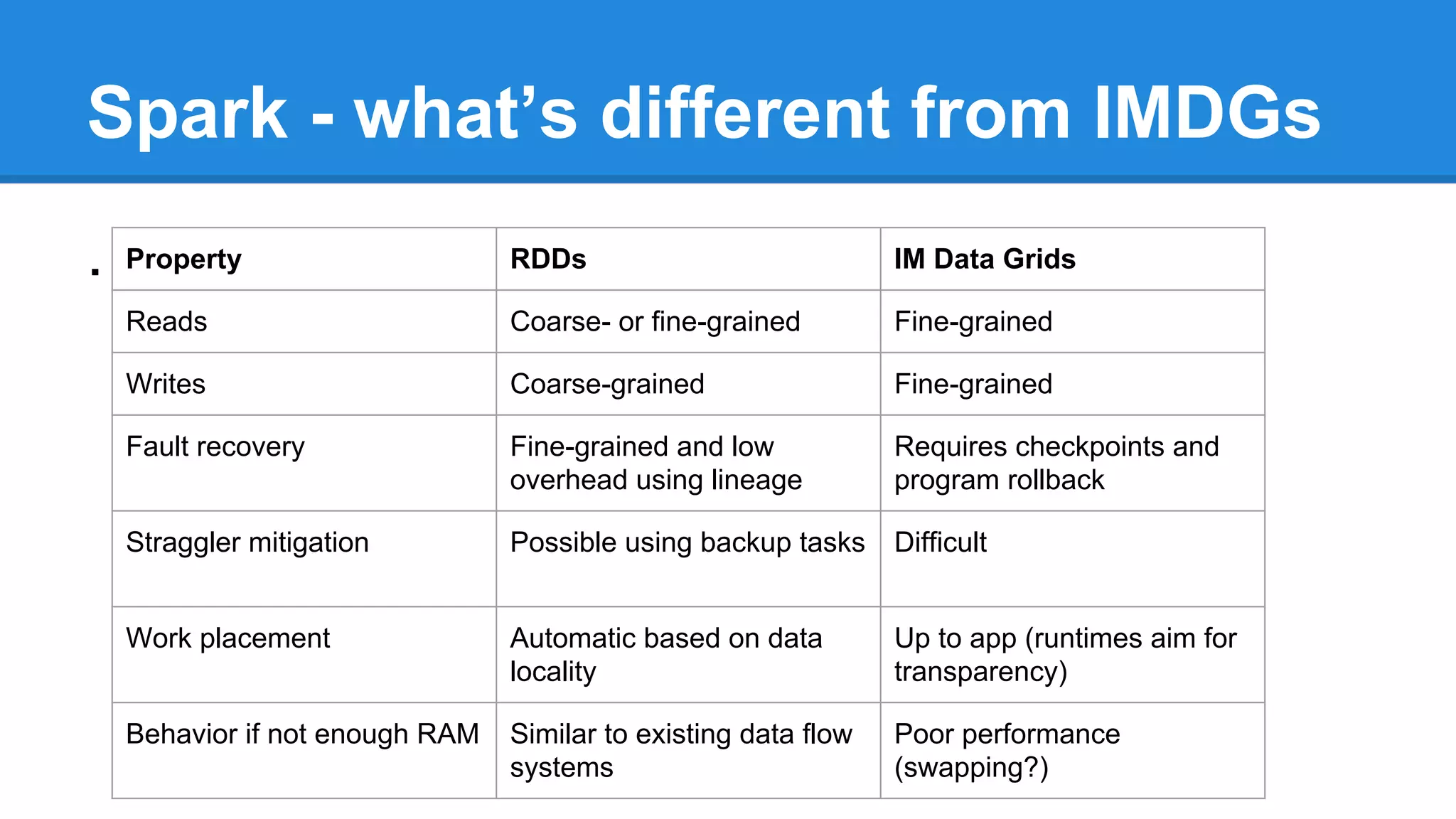









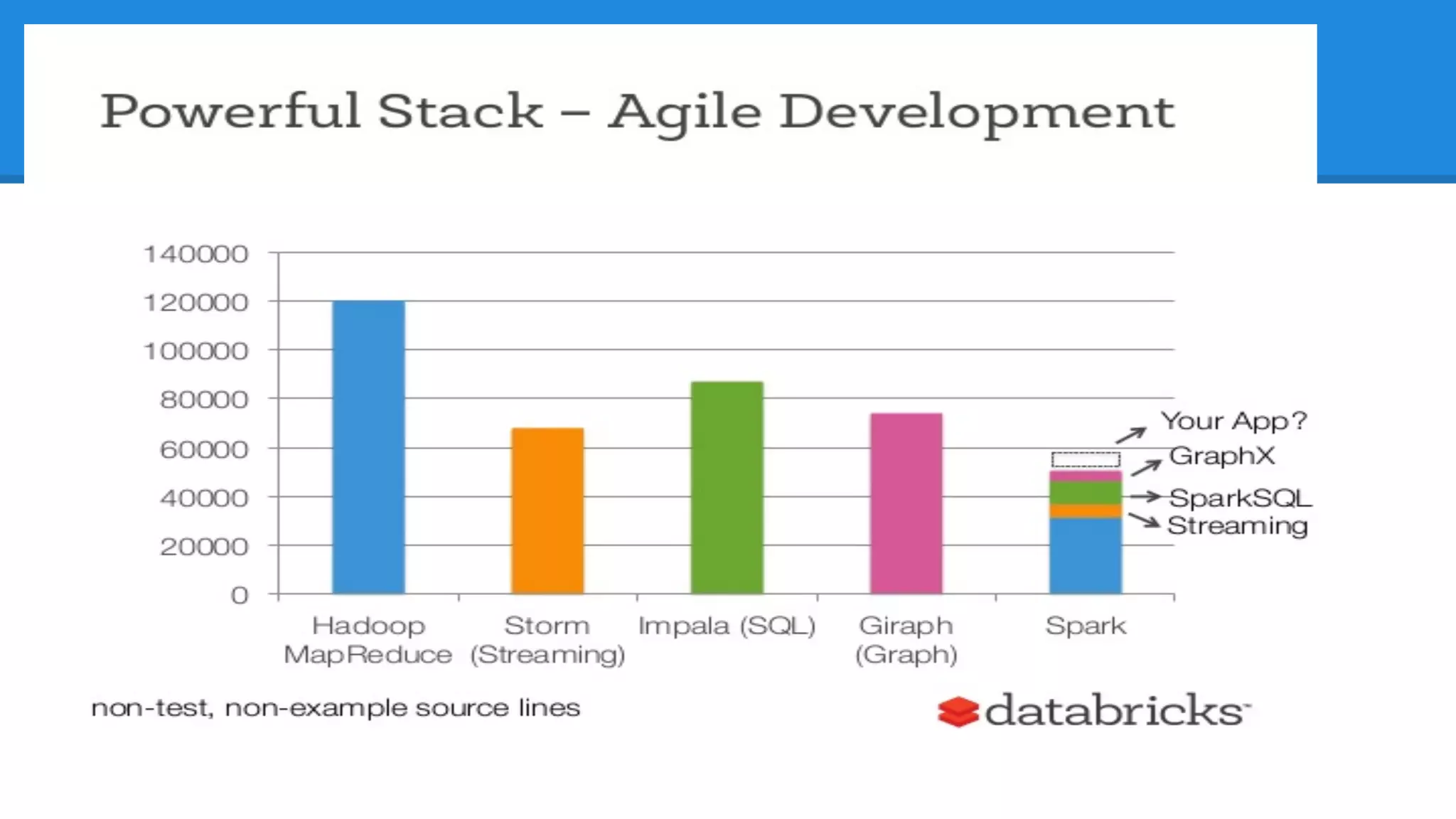


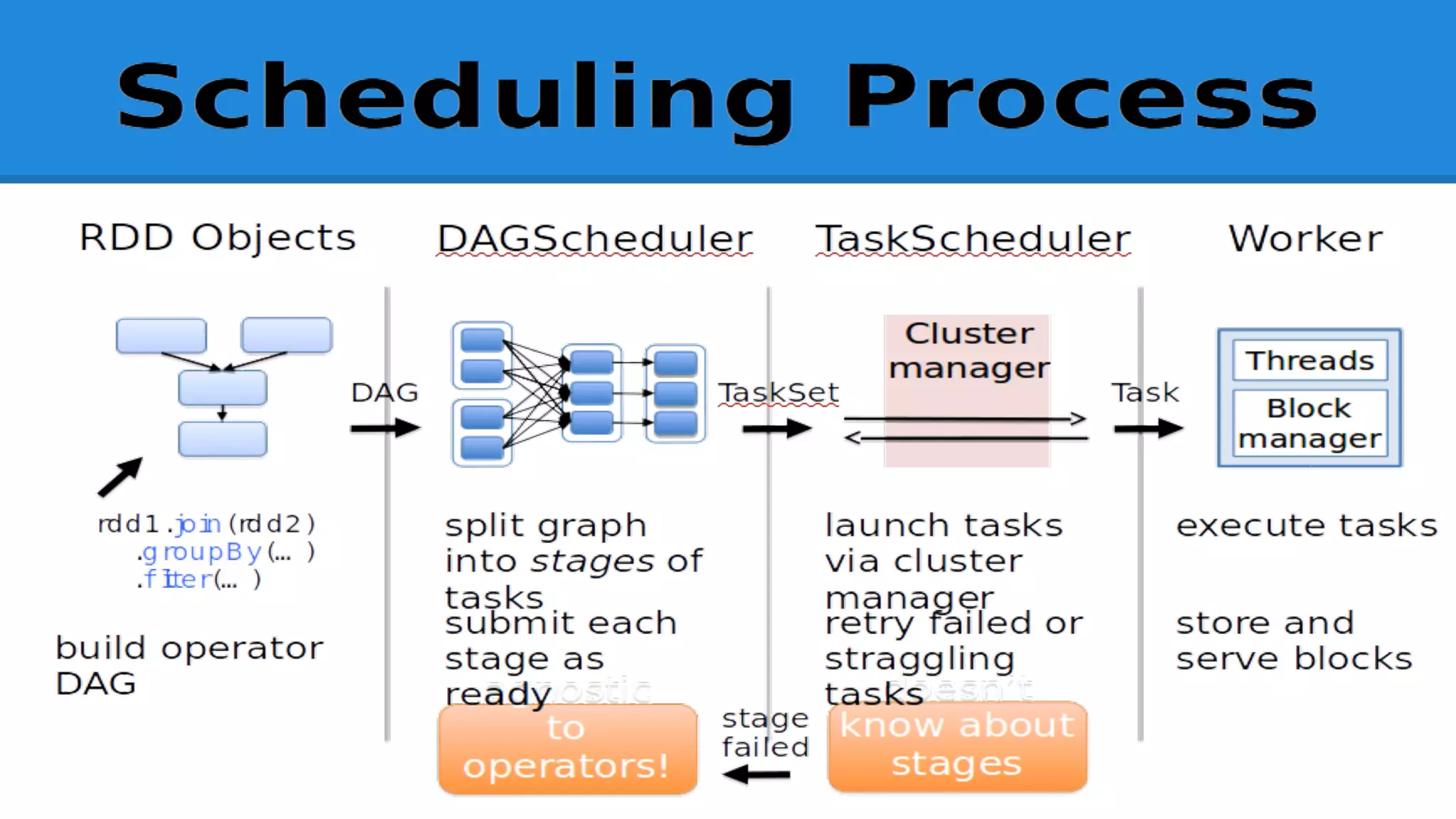







The document discusses the core components and advantages of Apache Spark, particularly focusing on Resilient Distributed Datasets (RDDs) and their fault tolerance capabilities. It highlights Spark's architecture compared to in-memory data grids, emphasizing the benefits of immutability, partitioning, and efficient transformations. Furthermore, it introduces future developments such as Project Tungsten and DataFrames aimed at enhancing performance and code efficiency.










































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)












