Downloaded 51 times





















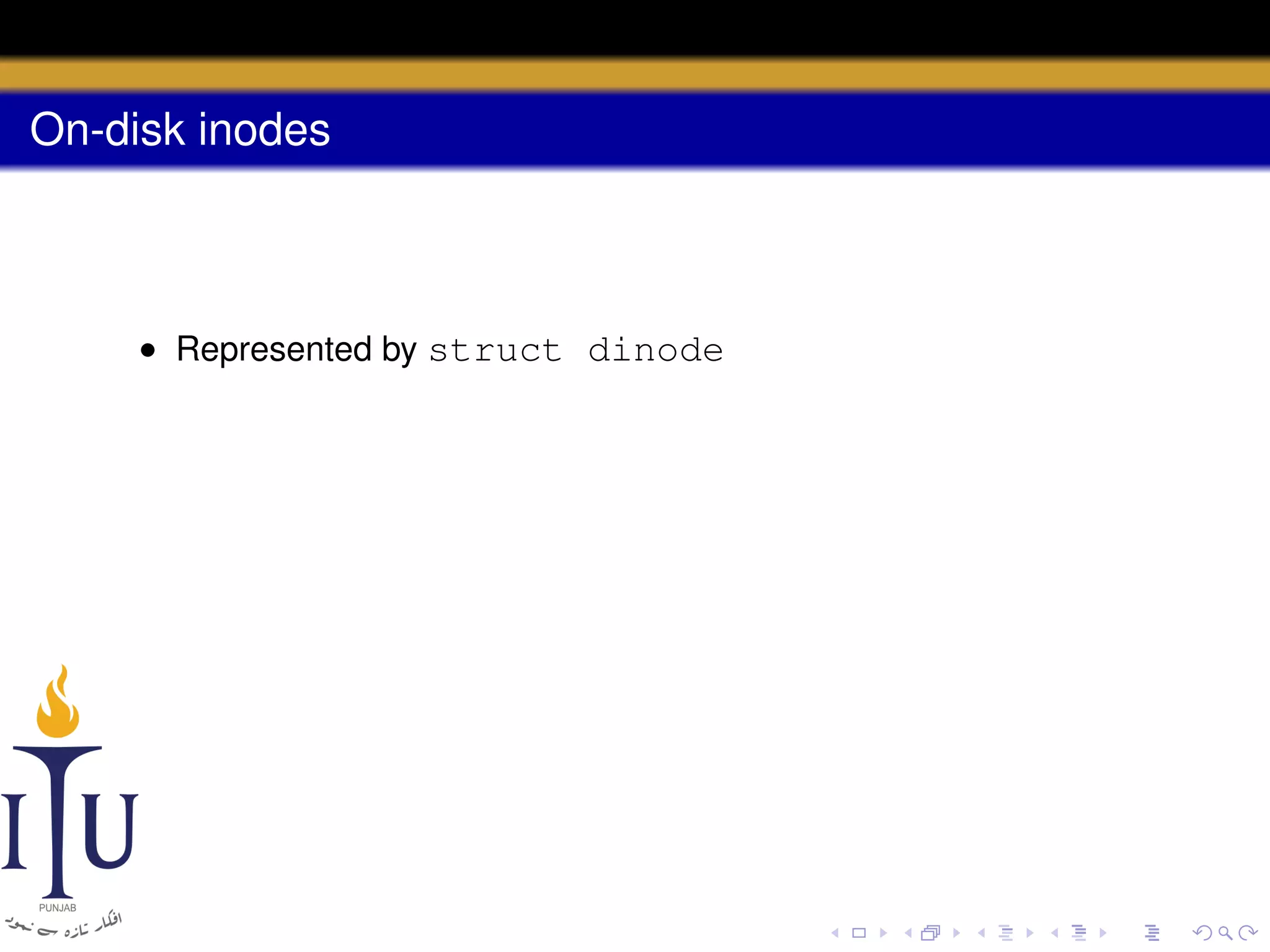





![Code: dinode
struct dinode {
short type; // File type
short major; // Major device number (T_DEV only)
short minor; // Minor device number (T_DEV only)
short nlink; // Number of links to inode in file s
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEV 3 // Device](https://image.slidesharecdn.com/document-140110160941-phpapp01/75/AOS-Lab-10-File-system-Inodes-and-beyond-29-2048.jpg)
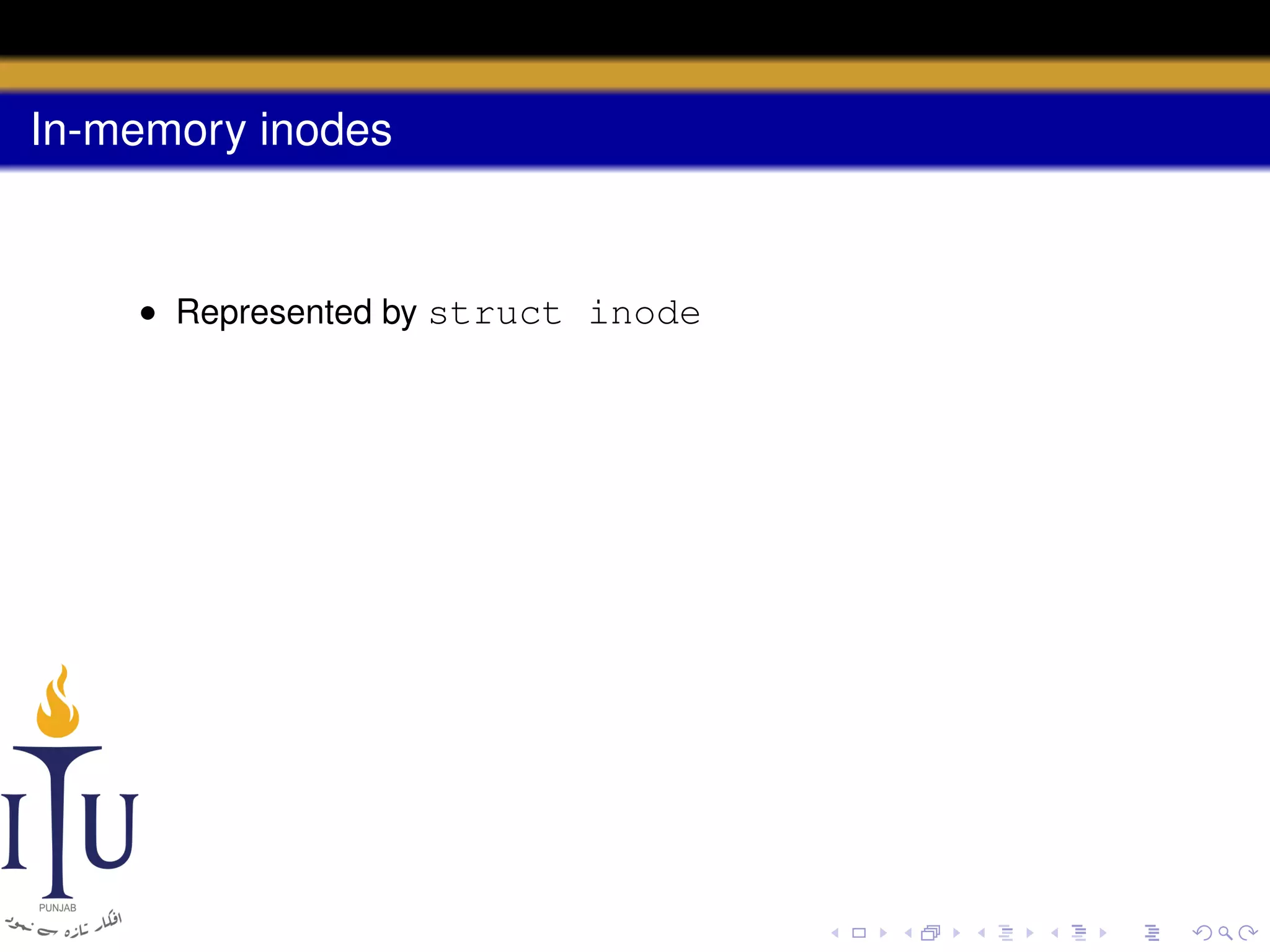





![Code: inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
int flags; // I_BUSY, I_VALID
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+1];
};
#define I_BUSY 0x1
#define I_VALID 0x2](https://image.slidesharecdn.com/document-140110160941-phpapp01/75/AOS-Lab-10-File-system-Inodes-and-beyond-36-2048.jpg)




















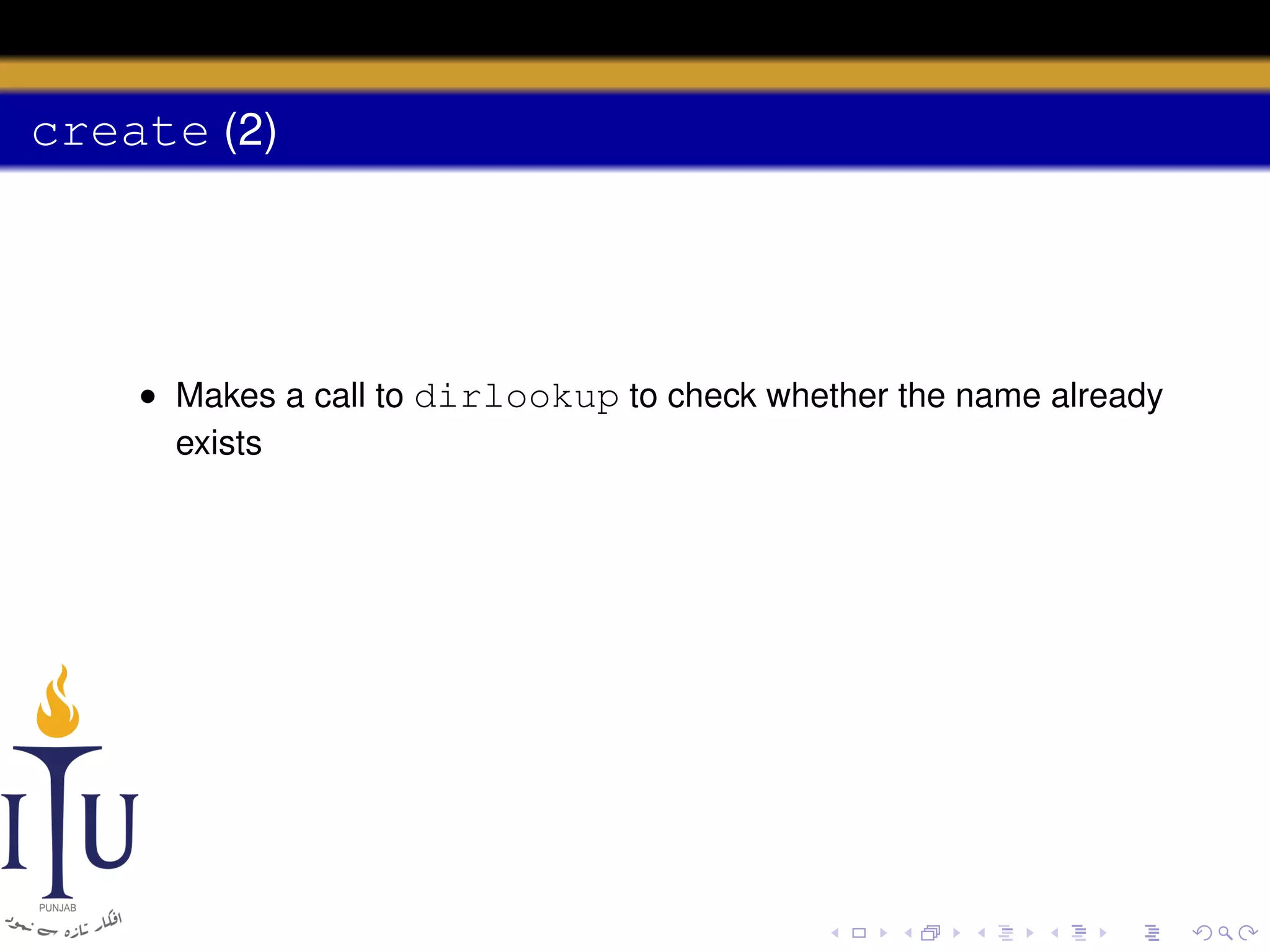
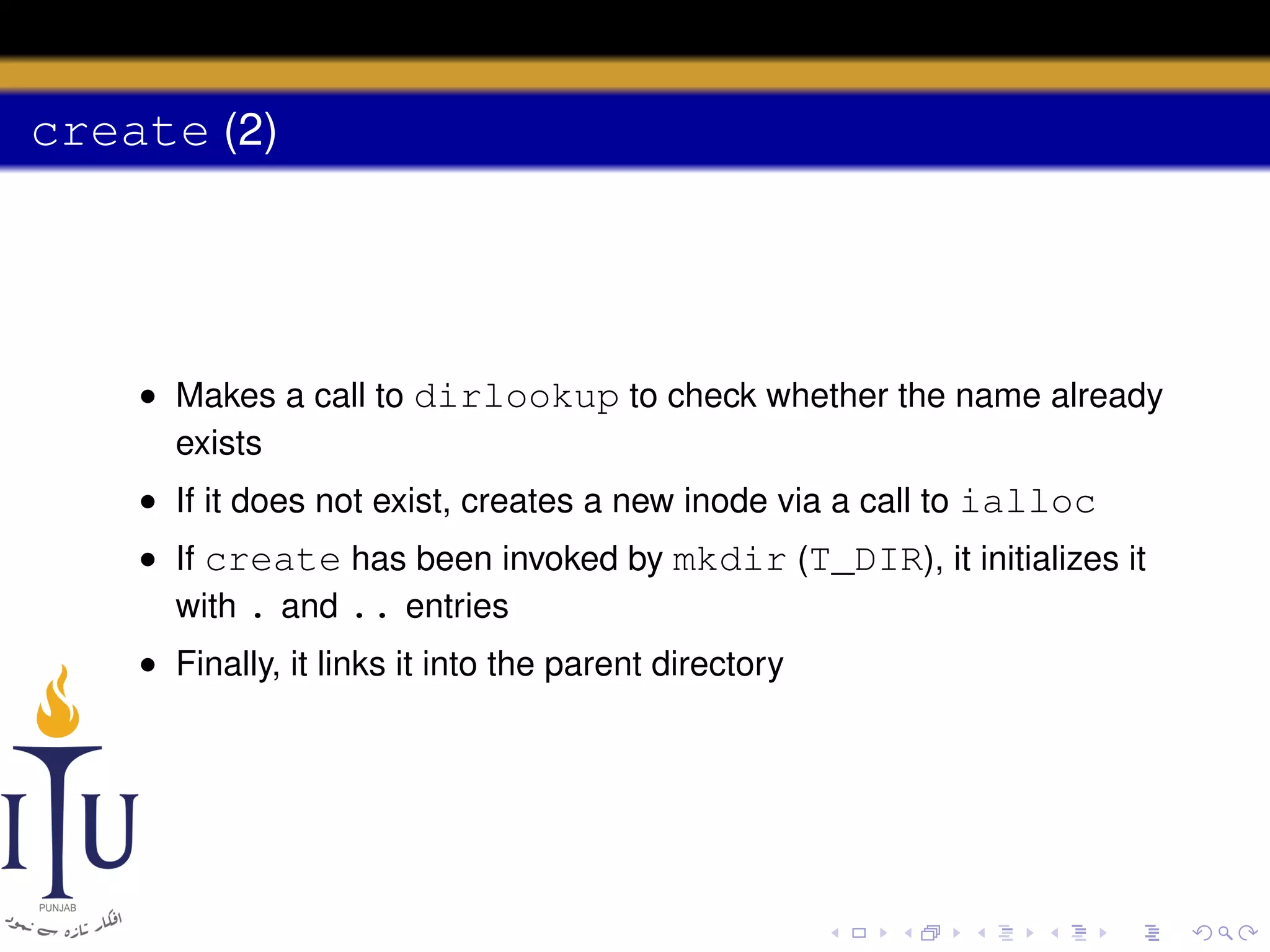
![Directory layer
• A directory is a file with an inode type T_DIR and data in the
form of a sequence of directory entries
• Each entry is a struct dirent
struct dirent {
ushort inum; // free, if zero
char name[DIRSIZ];
};
#define DIRSIZ 14](https://image.slidesharecdn.com/document-140110160941-phpapp01/75/AOS-Lab-10-File-system-Inodes-and-beyond-57-2048.jpg)
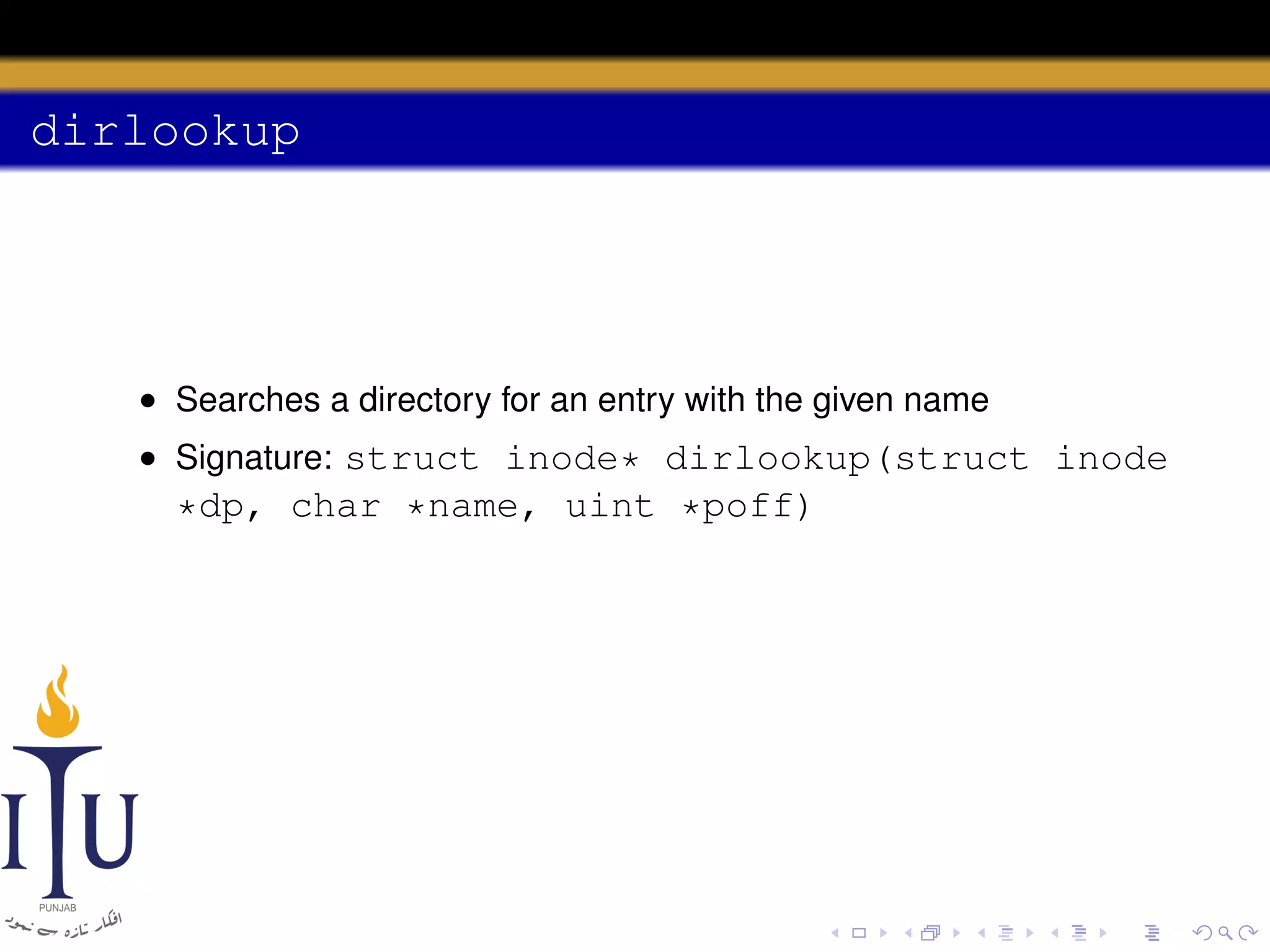















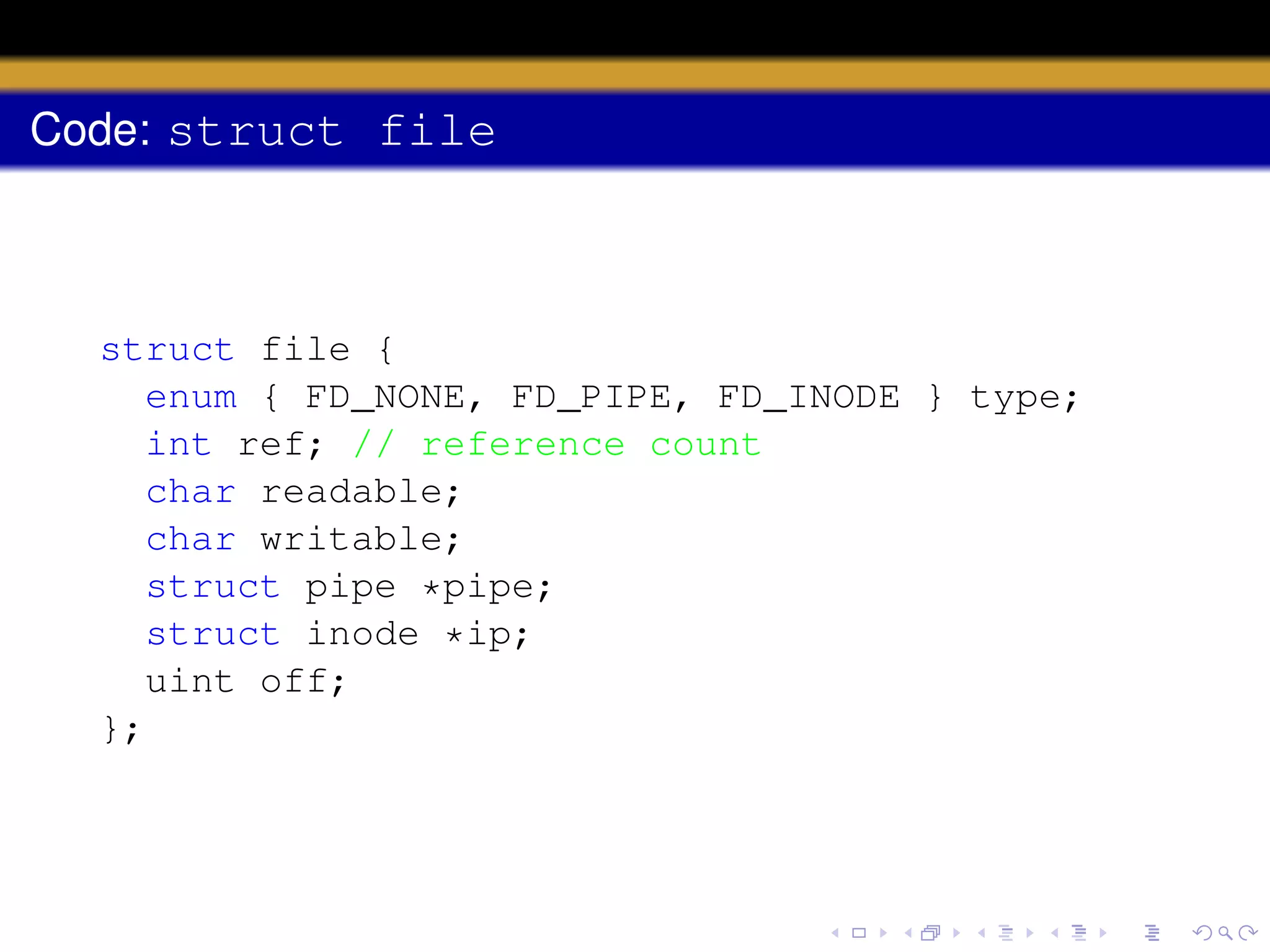



































This document provides a summary of file system concepts in the xv6 operating system, including: 1) Inodes are data structures that represent files and provide metadata and pointers to file data blocks. On-disk inodes are read into memory inodes when files are accessed. 2) Directories are represented by special directory inodes containing directory entries with names and pointers to other inodes. 3) The file system layout divides the disk into sections for the boot sector, superblock, inodes, bitmap, data blocks, and log for atomic transactions.











































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)
















