Downloaded 1,727 times

















![ char cb[40]
This is a "control buffer," or storage for private information, maintained
by each layer for internal use.
struct tcp_skb_cb {
... ... ... _ _u32 seq; /* Starting sequence number */
_ _u32 end_seq; /* SEQ + FIN + SYN + datalen*/
_ _u32 when; /* used to compute rtt's */
_ _u8 flags; /*TCP header flags. */
... ... ...
};](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-27-320.jpg)



![struct net_device{
char name[IFNAMSIZ];
int ifindex;
/* device name hash chain, ex: eth0 */
struct hlist_node name_hlist;
unsigned long mem_end;/* shared mem end */
unsigned long mem_start; /* shared mem start */
unsigned long base_addr; /* device I/O address */
unsigned int irq; /* device IRQ number*/
unsigned char if_port; /* Selectable AUI,TP,..*/
unsigned char dma; /* DMA channel */
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-47-320.jpg)
![struct net_device{
char name[IFNAMSIZ];
int ifindex;
/* device name hash chain, ex: eth0 */
struct hlist_node name_hlist;
unsigned long mem_end; /* shared mem end */
unsigned long mem_start; /* shared mem start */
unsigned long base_addr; /* device I/O address */
unsigned int irq; /* device IRQ number*/
unsigned char if_port; /* Selectable AUI,TP,..*/
unsigned char dma; /* DMA channel */
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-48-320.jpg)
![struct net_device{
char name[IFNAMSIZ];
int ifindex;
/* device name hash chain, ex: eth0 */
struct hlist_node name_hlist;
unsigned long mem_end;/* shared mem end */
unsigned long mem_start; /* shared mem start */
unsigned long base_addr; /* device I/O address */
unsigned int irq; /* device IRQ number*/
unsigned char if_port; /* Selectable AUI,TP,..*/
unsigned char dma; /* DMA channel
*/](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-49-320.jpg)
![struct net_device{
char name[IFNAMSIZ];
/* device name hash chain, ex: eth0 */
struct hlist_node name_hlist;
unsigned long mem_end;/* shared mem end */
unsigned long mem_start; /* shared mem start */
unsigned long base_addr; /* device I/O address */
unsigned int irq; /* device IRQ number*/
unsigned char if_port; /* Selectable AUI,TP,..*/
unsigned char dma; /* DMA channel */
unsigned short flags; /* interface flags (a la BSD) */
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-50-320.jpg)
![struct net_device{
char name[IFNAMSIZ];
/* device name hash chain, ex: eth0 */
struct hlist_node name_hlist;
unsigned long mem_end;/* shared mem end */
unsigned long mem_start; /* shared mem start */
unsigned long base_addr; /* device I/O address */
unsigned int irq; /* device IRQ number*/
unsigned char if_port; /* Selectable AUI,TP,..*/
unsigned char dma; /* DMA channel */
unsigned short flags; /* interface flags (a la BSD)*/
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-51-320.jpg)
![struct net_device{
char name[IFNAMSIZ];
/* device name hash chain, ex: eth0 */
struct hlist_node name_hlist;
unsigned long mem_end;/* shared mem end */
unsigned long mem_start; /* shared mem start */
unsigned long base_addr; /* device I/O address */
unsigned int irq; /* device IRQ number*/
unsigned char if_port; /* Selectable AUI,TP,..*/
unsigned char dma; /* DMA channel */
unsigned short flags; /* interface flags (a la BSD)*/
/* ex : IFF_UP || IFF_RUNNING || IFF_MULTICAST */](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-52-320.jpg)
![struct net_device{
…
unsigned mtu; /* interface MTU value */
unsigned short type; /* interface hardware type */
unsigned short hard_header_len; /* hardware hdr length */
unsigned char dev_addr[MAX_ADDR_LEN];
unsigned char addr_len; /* hardware address length */
unsigned char broadcast[MAX_ADDR_LEN];
unsigned int promiscuity;
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-53-320.jpg)
![struct net_device{
…
unsigned mtu; /* interface MTU value */
unsigned short type; /* interface hardware type*/
unsigned short hard_header_len; /* hardware hdr length */
unsigned char dev_addr[MAX_ADDR_LEN];
unsigned char addr_len; /* hardware address length */
unsigned char broadcast[MAX_ADDR_LEN];
unsigned int promiscuity;
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-54-320.jpg)
![struct net_device{
…
unsigned mtu; /* interface MTU value */
unsigned short type; /* interface hardware type */
unsigned short hard_header_len;/* hardware hdr length */
unsigned char dev_addr[MAX_ADDR_LEN];
unsigned char addr_len; /* hardware address length */
unsigned char broadcast[MAX_ADDR_LEN];
unsigned int promiscuity;
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-55-320.jpg)
![struct net_device{
…
unsigned mtu; /* interface MTU value */
unsigned short type; /* interface hardware type */
unsigned short hard_header_len; /* hardware hdr length */
unsigned char dev_addr[MAX_ADDR_LEN];
unsigned char addr_len; /* hardware address length*/
unsigned char broadcast[MAX_ADDR_LEN];
unsigned int promiscuity;
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-56-320.jpg)
![struct net_device{
…
unsigned mtu; /* interface MTU value */
unsigned short type; /* interface hardware type */
unsigned short hard_header_len; /* hardware hdr length */
unsigned char dev_addr[MAX_ADDR_LEN];
unsigned char addr_len; /* hardware address length */
unsigned char broadcast[MAX_ADDR_LEN];
unsigned int promiscuity;
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-57-320.jpg)
![struct net_device{
…
unsigned mtu; /* interface MTU value */
unsigned short type; /* interface hardware type */
unsigned short hard_header_len; /* hardware hdr length */
unsigned char dev_addr[MAX_ADDR_LEN];
unsigned char addr_len; /* hardware address length */
unsigned char broadcast[MAX_ADDR_LEN];
unsigned int promiscuity;
…](https://image.slidesharecdn.com/linuxtcp-ippresentation-130624073643-phpapp01/85/The-TCP-IP-Stack-in-the-Linux-Kernel-58-320.jpg)
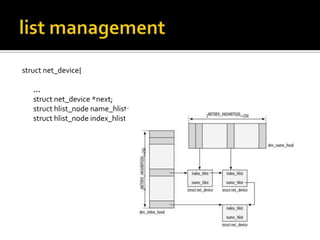

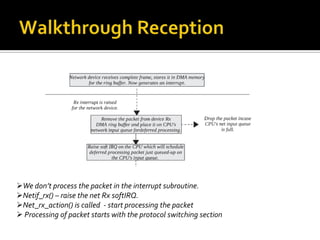
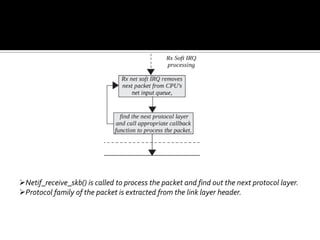
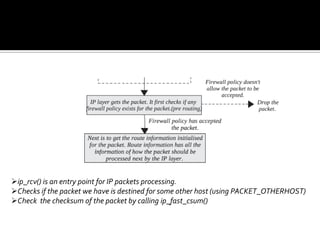

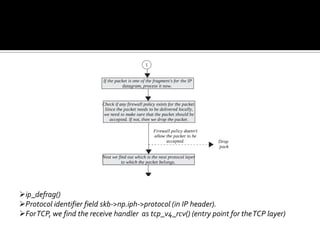
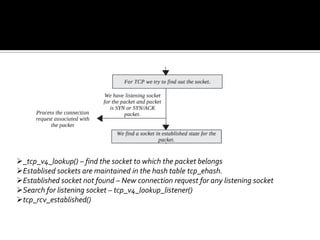
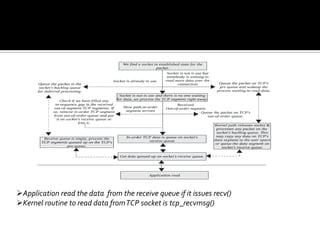


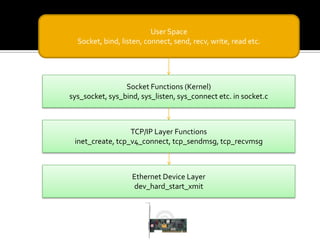
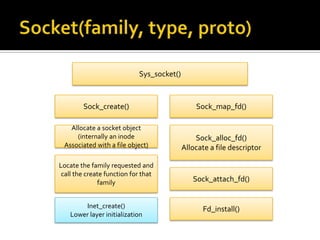
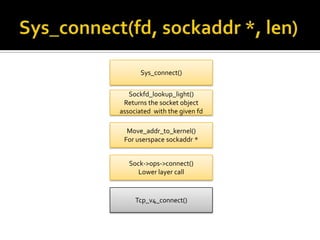
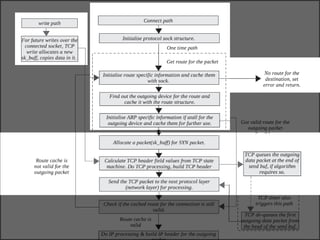
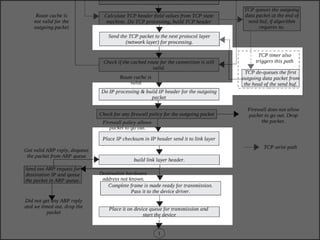
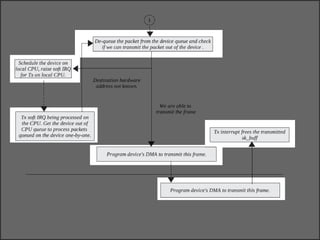
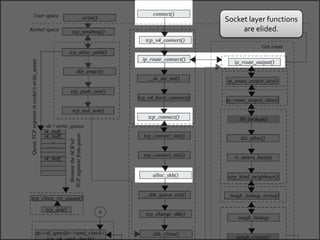
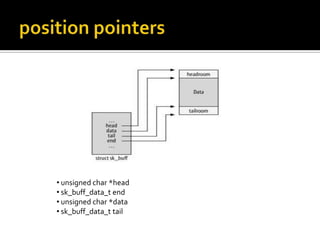
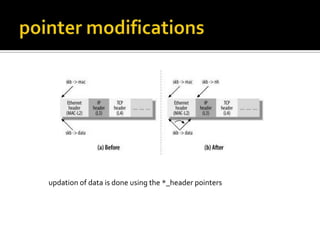
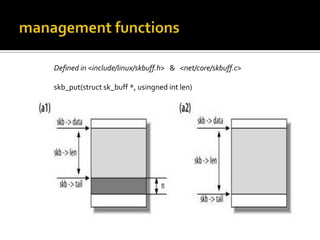
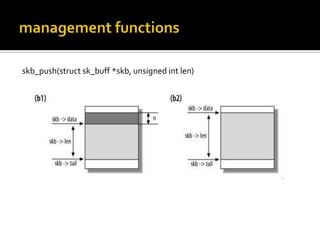
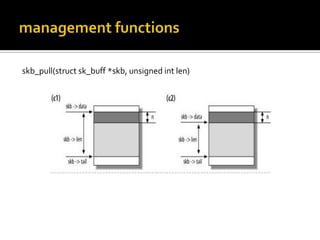
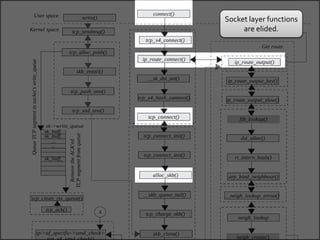
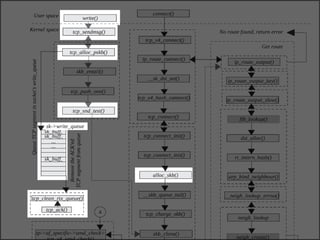
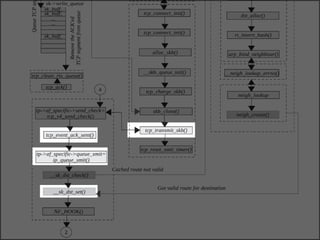
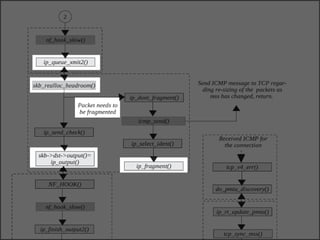
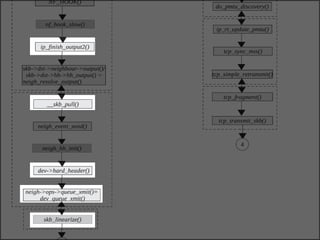
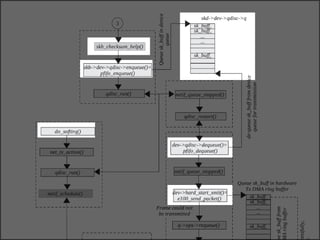
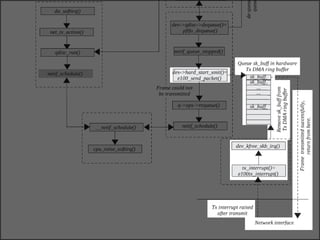
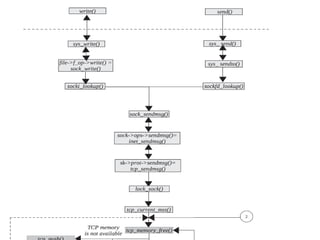
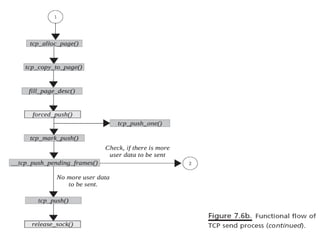
The document discusses various data structures and functions related to network packet processing in the Linux kernel socket layer. It describes the sk_buff structure that is used to pass packets between layers. It also explains the net_device structure that represents a network interface in the kernel. When a packet is received, the interrupt handler will raise a soft IRQ for processing. The packet will then traverse various protocol layers like IP and TCP to be eventually delivered to a socket and read by a userspace application.








































































