Downloaded 27 times







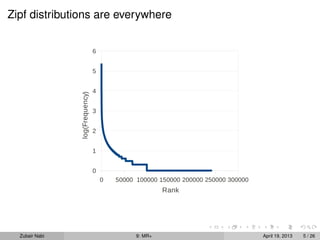









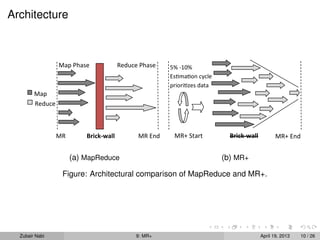


















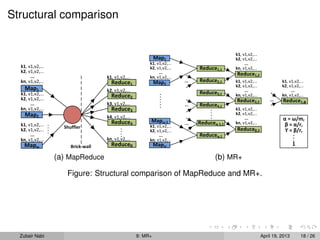


























The document describes MR+, an approach that modifies the MapReduce framework to allow map and reduce tasks to interleave and iterate over intermediate results. This helps address issues like skew in intermediate data distribution. MR+ maintains the simple MapReduce programming model while enabling architectural flexibility like scheduling reduce tasks after every few map tasks complete and recursively reducing populated keys. It aims to exploit structure in input data, estimate results early, and perform well on commodity clusters.









































































